VMHA — Высокая доступность ВМ¶
KeyStack VMHA (virtual machine high availability, отказоустойчивость ВМ или буквально высокая доступность ВМ) — сервис, который обеспечивает непрерывную работу виртуальных машин (ВМ) в облаке KeyStack. Основа механизма VMHA — процесс эвакуации рабочих ВМ из отказавших узлов на рабочие.
Сервис VMHA включен в базовую установку KeyStack как компонент системы, поэтому его не придётся устанавливать вручную. Для VMHA необходима активация компонента и дальнейшая конфигурация в зависимости от требований.
Архитектура HA¶
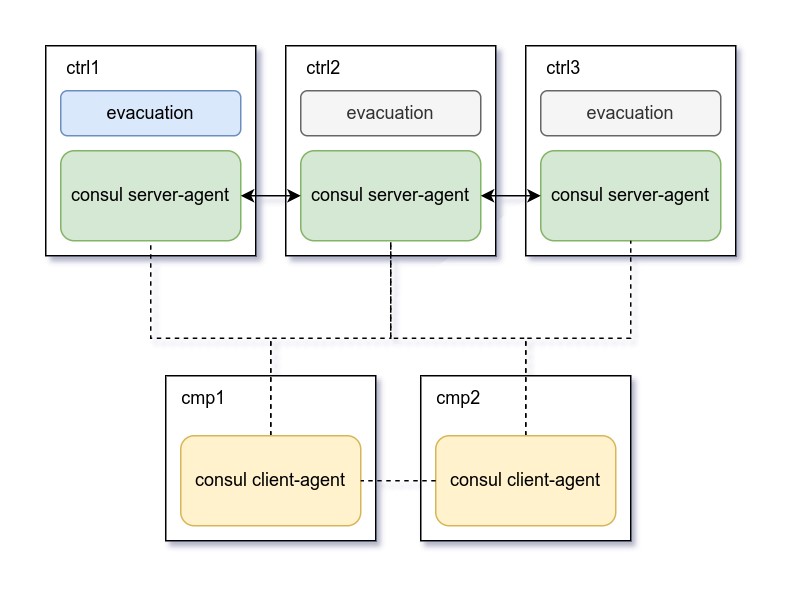
Компонент High Availability реализован на базе программного продукта Consul HashiCorp (распространяемого по лицензии MPL 2.0). За работу VMHA отвечает модуль consul и исполняемый модуль auto_evacuator в его составе.
Для работы вычислительных ресурсов в режиме высокой доступности регион разворачивается со следующими компонентами:
на Control-узлах: серверные агенты consul server-agent, образуют RAFT-кластер;
на Compute-узлах: клиентские агенты consul client-agent, образуют SERF-кластер.
Один из серверных агентов на узлах-контроллерах выступает в роли лидера управляющего кластера, и он лидирует в момент эвакуации виртуальных машин с проблемного вычислительного узла. Общение между серверными и клиентскими агентами осуществляется по принципу «все со всеми» раз в десять секунд с использованием группы протоколов Gossip по портам TCP/UDP 8302.
Архитектура компонента VMHA¶
Автоматическая эвакуация виртуальных машин¶
Компонент VMHA отслеживает работоспособность агентов и обнаруживает такие отказы инфраструктуры, как:
аварийная перезагрузка или отключение гипервизора по питанию;
аварийная остановка ОС (kernel panic) на гипервизоре;
потеря сетевой связности (не обязательно прямой) гипервизора с Control-узлами.
Также VMHA может отслеживать состояние бондов и на основании полученных данных принимать решение об эвакуации.
Критерием отказа с точки зрения VMHA является выполнение одного из следующих условий:
Сбой consul-агента и сервиса nova-compute. Кластер теряет consul-агента на Compute-узле, при этом сервис nova-compute находится в статусе
status: enabledи в состоянииstate: down.Сбой bond-интерфейса. Происходит отказ или отключение сетевого интерфейса, указанного на этапе конфигурации как критический для нагрузки (подробнее см. bond-state-monitoring).
Сбой HBA. Происходит отказ адаптера HBA (Host Bus Adapter), который используется для подключения к системе хранения данных.
Примечание
Механизмы автоэвакуации не срабатывают при потере более двух Compute-узлов одновременно (или иного количества, указанного в параметрах). В этом случае предполагается, что возможна массовая авария оборудования.
Действия в случае отказа узла¶
VMHA проверяет состояние сервисов на Compute-узлах с определённым интервалом. Интервал определяется параметром
consul_intervalв секундах. При совпадении критериев, перечисленных выше, consul детектирует отказ узла.VMHA выполняет фенсинг отказавшего узла. Фенсинг — механизм исключения неисправного узла из кластера, чтобы на этом узле больше не размещались виртуальные машины.
В зависимости от значения параметра
fencingдалее возможны следующие варианты:ceph(true/false) — занесение в чёрный список отказавшего узла из кластера Ceph, этот параметр игнорируется при выключенном Ceph;nova(true/false) — исключение отказавшего узла из кластера Nova (nova service disable);bmc(true/false) — выключение узла через IPMI/Redfish.
В случае успешного выполнения фенсинга VMHA присваивает Compute-узлу статус FENCED.
Следующим этапом происходит эвакуация виртуальных машин:
При эвакуации каждой виртуальной машины VMHA формирует сообщение в систему мониторинга для дальнейшего уведомления администратора о запуске процесса эвакуации.
При завершении эвакуации каждой виртуальной машины VMHA направляет сообщение в систему мониторинга об успешном завершении процесса для дальнейшего уведомления администратора.
В случае успешной эвакуации всех ВМ узел переводится в статус Maintenance mode.
Последовательность действий при выключении сбойного узла:
Производится попытка «мягкого» выключения (shutdown) через интерфейс IPMI/Redfish.
Спустя
power_check_timeoutсекунд проверяется завершённость операции выключения.Если сервер не выключился, производится попытка «жёсткого» выключения (power off).
Спустя
power_check_timeoutсекунд снова выполняется проверка успешности выключения.При неуспешности выключения генерируется сообщение в систему мониторинга.
Уведомления¶
VMHA автоматически отправляет уведомления в мониторинговые системы Prometheus Alertmanager или Zabbix при возникновении проблем с изоляцией узла из любых вышеперечисленных сервисов, а также при начале эвакуации и при окончании эвакуации. Это позволяет наблюдать за состоянием системы и оперативно реагировать на инциденты.
Настройка и конфигурирование VMHA¶
Параметры вычислительных ресурсов облака¶
Администраторы могут настроить запрет на эвакуацию или порядок эвакуации ВМ для оптимизации работы кластера путём выставления приоритетов в виде метаданных:
evacuate_orderдля ВМ;no_evacuateдля ВМ;no_evacuateдля проекта.
Управление параметрами возможно:
через Портал администратора (AdminUI);
через портал самообслуживания;
через OpenStack CLI.
Пример команды для OpenStack CLI:
$ openstack server set --property "evacuate_order=1" <vm_name_or_id> $ openstack server set --property "no_evacuate=true" <vm_name_or_id> $ openstack project set --property "no_evacuate=true" <project_name_or_id>
Администратор может назначить статус Maintenance mode вычислительным узлам:
через Портал администратора (AdminUI);
через OpenStack CLI.
В случае выхода вычислительного узла из строя и, например, отправки его в ремонт, администратору необходимо установить для этого узла причину отключения disabled_reason, отличную от FENCED:, чтобы узел не попадал под определение Dead compute. Администратор платформы может сделать это через интерфейс командной строки.
Пример команды для OpenStack CLI:
$ openstack compute service set --disable --disable-reason “some reason” host_name nova-compute
Также администратор может отключить изоляцию вычислительного узла из интерфейса портала администратора, выбрав пункт Disable Fence Mode в меню управления гипервизорами, и затем перевести его в режим обслуживания, выбрав пункт Enable maintenance mode.
Параметры конфигурации VMHA¶
VMHA ведёт статистику состояний для каждой зоны доступности отдельно. В эту статистику входят три главных состояния: alive, dead, maintenance mode.
dead_compute_threshold— отвечает за пороговое значение единовременно отказавших вычислительных узлов в зоне доступности, попадающих под определение Dead compute.Если количество отказавших вычислительных узлов превышает значение
dead_compute_threshold, эвакуация ВМ прекращается, а фенсинг узлов не проходит. Узел считается отказавшим (попадающим под определение Dead compute) с момента фиксации отказа и до того момента, как этот статус сменяется на Maintenance mode (ММ). После присвоения статуса MM вычислительные узлы перестают учитываться параметромalive_compute_thresholdи остаются в статусе MM, чтобы с ними можно было выполнять работы по обслуживанию.alive_compute_threshold— отвечает за пороговое значение исправных вычислительных узлов.consul_shared_storage(true/false) — отвечает за наличие хранилища с общим доступом. Значение по умолчанию — true.consul_fencing_nova(true/false) — отвечает за фенсинг для сервиса Nova. Значение по умолчанию — true.consul_fencing_ceph(true/false) — отвечает за фенсинг для сервиса Ceph. Значение по умолчанию — false.consul_fencing_ipmi(true/false) — отвечает за фенсинг для сервиса IPMI. Значение по умолчанию — false.alive_compute_count— регулирует количество активных вычислительных узлов. Значение по умолчанию — 3.dead_compute_count— регулирует количество отказавших вычислительных узлов, подпадающих под определение Dead compute. Значение по умолчанию — 3.enable_interfaces_check— отвечает за мониторинг сетевых интерфейсов. Можно указать типы интерфейсов через запятую:bondдля мониторинга bond-интерфейсов,fibre_channelдля мониторинга HBA (Host Bus Adapter). Значение по умолчанию — пустое (мониторинг отключён).fence_failed_interfaces(true/false) — отвечает за фенсинг вычислительных узлов, на которых обнаружены отказавшие сетевые интерфейсы, при условии, что для параметраenable_interfaces_checkуказаны типы интерфейсов для мониторинга. По умолчаниюfence_failed_interfacesимеет значение false — фенсинг не проводится, а вычислительный узел переходит в статусdisableс префиксомHA:.consul_bond_names— список имён bond-интерфейсов, перечисленных через запятую. Применяется при включении мониторинга bond-интерфейсов.consul_prometheus_request_period— регулирует период запроса для Prometheus. Значение по умолчанию — 120 секунд.consul_prometheus_request_step— регулирует период запроса для Prometheus. Значение по умолчанию — 30 секунд.vm_state_reset_timeout— таймаут сброса состояния ВМ при застрявшей эвакуации. Значение по умолчанию — 90 секунд.В случае если при эвакуации ВМ застревает в состоянии
rebuildболее чем наvm_state_reset_timeoutсекунд, её состояние сбрасывается наactive.
Параметры конфигурации BMC¶
bmc_power_fence_mode— регулирует режим работы сервера после проведения фенсинга. VMHA отправляет соответствующую команду на IPMI-интерфейс узла. После успешного выполнения команды Compute-узел принудительно перезагружается, либо отключается по питанию. Возможные опции:shutdown— завершение работы ОС и выключение сервера,poweroff(режим по умолчанию) — жёсткое выключение сервера,delayed_poweron— жёсткое выключение сервера с последующим включением после завершения эвакуации ВМ.
consul_interval— интервал запуска механизма service-check. Значение по умолчанию — 30 секунд.power_check_timeout— интервал проверки завершения операции выключения сервера.bmc_user— имя пользователя для сервиса BMC.bmc_password— пароль для подключения пользователя к сервису BMC. Этот пароль должен быть сохранён в защищённом хранилище секретов (Vault).bmc_type— отвечает за тип BMC:bmc;ipmi.
bmc_suffix— суффикс для запросов в BMC.bmc_verify_ssl(true/false) — по умолчанию такой же сертификат ЦА, что и везде. Возможно выключить проверку, выбравfalse.
Мониторинг состояния сетевых интерфейсов¶
VMHA может отслеживать состояние критически важных сетевых интерфейсов на вычислительных узлах. Поддерживается мониторинг двух типов интерфейсов: bond-интерфейсов и HBA (fibre channel).
Если контролируемый интерфейс теряет связь и считается отказавшим, VMHA отключает вычислительный узел. Новые ВМ не будут созданы и не переедут на такой узел.
Мониторинг bond-интерфейсов¶
Бонд (bond) — соединение физических сетевых интерфейсов. Можно одновременно мониторить несколько бондов.
Бонд считается отказавшим, если:
все физические интерфейсы, подчинённые бонду (slave-интерфейсы), были в неработоспособном состоянии в течение двух минут (настраивается опцией
prometheus_request_period);сам бонд был выключен на уровне ОС.
Мониторинг HBA (fibre channel)¶
HBA (Host Bus Adapter) — адаптер, который используется для подключения вычислительного узла к системе хранения данных по протоколу Fibre Channel. На вычислительных узлах обычно устанавливается два HBA для обеспечения отказоустойчивости.
VMHA контролирует состояние обоих HBA. Интерфейс считается отказавшим, если оба HBA одновременно находились в неработоспособном состоянии в течение двух минут (настраивается опцией prometheus_request_period).
Настройка мониторинга интерфейсов¶
Чтобы включить мониторинг сетевых интерфейсов, выполните следующие действия:
Откройте веб-интерфейс GitLab на LCM-узле.
Перейдите в репозиторий региона project_k / deployments / <имя региона>.
Откройте файл
globals.d/REGION.ymlи настройте параметры следующим образом:
enable_interfaces_check— укажите типы интерфейсов для мониторинга через запятую:bond,fibre_channelили оба типаbond, fibre_channel;
consul_bond_names— если включаете мониторинг bond-интерфейсов, перечислите имена бондов через запятую.Создайте новый пайплайн: .
Запустите пайплайн, нажав кнопку New pipeline.
Дождитесь завершения задач на этапе setup.
Запустите задачу deploy на этапе deploy и дождитесь её завершения.
Вы можете включить фенсинг вычислительных узлов в случае обнаружения на них отказавших интерфейсов. Для этого установите значение true для параметра fence_failed_interfaces.
При обнаружении отказа контролируемого интерфейса (параметры отказа см. выше) для соответствующего вычислительного узла будет произведён фенсинг и последующая эвакуация согласно существующей механике.
Типичные ошибки и их решения¶
Неудачный фенсинг Nova, Ceph или IPMI¶
В случае невозможности изоляции вычислительного узла эвакуация не происходит. Попытки изоляции циклически продолжаются раз в 30 секунд до момента успешной изоляции вычислительного узла. Такие попытки выполняются бесконечно, но прекращаются, если связь с вычислительным узлом восстанавливается.
Процесс эвакуации ВМ будет приостановлен при обнаружении отказа узла кластера при неудачной попытке:
исключения отказавшего узла из кластера Nova (nova service disable);
исключения отказавшего узла из кластера Ceph (osd blacklist) (применимо только в случае применения фенсинга Ceph);
выключения узла через IPMI (power off).
При неудачном выполнении фенсинга VMHA не выполняет эвакуацию ВМ с вычислительного узла.