Система мониторинга функционирует в пределах своего региона и собирает метрики о работе региона, в котором она развёрнута. Иными словами, каждый регион содержит (при включении соответствующей опции) собственную полноценную систему мониторинга.
При наличии нескольких регионов может возникнуть потребность как в централизованном хранении метрик о работе нескольких регионов, так и в визуализации метрик нескольких регионов на одном дашборде. Для решения данной задачи предусмотрена система централизованного мониторинга. Данная система реализована на базе сервиса VictoriaMetrics, разворачиваемого отдельно от регионов с нагрузками (например, в отдельном регионе). Системы мониторинга каждого региона самостоятельно реплицируют собранные метрики в централизованную систему.
На данный момент реализована репликация всех метрик.
Для развёртывания системы централизованного мониторинга выполните следующие действия:
Создайте отдельный пустой регион.
В конфигурационный файл региона /globals.d/REGION.yml добавьте переменную enable_victoriametrics со значением yes, переменную enable_prometheus_server со значением no и переменную enable_grafana со значением yes. Пример конфигурации региона централизованного мониторинга с отключёнными сервисами OpenStack:
Создайте новый пайплайн: Build > Pipelines > New Pipeline.
В переменной KOLLA_ARGS укажите значение -tprometheus,victoriametrics,grafana. При необходимости можно отключить неиспользуемые сервисы OpenStack.
Запустите пайплайн, нажав кнопку New pipeline.
После завершения пайплайна должны быть развёрнуты и предварительно настроены VictoriaMetrics, набор экспортёров, Alertmanager, Grafana.
Примечание
При включении компонента Grafana также включите компонент MariaDB, т.к. Grafana использует базу данных для хранения своей конфигурации.
Включение репликации метрик в систему централизованного мониторинга¶
Для каждого региона включите репликацию собираемых метрик в систему централизованного мониторинга. Для этого выполните следующие действия:
Откройте веб-интерфейс развёрнутого GitLab.
Перейдите в репозиторий региона project_k / deployments / <имя региона>.
В конфигурационный файл конкретного региона /globals.d/region.yml добавьте переменную enable_central_monitoring со значением yes, а также переменную central_monitoring_url, в значении которой укажите URL компонента vminsert централизованного мониторинга.
Если подключение к централизованному мониторингу требует авторизации, то дополнительно укажите имя пользователя в переменной central_monitoring_basic_auth_user. Пароль для учётной записи введите в Vault в качестве значения ключа central_monitoring_basic_auth_password в файле passwords_yml.
Создайте новый пайплайн: Build > Pipelines > New Pipeline.
В открывшемся окне укажите параметр KOLLA_ARGS со значением -tprometheus или -tvictoriametrics в зависимости от того, какой компонент используется в качестве сервиса сбора и хранения метрик данного региона.
В Alertmanager не предусмотрено функционала по хранению истории алертов и смены их статусов. Alertmanager отображает только активные в данный момент алерты и заглушки алертов. Ведение истории необходимо реализовывать сторонними сервисами и интеграциями.
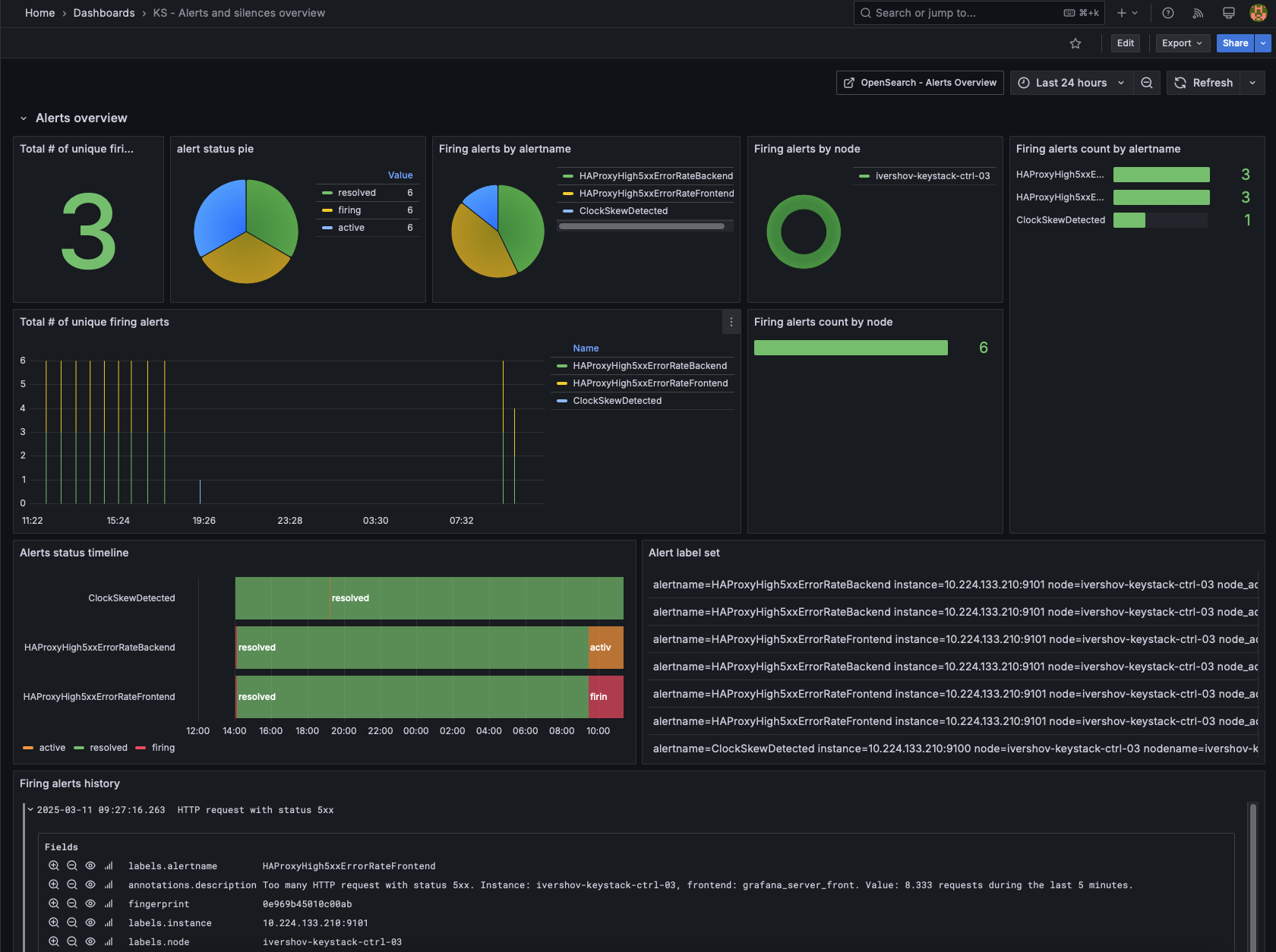
В качестве базы данных хранения истории алертов используется OpenSearch. Подробнее описано в разделе OpenSearch — Логирование и поиск.
Передача алертов со статусами firing и resolving реализована через webhook, который принимает алерты от Alertmanager и пересылает их в OpenSearch.
Передача алертов со статусами active и inhibited реализована через веб-сервис, который периодически обращается к API Alertmanager, получает список алертов и пересылает их в OpenSearch.
Передача заглушек алертов реализована через веб-сервис, который периодически обращается к API Alertmanager, получает список заглушек и пересылает их в OpenSearch.
Хранение алертов и заглушек реализовано в разных индексах, поскольку набор полей для них существенно различается:
Для хранения алертов используется индекс alerts.alertmanager-%Y.%m.%d.
Для хранения заглушек используется индекс silences.alertmanager-%Y.%m.%d.
Примечание
Передача алертов со статусом pending на данный момент не реализована.
Реализация webhook и веб-сервисов выполнена с помощью сервиса Vector.
Контейнеры с vector размещаются на Control-узлах и работают независимо друг от друга.
Для включения функционала по сохранению истории алертов выполните следующие действия:
Откройте веб-интерфейс развёрнутого GitLab.
Перейдите в репозиторий региона project_k / deployments / <имя региона>.
В конфигурационный файл региона /globals.d/REGION.yml добавьте переменную enable_alerts_state_history со значением yes.
Создайте новый пайплайн: Build > Pipelines > New Pipeline.
В открывшемся окне укажите параметр KOLLA_ARGS со значением -topensearch,vector,grafana,prometheus,victoriametrics.
Запустите пайплайн, нажав кнопку New pipeline.
Дождитесь успешного завершения пайплайна. В конфигурацию Alertmanager добавится дополнительный приёмник алертов (receiver) и соответствующий маршрут, необходимые для передачи алертов из Alertmanager в Vector.
Важно
Если в регионе переопределена конфигурация Alertmanager с помощью конфигурационного файла /config/prometheus/prometheus-alertmanager.yml, то в конфигурационный файл в соответствующие секции добавите вручную приёмник алертов и маршрут, после чего запустите пайплайн, где в переменной KOLLA_ARGS укажите значение -tprometheus.
В качестве уникального идентификатора алерта в OpenSearch используется md5 хэш сумма от перечня меток алерта, времени его создания и статуса алерта. В этом случае OpenSearch перезаписывает ранее полученный алерт с тем же идентификатором, тем самым обеспечивая дедупликацию алертов.
В качестве timestamp для алертов со статусом firing используется значение поля startsAt, а для алертов со статусом resolving используется значение поля endsAt.
Визуализация аналитики по алертам реализована средствами OpenSearch dashboards.
Alertmanager позволяет передавать алерты в сторонние системы, для многих из которых в Alertmanager имеется встроенная интеграция. Полный перечень поддерживаемых систем доступен в документации Prometheus.
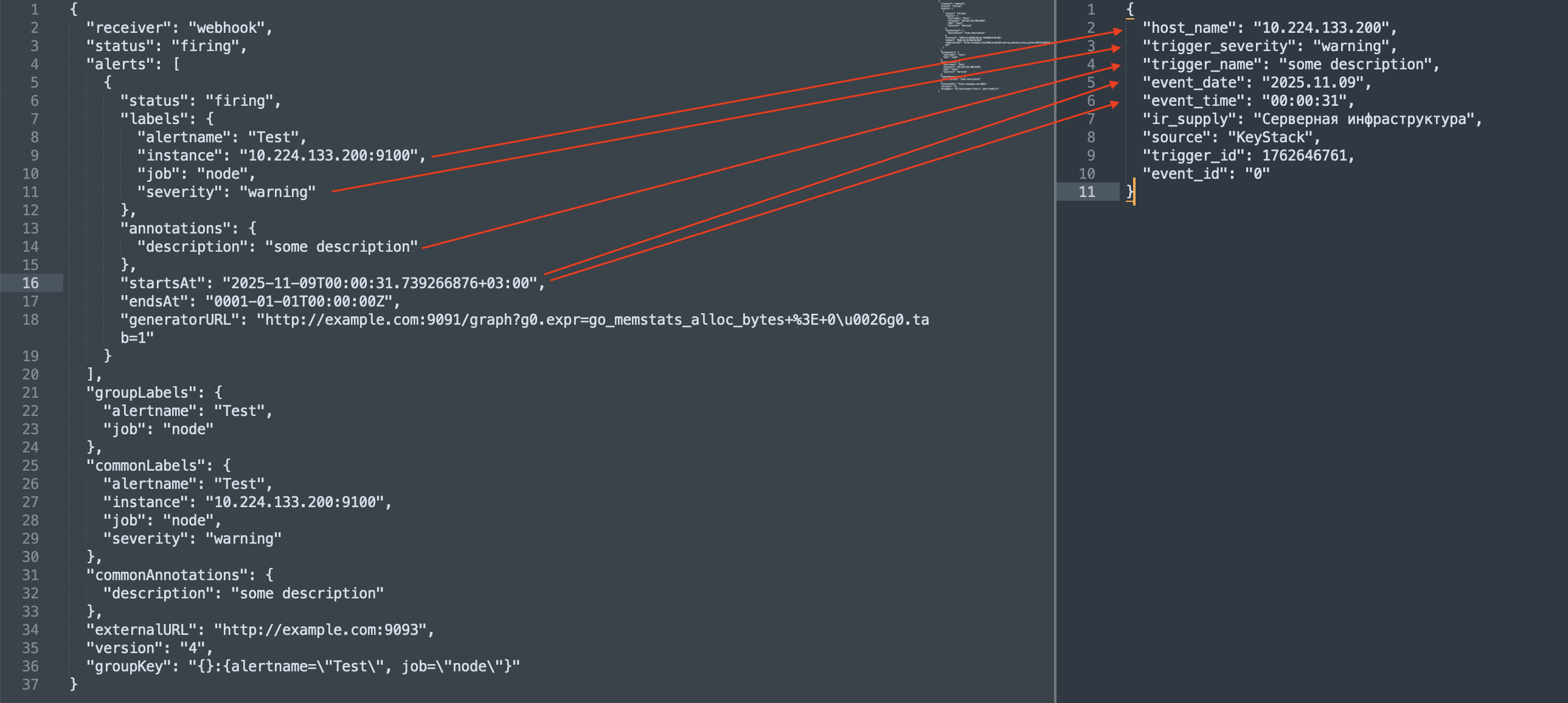
При необходимости пересылать алерты в сторонние системы, для которых в Alertmanager не реализована интеграция, с продуктом поставляется веб-сервис, реализованный с помощью сервиса vector. Данный веб-сервис должен быть добавлен в конфигурации Alertmanager как универсальный приёмник (webhook). При наличии в конфигурации Alertmanager такого приёмника Alertmanager направит на указанный эндпоинт HTTP POST-запрос в формате JSON со следующим содержимым:
{"version":"4","groupKey":<string>,// key identifying the group of alerts (e.g. to deduplicate)"truncatedAlerts":<int>,// how many alerts have been truncated due to "max_alerts""status":"<resolved|firing>","receiver":<string>,"groupLabels":<object>,"commonLabels":<object>,"commonAnnotations":<object>,"externalURL":<string>,// backlink to the Alertmanager."alerts":[{"status":"<resolved|firing>","labels":<object>,"annotations":<object>,"startsAt":"<rfc3339>","endsAt":"<rfc3339>","generatorURL":<string>,// identifies the entity that caused the alert"fingerprint":<string>// fingerprint to identify the alert},...]}
Описание структуры алерта в формате JSON доступно по ссылке.
С помощью Vector remap language алерт преобразовывается в формат целевой сторонней системы.
Для включения передачи алертов в стороннюю систему выполните следующие действия:
Включите веб-сервис (webhook), принимающий алерты от Alertmanager:
В конфигурационный файл региона /globals.d/REGION.yml добавьте переменную enable_vector_webhook_alertmanager со значением yes.
Создайте новый пайплайн: Build > Pipelines > New Pipeline.
В переменной KOLLA_ARGS укажите значение -tvector.
Запустите пайплайн, нажав кнопку New pipeline.
После успешного завершения пайплайна на контроллерах будут запущены контейнеры с сервисом Vector, а в конфигурацию Alertmanager добавится дополнительный приёмник алертов (receiver) и соответствующий маршрут, необходимые для передачи алертов из Alertmanager в Vector.
Важно
Если в регионе переопределена конфигурация Alertmanager с помощью конфигурационного файла /config/prometheus/prometheus-alertmanager.yml, то в конфигурационный файл в соответствующие секции вручную добавьте приёмник алертов и маршрут, после чего запустите пайплайн, где в переменной KOLLA_ARGS укажите значение -tprometheus.
Сформируйте конфигурационный файл сервиса Vector с необходимыми преобразованиями:
Конфигурационный файл с описанием преобразования (трансформации) разместите в GitLab в репозитории региона в каталоге /config/vector/transforms/ в файле с расширением yaml.
В качестве источника данных в секции inputs укажите alertmanager_webhook.
Пример конфигурационного файла и соответствующая визуализация представлены ниже:
Сформируйте конфигурационный файл сервиса Vector с целевым приёмником данных:
Конфигурационный файл с описанием целевого приёмника разместите в GitLab в репозитории региона в каталоге /config/vector/sinks/ в файле с расширением yaml.
В качестве источника данных в секции inputs укажите имя файла без расширения, в котором были описаны преобразования на предыдущем шаге.
Пример конфигурации с хранением пароля в vault и c mTLS-взаимодействием представлен ниже:
Мониторинг определённых событий/ошибок, зафиксированных в журналах (лог-файлах) реализован с помощью сервиса fluentd. Сервис fluentd обеспечивает сбор и предварительную обработку журналов (лог-файлов) и последующую их отправку для длительного хранения и аналитики в сервис OpenSearch. Также сервис fluentd позволяет создавать метрики о своей работе в формате Prometheus.
Список служб подсистем и соответствующие им лог-файлы представлены в разделе:
Копия событий, обработанных средствами fluentd, перед тем как направиться в сервис OpenSearch, с помощью плагина relabel направляется в отдельную очередь обработки. В этой очереди с помощью плагина rewrite_tag_filter происходит сравнение записи в журнале с заданными регулярными выражениями. По результатам сравнения событию присваивается определённый тег. Далее, в соответствии с присвоенным тегом, с помощью плагинов parser и prometheus, происходит увеличение значения метрики, связанной с конкретным событием.
Для включения механизма направления копии событий в отдельную очередь выполните следующие действия:
Скопируйте шаблон /fluentd/output/03-opensearch.conf.j2 с тем же именем, но без расширения .j2 в конфигурацию региона в /config/fluentd/output/03-opensearch.conf
Добавьте дополнительное место хранения с помощью следующей секции:
<store>@typerelabel
@label@prometheus
</store>
Добавьте в конфигурацию региона файл с описанием маршрутизации в /config/fluentd/output, например /config/fluentd/output/04-prometheus.conf.
Ниже приведён пример конфигурации, когда создаётся:
метрика с типом Counter и названием fluentd_input_amqp_errors_records_total при появлении в журналах записей вида AMQPserveron<ip_address>:<port>isunreachable,
метрика с типом Counter и названием fluentd_input_VM_unexpected_shutdown_records_total при появлении в журналах записей вида During_sync_instance_power_statetheDBpower_state(1)doesnotmatchthevm_power_statefromthehypervisor(4).Updatingpower_stateintheDBtomatchthehypervisor.
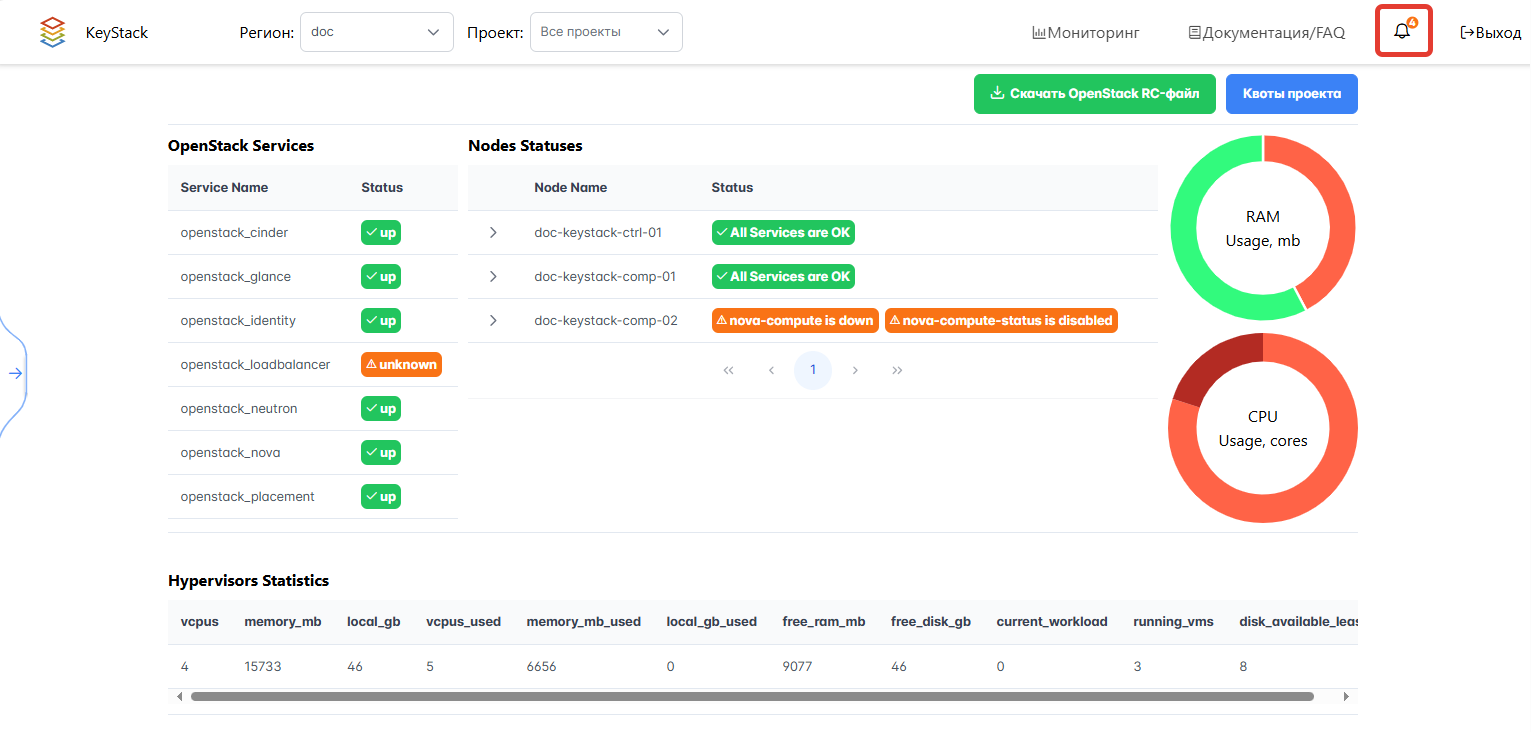
На Портале администратора предусмотрено отображение активных уведомлений из Alertmanager уровня warning и critical.
Для просмотра списка уведомлений, выполните следующие действия:
В верхней панели Портала администратора нажмите на кнопку Alerts. На кнопке отображается количество непрочитанных уведомлений.
Кнопка Alerts в верхней панели Портала администратора¶
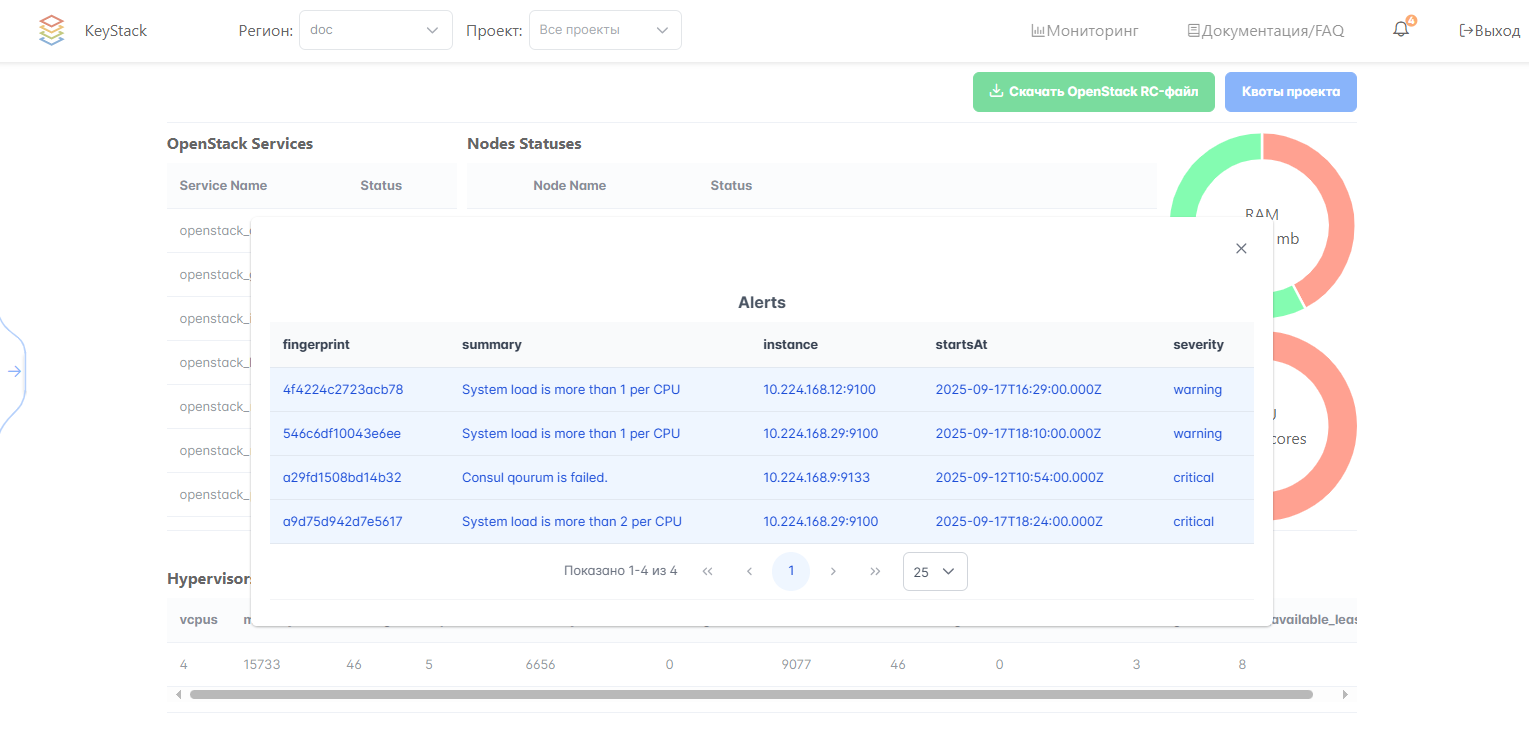
В открывшемся окне Alerts отобразится список активных уведомлений из Alertmanager уровня warning и critical.
Список уведомлений из Alertmanager на Портале администратора¶
Для просмотра более детальной информации об уведомлении нажмите на строку уведомления. В открывшемся окне отобразится краткое описание, даты, статус и прочая информация об уведомлении.
Детальная информация об уведомлении из Alertmanager на Портале администратора¶
После закрытия окна Alerts со списком уведомлений, все прочитанные уведомления будут скрыты из списка.
Для отслеживания состояния blackholing, когда на инфраструктуре происходит потеря пакетов между узлами платформы KeyStack, реализовано наблюдение за метриками сервиса Consul и наблюдение за доступностью эндпоинта сервиса nova-api на управляющих узлах со стороны остальных узлов платформы.
В случаях нарушения сетевой связности между узлами кластера Consul (располагающихся на управляющих узлах), сервис Consul переводит недоступный узел в состояние unhealthy, а соответствующий ему сервис переводит в состояние warning. При этом формируются алерты ConsulHealthNodeStatus и ConsulHealthServiceStatus.
В случаях нарушения сетевой связности от вычислительных узлов к управляющим узлам или между управляющими узлами становится невозможным подключение к эндпоинту сервиса nova-api, который располагается на управляющих узлах. В этом случае формируется алерт BlackboxProbeHttpNovaApi. При этом на панели Certificate & Connection Monitoring дашборда KS - SSL Certificate Monitor можно видеть результаты проверок подключения к nova-api.
Описанные выше алерты в первую очередь могут говорить о нарушении сетевой связности между отдельными узлами платформы. Как следствие нарушения нормального функционирования платформы могут формироваться и другие алерты, связанные с сервисами Nova, Neutron, Cinder, RabbitMQ, HAproxy.
Просмотр состояния сервисов мониторинга платформы¶
Просмотр состояния контейнеров OpenSearch (выполняется на управляющих узлах):
dockerps-fname=opensearch
Просмотр состояния контейнера Prometheus (выполняется на управляющих узлах):
dockerps-fname=prometheus
Просмотр состояния Grafana (выполняется на управляющих узлах):
dockerps-fname=grafana
Просмотр состояния fluentd (на любом сервере):
dockerps-fname=fluentd
Просмотр состояния VictoriaMetrics (выполняется на управляющих узлах):