Перед тем как приступать к обновлению, необходимо проверить состояние облачной инфраструктуры. Эта проверка необходима для минимизации рисков и поддержания стабильности системы. Проверка работоспособности региона позволяет убедиться, что виртуальные машины создаются и доступны по сети, что подтверждает работоспособность цепочки сервисов (MariaDB, HAProxy, Cinder, Nova, Neutron, Glance).
Подключитесь к интерфейсу OpenStack CLI.
Проверьте сетевую доступность всех узлов облака с помощью команды ping.
Выполните команду openstackcomputeservicelist для проверки состояния вычислительных сервисов. Убедитесь, что все сервисы находятся в состоянии up.
Выполните команду openstackvolumeservicelist для проверки состояния службы томов. Убедитесь, что все сервисы находятся в состоянии up.
Выполните команду openstackserverlist для проверки состояния виртуальных машин.
Используя OpenStack CLI, портал самообслуживания Horizon или Портал администратора, создайте несколько ВМ с различными флейворами и выполните их live-миграцию.
При обновлении с версии 2025.1.1 на версию 2025.2.5 необходимо вручную включить компонент hostmgmt-агента. Этот компонент обеспечивает работу страницы Сервисы на Портале администратора. Пайплайн обновления региона обновляет только уже установленные компоненты и не выполняет установку новых, поэтому hostmgmt-агент требует отдельного предварительного развёртывания. Если пропустить описанные ниже шаги, hostmgmt-агент не будет установлен, а страница Сервисы на Портале администратора останется недоступной.
Выполните следующие действия после обновления LCM и перед запуском пайплайна обновления региона.
Для развёртывания hostmgmt-агента выполните следующие действия:
Зайдите в веб-интерфейс GitLab.
Перейдите в репозиторий вашего региона project_k / deployments / <имя региона>.
Создайте новый пайплайн: Build > Pipelines > New pipeline.
В переменной KOLLA_ARGS укажите значение:
-t hostmgmt,rabbitmq,common,adminui
Запустите пайплайн, нажав кнопку New pipeline.
Дождитесь завершения задач на этапе setup.
Запустите задачу deploy на этапе deploy и дождитесь её завершения.
Предупреждение
Не используйте аргумент -thostmgmt отдельно. При развёртывании только с этим тегом hostmgmt-агент не запустится на узлах, так как виртуальный хост RabbitMQ для hostmgmt не будет создан. В логах это проявляется ошибкой:
amqp.exceptions.NotAllowed: Connection.open: (530) NOT_ALLOWED - vhost hostmgmt not found
Для корректной установки укажите полный набор тегов: hostmgmt,rabbitmq,common,adminui.
Устранение ошибки inventory на Портале администратора¶
Если после развёртывания на странице Сервисы или Обновление региона на Портале администратора отображается ошибка с кодом 400 и текстом «File was not found at the address inventory inventory-ci», закомментируйте в файле region.yaml параметр adminui_inventory_path:
Запущенный сервис Prometheus Alertmanager заранее создаёт каталог данных Prometheus, что может приводить к ошибке переноса данных при выполнении пайплайна обновления региона на Control-узлах. Поэтому перед обновлением необходимо остановить сервис Prometheus Alertmanager, а также удалить автоматически созданную директорию /var/lib/docker/volumes/prometheus/_data и всё её содержимое. Для этого перед запуском пайплайна обновления выполните следующие действия для каждого Control-узла по отдельности:
Зайдите на Control-узел по SSH и выполните команду:
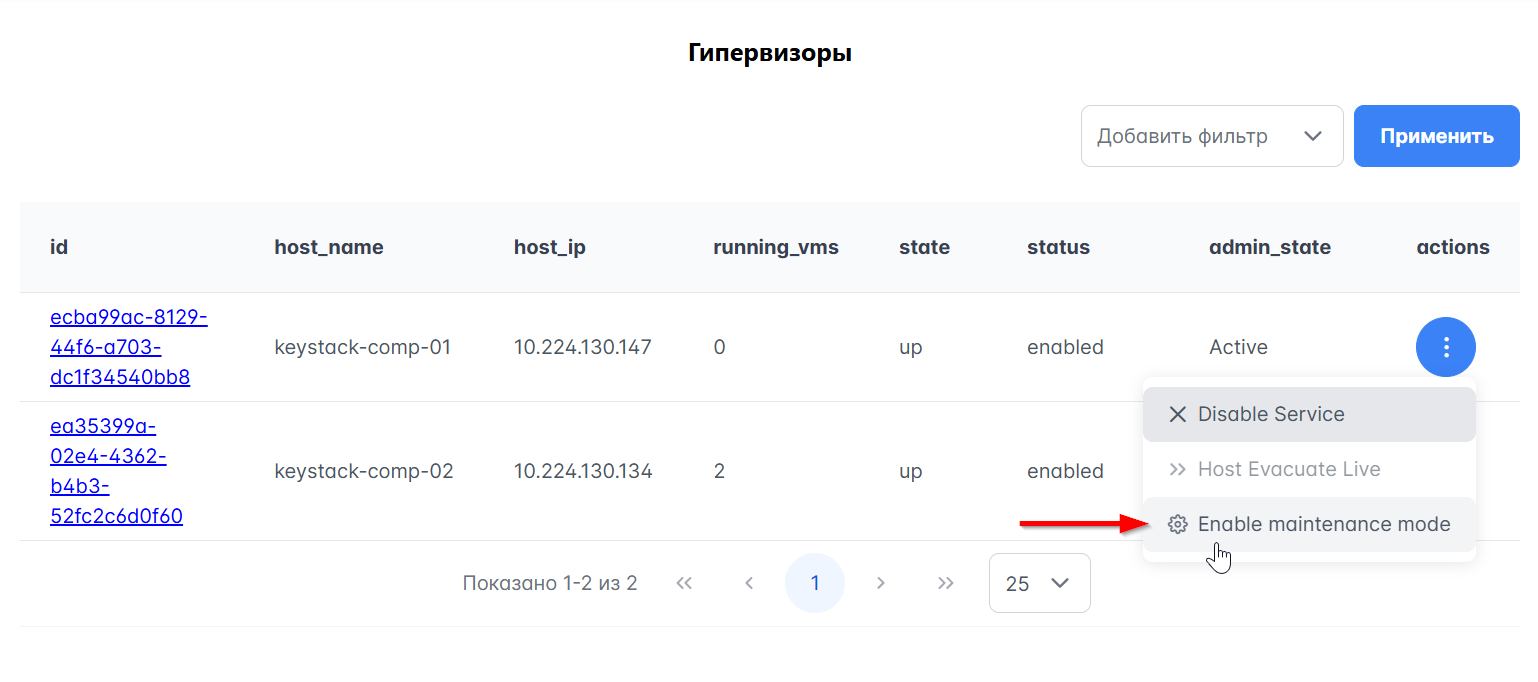
Перед выполнением обновления Compute-узлов их необходимо освободить от виртуальных машин. Это можно сделать путём перевода одного или нескольких узлов в режим обслуживания. При освобождении виртуальные машины будут мигрированы на другие узлы. Для перевода узлов в режим обслуживания выполните следующие шаги:
Зайдите в Портал администратора.
Перейдите в раздел Вычислительные ресурсы > Гипервизоры.
Выберите в выпадающем меню столбца actionsEnable maintenance mode для нужного гипервизора и подтвердите его перевод в режим обслуживания.