Системные администраторы Платформы отвечают за комплексную настройку инфраструктуры Платформы, предоставляемой в качестве услуги конечным потребителям, за устранение неисправностей, сбор диагностической информации и эскалацию неисправностей производителю аппаратной или программной составляющей Платформы.
Системные администраторы выполняют следующие функциональные обязанности в рамках работы с Платформой:
настройка и диагностирование системы;
обслуживание системного и прикладного программного обеспечения системы;
администрирование базы данных;
резервное копирование и восстановление данных;
производство регламентных работ и анализ их результатов.
К системным администраторам предъявляются следующие требования:
Навыки системного администрирования Linux;
Прохождение обучения от компании ITKey по использованию компонентов, разработанных вендором: DRS, HA, Portal;
Навыки работы со службами Платформы, в том числе способность самостоятельно осуществлять:
Подключение к Порталу самообслуживания производится с помощью веб-браузера. Для доступа к интерфейсам управления Портала самообслуживания могут использоваться браузеры актуальных версий:
Google Chrome 72 и выше;
Mozilla Firefox 63 и выше.
При запросе логина и пароля необходимо ввести учетные данные. Внешний вид формы аутентификации приведен на рисунке ниже.
Рисунок 1 — Окно аутентификации в Портале самообслуживания
Главная страница интерфейса управления имеет тематическое боковое меню (далее в тексте — левое меню), с помощью которого выполняется переход к различным разделам интерфейса управления Платформы.
Подключение к интерфейсу управления Openstack CLI
Перед началом работы в CLI необходимо получить исходный файл openrc и загрузить его на локальный компьютер администратора для установки переменных среды. Для получения файла openrc необходимо перейти в интерфейс портала администратора и скачать его на странице Status Page.
Important
Если используется библиотека Castellan, то при работе в Openstack CLI у администратора при каждом подключении будет запрашиваться пароль.
Openstack клиент можно установить на рабочее место администратора. Ниже приведен порядок установки Openstack клиента для различных ОС.
Почти все сервисы платформы — stateless, или имеют внутренние механизмы failover, прихода к консенсусу в кластере. Но есть сервис, на который надо обратить особое внимание — Galera Cluster. Поэтому в пункте Выключение всех компонентов Платформы важно было делать паузы перед выключением следующего узла и запомнить порядок выключения — это минимизирует до определенной степени шанс получить с “несобранным” кластером Galera Cluster с MariaDB после включения.
Порядок включения серверов Платформы в общем случае выглядит так:
Включите с паузами и по очереди управляющие узлы. Включайте в обратном порядке относительно выключения, т.е. если серверы были выключены в порядке controller1 → controller2 → controller3, то тогда, выдерживая достаточные паузы в 5-10 минут после загрузки Linux, производите включение в порядке controller3 → controller2 → controller1. При этом крайне желательно после загрузки сервера (в данном примере controller1) выполнить проверку статуса MariaDB.
Пример:
sshcontroller1mysql-uroot-pPassW0rd-s-s--execute="SHOW GLOBAL STATUS LIKE 'wsrep_local_state_comment';"wsrep_local_state_commentSynced
Если в течение 5 минут статус не перейдет в Synced, все равно продолжайте с запуском остальных управляющих узлов. Когда узлы будут запущены, и позже будут запущены контейнеры consul-server, произойдет автоматический ребутстрап кластера MariaDB.
Оповестите владельцев workload’ов о возможности запуска их нагрузок в облаке — либо самостоятельно включите инстансы в зависимости от технического регламента.
Для отключения платформы и её компонентов с сохранением данных необходимо выполнить следующие шаги:
Оповестить владельцев виртуальных машин о предстоящем отключении.
Выключить сервис DRS, деактивировав задание в панели администратора, затем последовательно подключившись к каждому контроллеру и введя команду systemctlstopkolla-drs-container.service.
Выключить сервис HA, последовательно подключившись к каждому контроллеру и введя команду systemctlstopkolla-consul-container.service.
Подключиться к серверу LCM для выполнения дальнейших действий.
Пример:
sshlcmsourceadmin-openrc.sh
Зафиксировать состояние виртуальных машин на момент выключения региона, введя команду:
openstack server list --all-projects > VMs.$(date "+%Y-%m-%d-%H-%M-%S").txt
Выключить виртуальные машины средствами OpenStack, введя команду:
Если проверка покажет наличие виртуальных машин в статсуе ACTIVE, то необходимо повторить выключение каждой такой виртуальной машины индивидуально, введя команду openstackserverstop<VMID>, подставляя в качестве VMID значенем из столбца ID предыдущего вывода.
for HOST in $(openstack hypervisor list -c "Hypervisor Hostname" -f value);\
do \
ssh -x ${HOST} "shutdown -h now";\
done
В строгом порядке очерёдности control3 → control2 → control1, с паузами достаточными для полного выключения сервера (время зависит от используемого аппаратного комплекса и должно быть уточнено в момент проведения ПСИ) средствами операционной системы выключить узлы слоя управления, проверяя процесс выключения и состояние серверов через IPMI:
ssh -x ctl3 ‘shutdown -h now’
# пауза до полного выключения
ssh -x ctl2 ‘shutdown -h now’
# пауза до полного выключения
ssh -x ctl1 ‘shutdown -h now’
# пауза до полного выключения
После выполнения этих шагов регион платформы будет полностью выключен.
В частной инсталляции Платформы не все опции команд Openstack CLI могут быть использованы, поэтому они приводятся для справки. Некоторые виды и типы интеграций могут быть недоступны и через API.
Квоты предоставляют возможность ограничивать использование ресурсов в проекте. Администратор может ограничивать ресурсы для каждого проекта по отдельности. В случае превышения квоты новый объект не сможет быть создан.
Управление квотами проекта осуществляется через CLI.
Для просмотра списка флейворов на Портале администратора перейдите в раздел Ресурсы → Flavors.
Настройка приоритетов на базе cpu-shares и cpu-quotes для ВМ с помощью флейворов
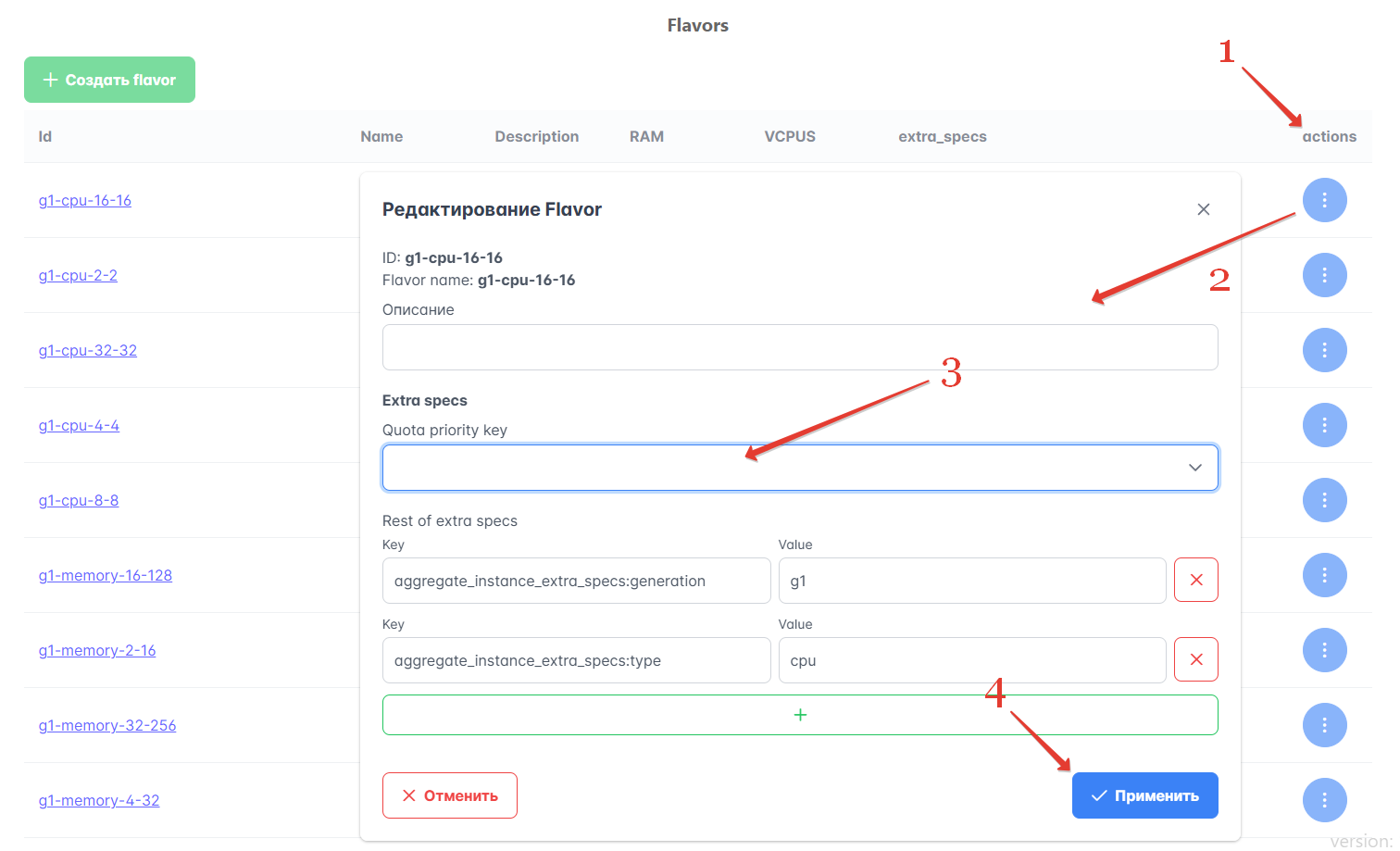
В разделе Ресурсы → Flavors на Портале администратора вы можете установить приоритеты для выделения ресурсов при наличии конкуренции за них. Для этого используйте либо quota:cpu_shares, либо quota:cpu_quota, но не оба параметра сразу. Параметры определяют приоритет потребления CPU и Memory для ВМ, созданных из этих флейворов, в пределах хоста или пула ресурсов. Чем выше значение одного или другого приоритета, тем больше ресурсов получит ВМ в пределах пула или отдельного хоста.
Чтобы установить приоритет по выделению ресурсов для ВМ с помощью флейвора, выполните следующие действия:
На вкладке Ресурсы → Flavors нажмите выпадающий список в столбце “Actions” для нужного флейвора. Выберите “Pедактировать”.
В открывшемся окне проверьте имя и ID флейвора.
Выберите quota:cpu_shares либо quota:cpu_quota в Quota priority key. Задайте значение для этого параметра в поле Quota priority value.
Нажмите “Применить”.
Рисунок 2 — Настройка приоритетов для флейворов
Добавленные квоты появятся в столбце “extra_specs” в таблице флейворов.
–id <id> — ID шаблона; ‘auto’ создает UUID (значение по умолчанию: auto);
–ram <MB> — размер памяти в MB (значение по умолчанию: 256MB);
–disk <GB> — размер диска в GB (значение по умолчанию: 0GB);
–ephemeral <GB> — размер эфемерного диска в GB (значение по умолчанию: 0GB);
–swap <MB> — дополнительный размер swap в MB (значение по умолчанию: 0MB);
–vcpus <vcpus> — количество vCPU (значение по умолчанию: 1);
–rxtx-factor <factor> — RX/TX фактор (значение по умолчанию: 1.0);
–public — шаблон доступен в других проектах (значение по умолчанию);
–private — шаблон недоступен в других проектах;
–property <key=value> — дополнительные свойства флейвора (опция может использоваться несколько раз для установки различных свойств);
–project <project> — разрешает доступ к флейвору из проекта <project> (по имени проекта или его ID), опция используется совместно с –private;
–description <description> — описание флейвора;
–project-domain <project-domain> — домен проекта (имя домена или его ID). Опция используется в случае конфликтов между названиями проектов;
–<flavor-name> — наименование флейвора.
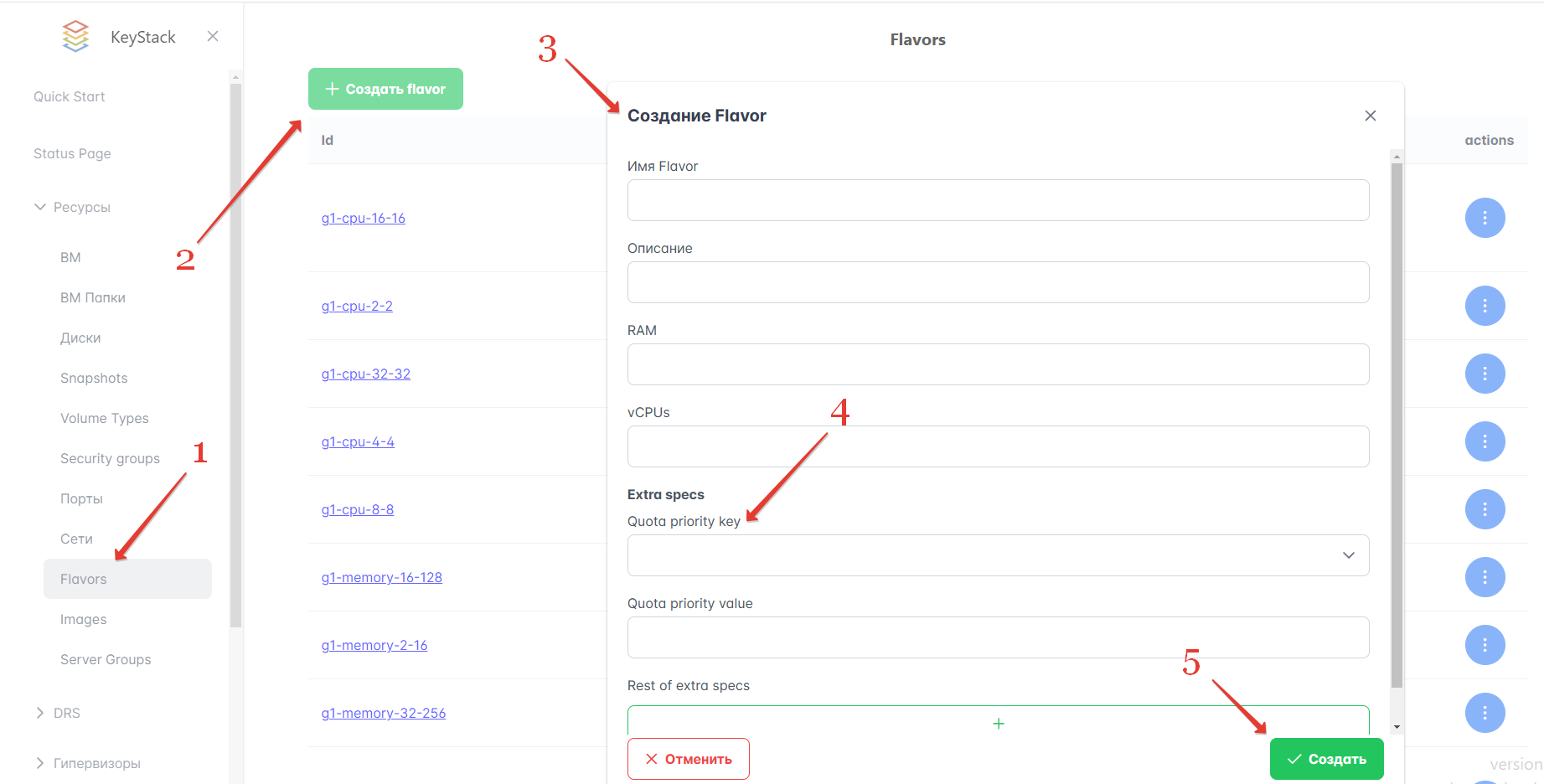
На Портале администратора:
В левом меню Портала перейдите в раздел Ресурсы → Flavors.
Нажмите кнопку “Создать flavor”.
Добавьте имя, описание, значения RAM и vCPUs для флейвора.
В разделе Extra specs укажите приоритеты для выделения ресурсов на ВМ, основанных на флейворе. Выберите quota:cpu_shares либо quota:cpu_quota в Quota priority key. Задайте значение для выбранного параметра в поле Quota priority value. Подробнее о приоритетах для ресурсов ВМ см. выше.
В левом меню Портала перейдите в раздел Ресурсы → ВМ.
Нажмите кнопку “Создать ВМ”.
Выберите действие Choose template в открывшемся окне. Название выбранного шаблона отобразится на месте кнопки Choose template, а справа будут параметры создаваемой ВМ.
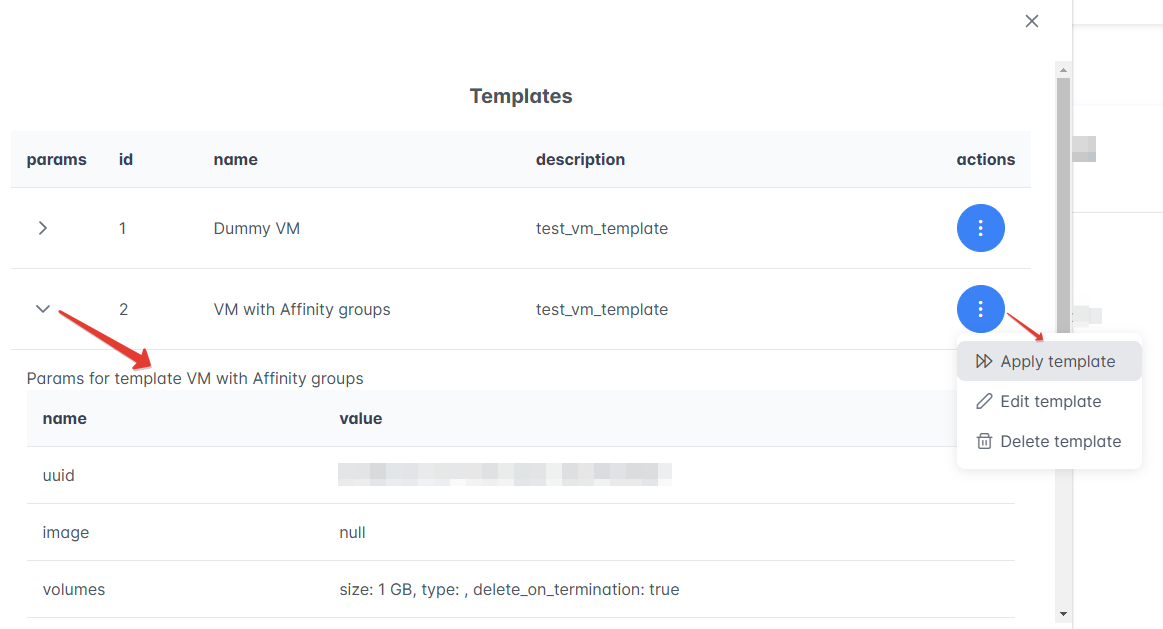
Найдите нужный шаблон в окне Templates. Нажмите значок > в столбце “Params”, чтобы посмотреть параметры шаблона.
Выберите дальнейшее действие с шаблоном в столбце “Actions”:
Для изменения параметров шаблона выберите Apply template.
Для изменения названия шаблона (Template name) или его описания (Template description) выберите Edit template. Нажмите “Редактировать”, чтобы применить изменения.
Для удаления шаблона выберите Delete template.
Рисунок 5 — Редактирование шаблона ВМ
Если вы выбрали действие Apply template, название выбранного шаблона отобразится на месте кнопки Choose template. Настройте параметры шаблона на вкладке Template params.
Выберите, как сохранить изменения параметров шаблона:
Чтобы применить изменения к отредактированному шаблону, нажмите Save current template.
Чтобы сохранить его как новый шаблон, нажмите Save as new template.
В левом меню Портала перейдите в раздел Ресурсы → ВМ.
Нажмите кнопку “Создать ВМ”.
Выберите действие Choose template в открывшемся окне.
Найдите нужный шаблон в окне Templates и выберите для него Apply template в столбце “Actions”.
Название выбранного шаблона отобразится на месте кнопки Choose template, а справа будут параметры создаваемой ВМ. Настройте параметры создаваемой ВМ на вкладке New VM params.
Нажмите “Создать”.
Новая виртуальная машина со статусом BUILD появится в списке машин на странице ВМ.
Создание образа осуществляется в Портале самообслуживания, в интерфейсе Horizon или с использованием Openstack CLI. Образ можно создать путем загрузки файла в формате либо путем создания из существующего диска. Поддерживаются следующие форматы: raw, vhd, vhdx, vmdk, vdi, iso, ploop, qcow2, aki, ari и ami.
Создание образа из файла
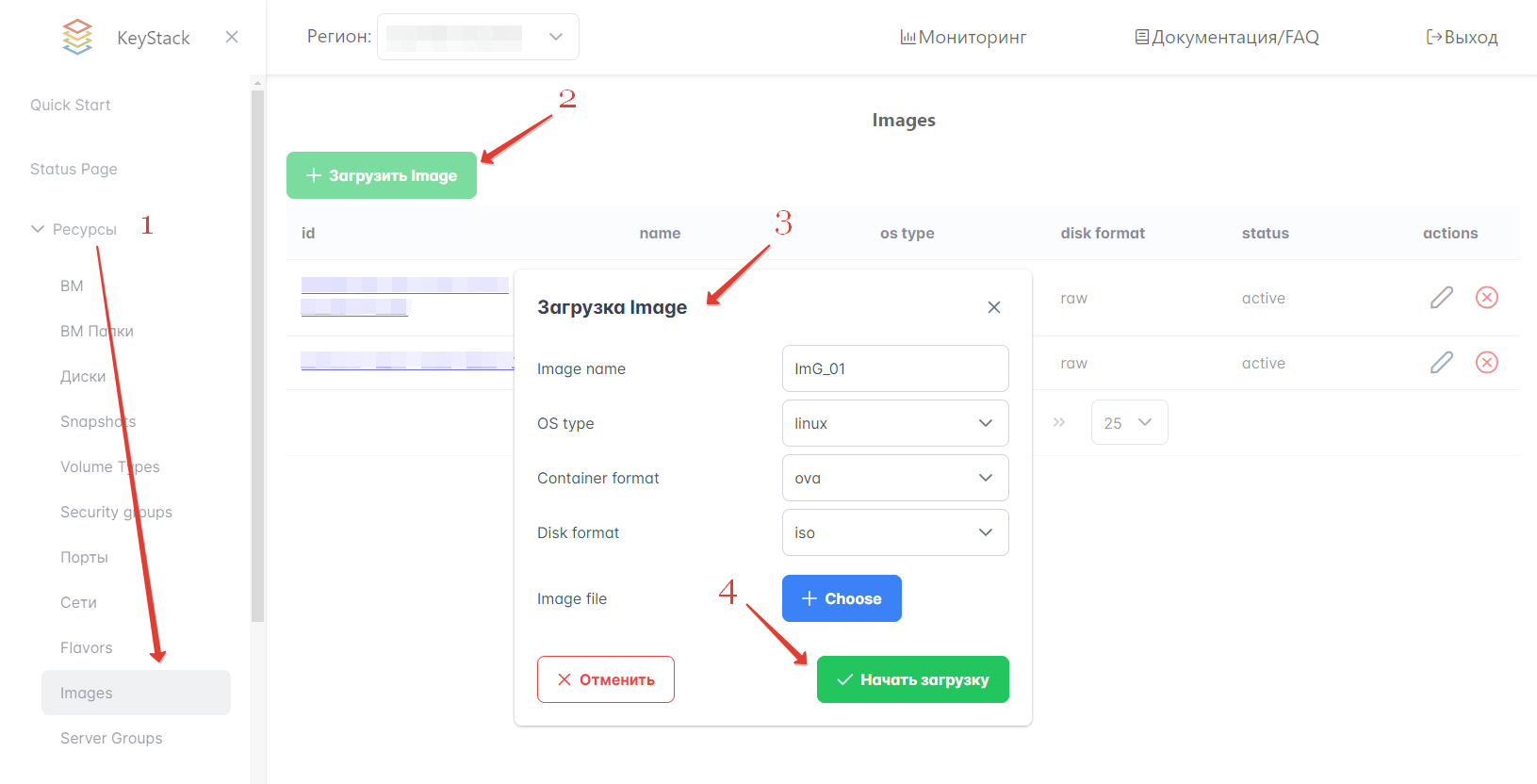
Для создания образа в Портале самообслуживания выполните следующие действия:
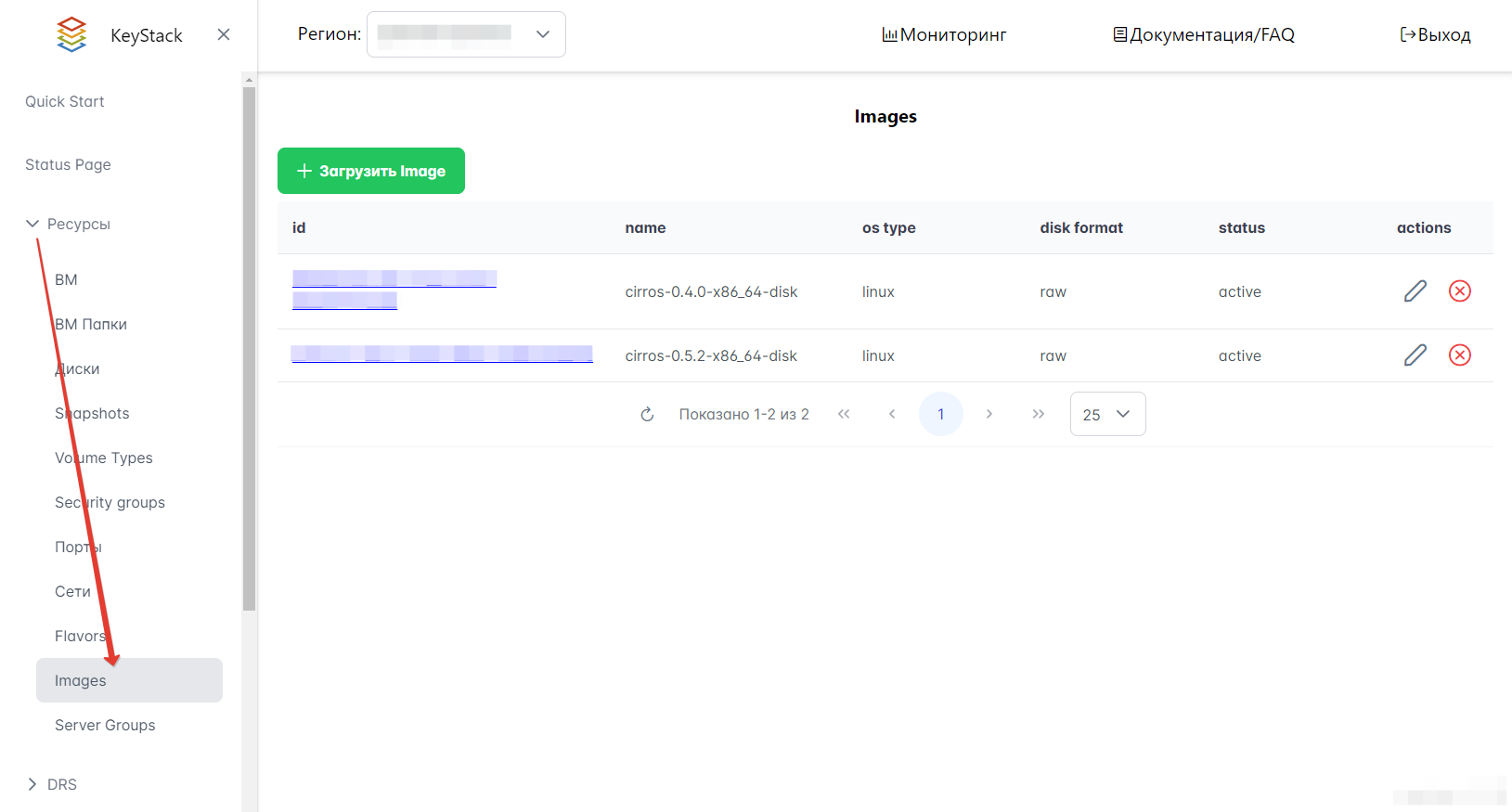
В левом меню Портала перейдите в раздел Ресурсы → Images.
Нажмите кнопку “Загрузить Image”.
Заполните поля. Обязательно нужно указать имя образа, тип ОС и выбрать файл для образа. Пример заполнения см. на рисунке ниже.
Нажмите кнопку “Начать загрузку”.
Рисунок 7 — Создание образа из файла
Для загрузки образа размером более 20GB рекомендуется использовать клиента командной строки.
Для загрузки образа в Openstack CLI выполните команду: openstackimagecreate--private--container-formatbare--disk-formatqcow2--file<имя_файла.raw><имя_образа>
Если необходимо загрузить образ с поддержкой резервного копирования или смены пароля, добавьте свойства для работы с qemu-guest-agent: openstackimagecreate--private--container-formatbare--disk-formatqcow2--file<имя_файла.raw>--propertyhw_qemu_guest_agent=yes--propertyos_require_quiesce=yes<имя_образа>
Создание образа из существующего диска
Вы можете создать образ из существующего диска в интерфейсе Horizon. Для этого необходимо в левом меню перейти в раздел Диски, найти диск, из которого будет создаваться образ, и затем в выпадающем списке выбрать пункт меню “Загрузить образ”.
В форме создания образа нужно выбрать формат диска (см. рисунок ниже), указать название образа и нажать кнопку “Загрузить”.
Рисунок 8 — Создание образа из существующего диска
Вы можете загружать образы гостевых ВМ в Glance. Запрос на создание и загрузку образов в Glance передается в модуль states через Terraform в виде переменной user_images.
В файл tf_states/variables.tf добавьте переменную user_images следующего вида:
variable"user_images"{description="Pass user images as map"type=map(any)default={# Below is an example of user image definition"ubuntu-24.04-x64"={image_source_url="https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img"container_format="bare"disk_format="qcow2"min_disk_gb=5visibility="public"properties={os_distro="ubuntu"os_type="linux"os_version="24.04"os_require_quiesce="True"ssh_key="allow"hw_machine_type="q35"}}}}
После чего убедитесь, что эта переменная используется в модуле tf_states, вызываемом из файла tf_states/main.tf:
Удалить образ ВМ можно на Портале администратора или в интерфейсе Horizon.
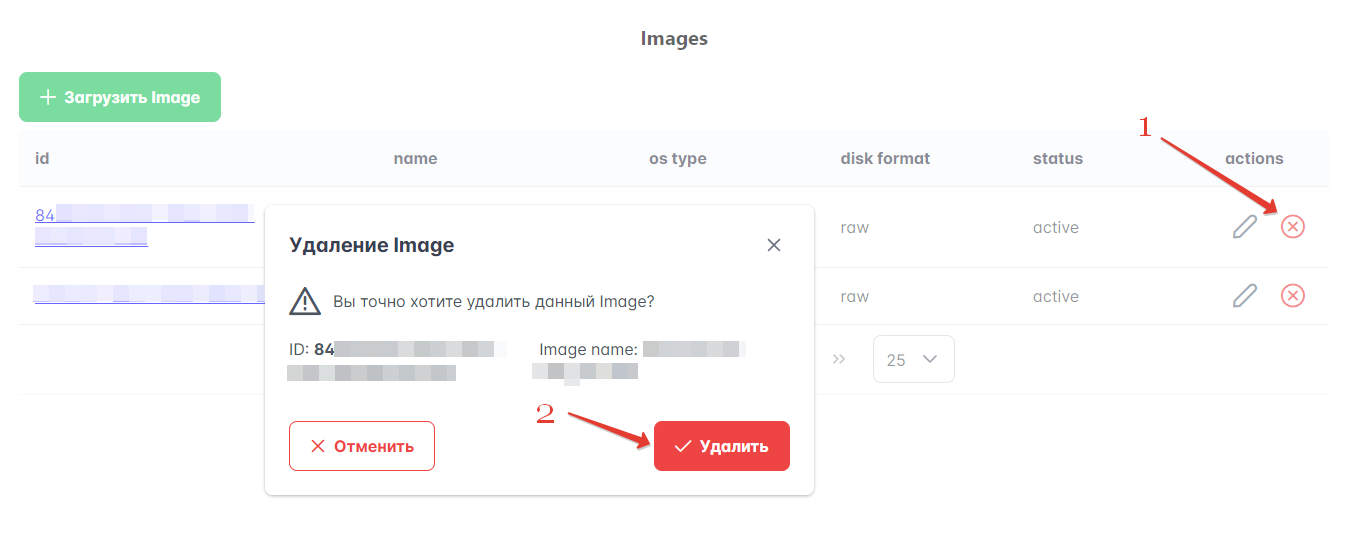
Для удаления образа в Портале администратора выполните следующие действия:
Перейдите в раздел Ресурсы → Images, выберите образ для удаления и нажмите значок X в столбце “Actions”.
Проверьте имя и ID образа. Если все правильно, нажмите кнопку “Удалить” (см. рисунок ниже).
Рисунок 9 — Удаление образа
Включение множества очередей (multiqueue) в Unix-подобных операционных систем
KeyStack поддерживает множества очередей (multiqueue) у образа виртуальной машины (ВМ) и отдельной ВМ для операционных систем семейства Linux.
Ограничения
Функция множества очередей virtio-net обеспечивает повышение производительности, но имеет некоторые ограничения:
ОС ВМ ограничена ~ 200 векторами MSI. Для каждой очереди сетевого адаптера требуется вектор MSI, а также любое устройство virtio или назначенное устройство PCI. Определение экземпляра с несколькими сетевыми адаптерами virtio и виртуальными ЦП может привести к превышению лимита гостевого MSI.
Множества очередей хорошо работают для входящего трафика, но иногда могут вызвать снижение производительности для исходящего трафика.
Включение множества очередей увеличивает общую пропускную способность сети, но одновременно увеличивает потребление ресурсов CPU.
Если функция множества очередей была включена на хосте, но не была включена администратором в ОС ВМ, векторы MSI будут использоваться впустую.
Количество очередей автоматически устанавливается равным количеству виртуальных ЦП. Чем больше количество ЦП, тем выше пропускная способность сети.
Примечание. Для некоторых образов операционных систем, например, Centos6, недостаточно включить множества очередей только на уровне образа в конфигурации QEMU. Администратору ОС необходимо вручную включить функциональность с помощью ethtool на самой ВМ.
Включение множества очередей для новых ВМ из образа
Вариант включает множества очередей на уровне образа и будет работать для всех ВМ, созданных на базе этого образа после выполнения инструкции.
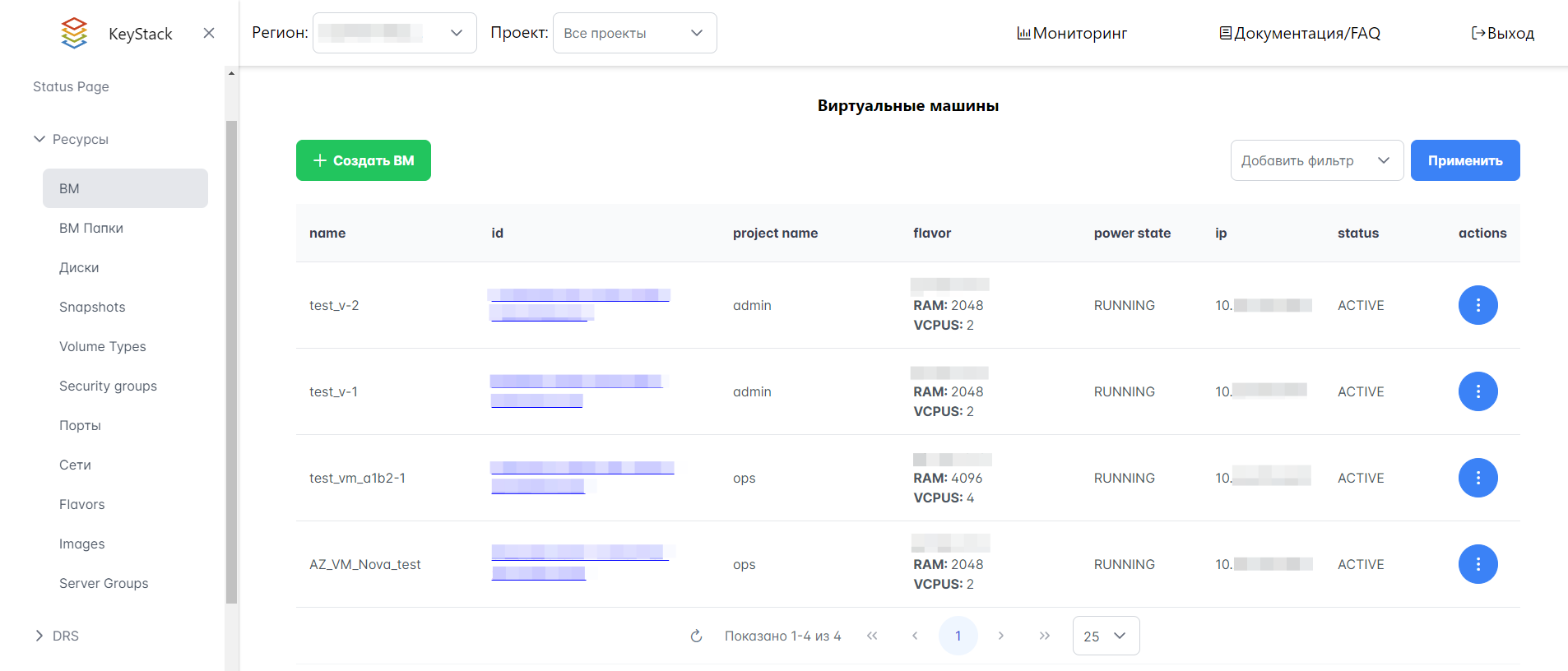
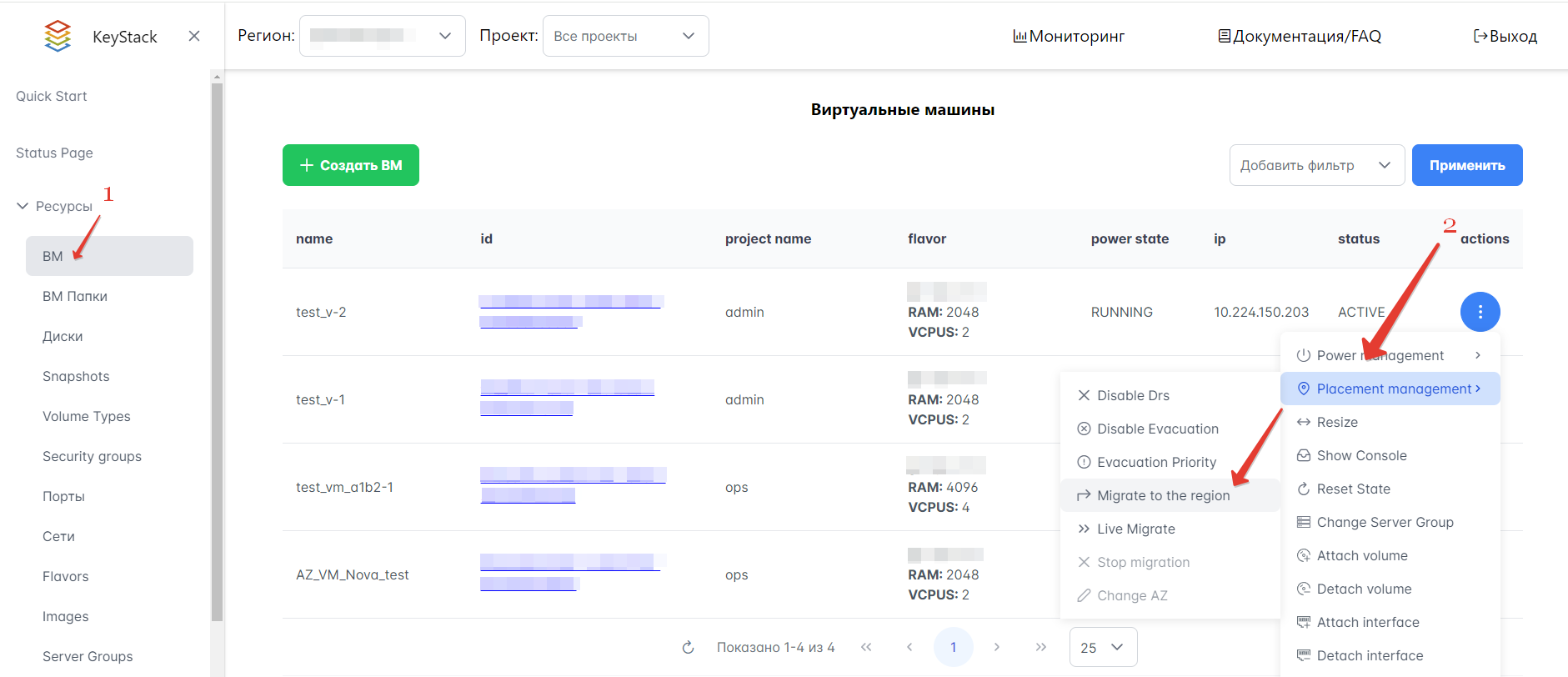
Просмотр списка ВМ проекта осуществляется в интерфейсе Портала администратора, Horizon или в Openstack CLI.
Для просмотра списка ВМ на Портале администратора необходимо выбрать Ресурсы → ВМ в левом меню интерфейса (см. рисунок ниже).
Рисунок 10 — Список ВМ на Портале администратора
Используйте фильтры в правом верхнем углу интерфейса для быстрого поиска нужных ВМ по определенным параметрам, таким как образ (image), MAC-адрес (MAC address), IP и LUN ID.
Просмотр списка ВМ в CLI выполняется командой serverlist. Полный перечень опций выглядит следующим образом:
–sort-column SORT_COLUMN — столбцы для сортировки данных (несуществующие столбцы игнорируются);
–reservation-id <reservation-id> — возвращать экземпляры ВМ, соответствующие резервированию;
–ip <ip-address-regex> — регулярное выражение для отбора ВМ по соответствующим адресам;
–name <name-regex> — регулярное выражение для отбора ВМ по имени;
–instance-name <server-name> — регулярное выражение для отбора ВМ по имени инстанса;
–status <status> — отбирать ВМ по указанному статусу;
–flavor <flavor> — отбирать ВМ по указанному шаблону ВМ (по наименованию или ID);
–image <image> — отбирать ВМ по указанному образу (по наименованию или ID);
–host <hostname> — отбирать ВМ по гипервизору размещения;
–all-projects — включать в выборку все проекты;
–project <project> — отбирать ВМ в указанном проекте (по наименованию или ID);
–project-domain <project-domain> — отбирать ВМ по домену проекта (по наименованию или ID). Опция используется в случае конфликтов между названиями проектов;
–user <user> — отбирать ВМ указанного пользователя (по имени или ID);
–user-domain <user-domain> — отбирать ВМ по домену пользователя (по имени или ID). Опция используется в случае конфликтов между именами пользователей;
–long — выводить дополнительные поля;
-n, –no-name-lookup — пропустить разрешение имен шаблонов ВМ и образов. Не используется совместно с опцией –name-lookup-one-by-one;
–name-lookup-one-by-one — при разрешении имен шаблонов ВМ и образов искать из по мере необходимости. Не используется совместно с опцией –no-name-lookup|-n;
–marker <server> — последняя ВМ предыдущей страницы. Выводит весь список ВМ после <server>, если не указано иное. Если используется с опцией –deleted, маркер <server> должен быть идентификатором (ID), иначе допускается использование наименование ВМ или ID;
–limit <num-servers> — максимальное количество ВМ в выводимом списке. Если указывается значение -1, тогда выводятся все ВМ. Если указанное значение <num-servers> превышает значение конфигурационного параметра osapi_max_limit, то выводится osapi_max_limit ВМ;
–deleted — выводить только удаленные ВМ;
–changes-before <changes-before> — выводить список ВМ, измененных до указанного момента времени. Указываемое время должно быть в формате ISO 8061 (например, 2016-03-05T06: 27: 59Z);
–changes-since <changes-since> — выводить список ВМ, измененных после указанного момента времени. Указываемое время должно быть в формате ISO 8061 (например, 2016-03-05T06: 27: 59Z);
–locked — выводить в список только заблокированные ВМ;
–unlocked — выводить в спискок только незаблокированные ВМ;
–tags <tag> — выводить ВМ с указанными тегами. Может использоваться несколько раз для отбора ВМ по нескольким тегам;
–not-tags <tag> — выводить только те ВМ, у которых нет указанного тега. Может использоваться несколько раз для указания нескольких тегов.
Запуск, перезапуск и остановка ВМ осуществляется в интерфейсе Портала администратора, Horizon или в OpenStack CLI.
Для управления состоянием ВМ в интерфейса Horizon используйте кнопки “Выключить инстанс”, “Горячая перезагрузка инстанса” и “Холодная перезагрузка инстанса” (см. рисунок ниже).
Рисунок 11 — Кнопки управления состоянием ВМ
Текущий статус виртуальной машины отображается в столбце “Status” (см. рисунок выше).
В Openstack CLI операции запуска, перезапуска и остановки ВМ выполняются командами serverstart, serverreboot и serverstop соответственно. Синтаксис команд:
–image <image> — создать ВМ с использованием существующего образа (наименование или ID);
–image-property <key=value> — изменяемые свойства используемого образа;
–volume <volume> — создать ВМ с использованием указанного диска (наименование или ID). Данная опция автоматически создает отображение блочного устройства с индексом загрузки 0. Не следует использовать дублирующее сопоставление с использованием опции –block-device-mapping;
–password <password> — установить пароль для создаваемой ВМ;
–flavor <flavor> — использовать указанный шаблон (наименование или ID);
–security-group <security-group> — группа безопасности, назначаемая ВМ. Может использоваться несколько раз для назначения нескольких групп безопасности;
–key-name <key-name> — используемая ключевая пара (необязательный параметр);
–property <key=value> — установить дополнительные свойства ВМ (может указываться несколько раз для установки нескольких свойств);
–file <dest-filename=source-filename> — добавить в образ ВМ указанный файл (может указываться несколько раз для добавления разных файлов);
–user-data <user-data> — файл данных пользователя для обслуживания с сервера метаданных;
–description <description> — описание создаваемой ВМ;
–availability-zone <zone-name> — установить зону доступности ВМ;
–host <host> — создать ВМ с использованием службы Nova на конкретном гипервизоре;
–hypervisor-hostname <hypervisor-hostname> — создавать ВМ на указанном гипервизоре;
–boot-from-volume <volume-size> — при использовании в сочетании с параметром –image или –image-property этот параметр создает сопоставление блочного устройства с индексом загрузки 0 и сообщает службе compute создать том заданного размера (в GB) из указанного образа и использовать его в качестве корневого тома. Корневой том не будет удален при удалении ВМ. Этот параметр является взаимоисключающим с параметром –volume;
–block-device-mapping <dev-name=mapping> — создать блочное устройство. Блочное устройство указывается в формате <dev-name>=<id>:<type>:<size(GB)>:<delete-on-terminate>, где:
<dev-name> — наименование блочного устройства, например, vdb, xvdc (обазательный параметр);
<id> — наименование или ID тома, снапшота или образа (обязательный параметр);
<type> — volume (том), snapshot (снапшот) или image (образ). Значение по умолчанию — volume;
<size(GB)> — размер тома, если он создается из снапшота или образа (необязательный параметр);
<delete-on-terminate> — true или false, удалять при удалении ВМ. Значение по умолчанию — false (необязательный параметр);
–nic <net-id=net-uuid,v4-fixed-ip=ip-addr,port-id=port-uuid,auto,none> — создать сетевой адаптер. Опция используется несколько раз для создания нескольких адаптеров. Необходимо указывать ID сети или ID порта, но не оба сразу;
net-id — подключить сетевой адаптер к сети с UUID net-uuid;
port-id — подключить сетевой адаптер к порту с UUID port-uuid;
–network <network> — создать сетевой адаптер и подключить к сети. Можно указывать несколько раз для создания нескольких сетевых адаптеров. Данная опция является оболочкой для опции –nic net-id=<network>, которая обеспечивает простой синтаксис для стандартного варианта подключения новой ВМ к сети. Для более сложных случаев рекомендуется использовать полный синтаксис –nic;
–port <port> — создать сетевой адаптер и подключить его к порту. Можно указывать несколько раз для создания нескольких сетевых адаптеров. Данная опция является оболочкой для опции –nic port-id=<port>, которая обеспечивает простой синтаксис для стандартного подключения новой ВМ к заданному порту. Для более сложных случаев рекомендуется использовать полный синтаксис –nic;
–hint <key=value> — подсказки для планировщика (необязательный параметр);
–use-config-drive — разрешает использование конфигурационного диска;
–no-config-drive — запрещает использование конфигурационного диска;
–config-drive <config-drive-volume>|True — устаревшая опция указания использования указанного тома в качестве диска конфигурации. Заменено на –use-config-drive;
–min <count> — минимальное количество ВМ для запуска. Значение по умолчанию — 1;
–max <count> — максимальное количество ВМ для запуска. Значение по умолчанию — 1;
–wait — дождаться окончания сборки;
–tag <tag> — теги ВМ. Можно указывать несколько раз для добавления нескольких тегов;
образ, из которого будет создаваться виртуальная машина, должен быть собран с поддержкой UEFI;
в метаданные образа добавлены свойства os_secure_boot=required и hw_firmware_type=uefi.
Добавить свойства можно через Horizon или CLI: openstackimageset--propertyhw_firmware_type=uefi--propertyos_secure_boot=required$IMAGE.
Администратор может запретить безопасную загрузку даже при наличии необходимых свойств в метаданных образа: openstackflavorset--propertyos:secure_boot=disabled$FLAVOR
Также есть возможность запрашивать безопасную загрузку, если хост ее поддерживает. Это делается через настройку метаданных образа: openstackimageset--propertyos_secure_boot=optional$IMAGE
Узнать, поддерживает ли хост безопасную загрузку, можно таким образом:
COMPUTE_UUID=$(openstack resource provider list --name $HOST -f value -c uuid)
openstack resource provider trait list $COMPUTE_UUID | grep COMPUTE_SECURITY_UEFI_SECURE_BOOT
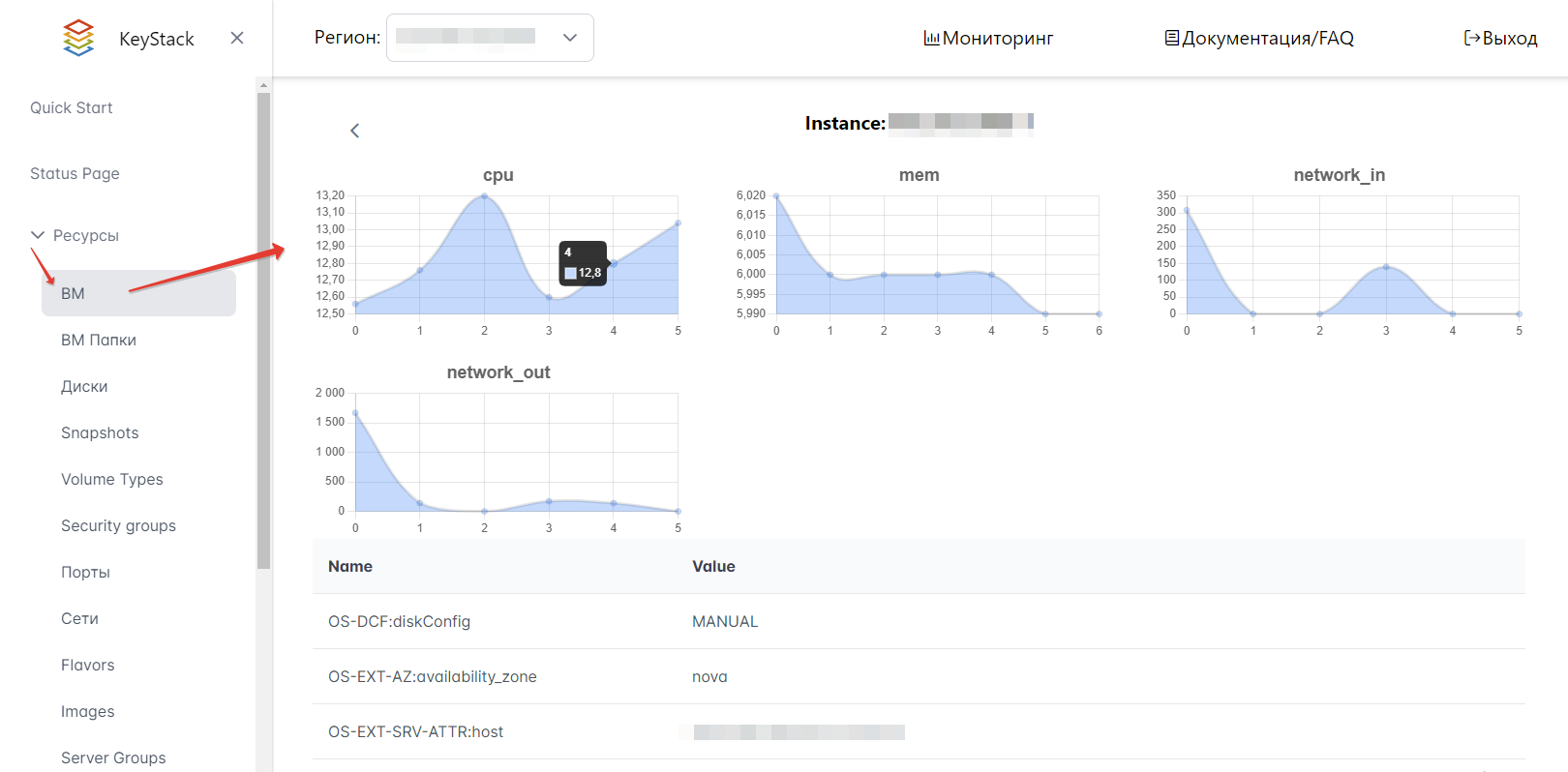
Вы можете просматривать потребление ресурсов виртуальных машин в интерфейсе Портала администратора. На странице каждой ВМ доступны графики со статистикой по таким показателям, как CPU (cpu), память (mem), входящий и исходящий трафик сети (network_in и network_out). Статистика обновляется каждые 10 минут.
Для просмотра производительности ВМ выберите Ресурсы → ВМ в левом меню Портала и нажмите ссылку с ID любой машины.
Для выбранной ВМ будут отображаться графики со статистикой по использованию CPU, памяти и сетевых ресурсов. Помимо графиков, информация о ВМ включает остальные детали, такие как ID и имя ВМ, статус, теги и т.д., которые отображаются внизу страницы.
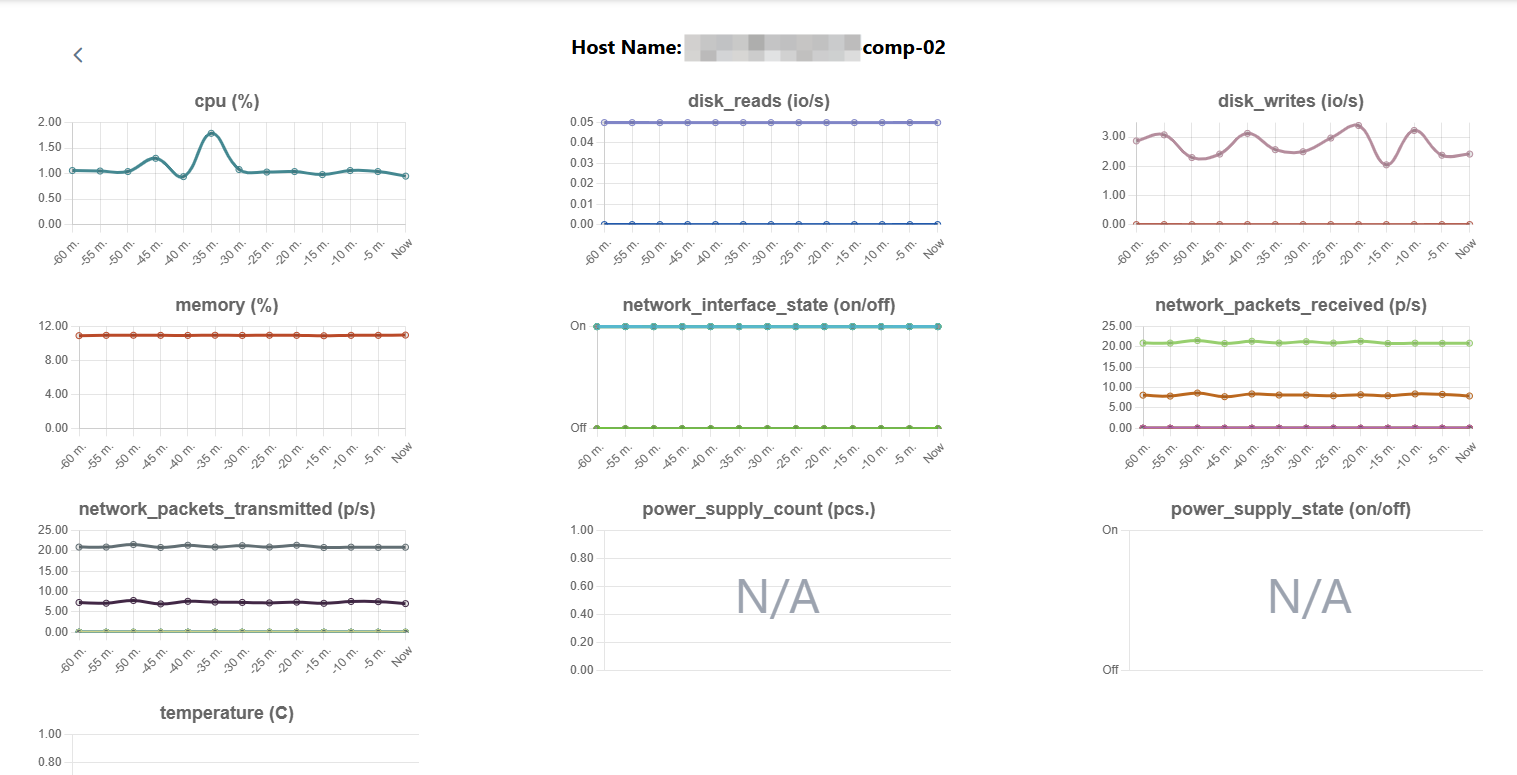
Вы можете просматривать информацию о потребляемых ресурсах вычислительных узлов (гипервизоров) в интерфейсе Портала администратора. На странице каждого гипервизора доступны графики со статистикой по таким показателям, как загрузка CPU, использование памяти и температура.
Для просмотра производительности вычислительного узла выберите Гипервизоры → Гипервизоры в левом меню Портала и нажмите ссылку с ID необходимого узла.
Данный механизм позволяет “приземлять” виртуальные машины на выделенные физические ядра гипервизора, которые будут использоваться только этой виртуальной машиной и никакими другими процессами либо сервисами со стороны хостовой операционной системы.
Его настройка включает несколько шагов: настройку гипервизора, настройку сервиса nova-compute, настройку host aggregate и флейвора.
Настройка гипервизора.
Настройка предполагает добавление опций в загрузку ядра — isolcpus=2,3,4,5,6,7… - перечислите все ядра, которые нужно изолировать — добавление данной настройки предполагает перезагрузку сервера.
Настройка сервиса nova-compute.
Далее необходимо доработать конфигурацию сервиса nova-compute — добавьте в nova.conf гипервизора, на котором выполнена настройка isolcpus.
[compute]cpu_dedicated_set=2-10#указать желаемый набор ядер, который коррелирует с isolcpus
Настройка host aggregate и flavor.
Создайте агрегат, в который нужно добавить гипервизоры, где будет использоваться механизим CPU pinning. В метаданные агрегата добавьте параметр: pinned = true
Создайте флейвор нужного размера и добавьте в него метаданные:
Memory ballooning — это технология управления оперативной памятью в виртуализированных средах, включая OpenStack. Она позволяет гипервизору динамически изменять объем оперативной памяти, доступной виртуальной машине, в зависимости от текущих потребностей.
Как работает memory ballooning:
В каждой ВМ устанавливается специальный драйвер (balloon driver), который взаимодействует с гипервизором. Гипервизор использует этот драйвер, чтобы запрашивать у ВМ “освободить” или “предоставить” память.
Когда гипервизору требуется освободить память, он посылает запрос balloon-драйверу в ВМ. Balloon-драйвер “заполняет” память ВМ с помощью выделения фиктивных блоков памяти, которые более не используются ВМ. Эти блоки памяти возвращаются гипервизору и могут быть перераспределены другим ВМ.
Когда ВМ требуется больше памяти, гипервизор может “сдуть” balloon, освобождая память, ранее выделенную другим ВМ.
Этот механизм включен в продукте по умолчанию, но для его работы необходимо выполнить требования к подготовке образов гостевых операционных систем.
Требование к образам Windows:
наличие Balloon драйвера, включен в VirtIO Windows Driver Pack,
установленая служба BalloonService (тип запуска службы - Auto).
Требования к образам Linux:
наличие VirtIO драйверов. Модуль virtio_balloon обычно включён в большинство современных дистрибутивов.
Изменение ресурсов виртуальной машины используется для увеличения или уменьшения количества виртуальных CPU или RAM виртуальной машины. Изменение ресурсов ВМ осуществляется в интерфейсе Портала администратора, Horizon или в OpenStack CLI.
Для изменения ресурсов ВМ в Horizon необходимо выбрать Вычислительные ресурсы → Инстансы в левом меню, далее найти ВМ, ресурсы которой необходимо изменить, и выбрать в контекстном меню “Изменить размер инстанса” (см. рисунок ниже).
Рисунок 15 — Меню изменения размера ВМ
В окне изменения размера нужно указать новый шаблон ВМ.
Изменение размера ВМ реализуется путем создания новой ВМ и копирования исходного диска ВМ в новый. Это двухэтапный процесс: первый шаг — изменение размера, второй шаг — либо подтверждение и успеха операции и освобождение старой ВМ, либо объявление возврата операции (освобождение новой ВМ и запуск старой ВМ).
В OpenStack CLI изменение размера ВМ выполняется командой serverresize:
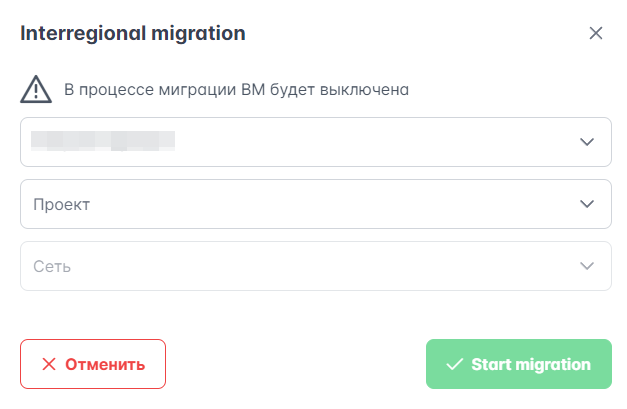
В KeyStack зоны доступности (Availability Zone, AZ) применяются для физической изоляции гипервизоров и обеспечения отказоустойчивости.
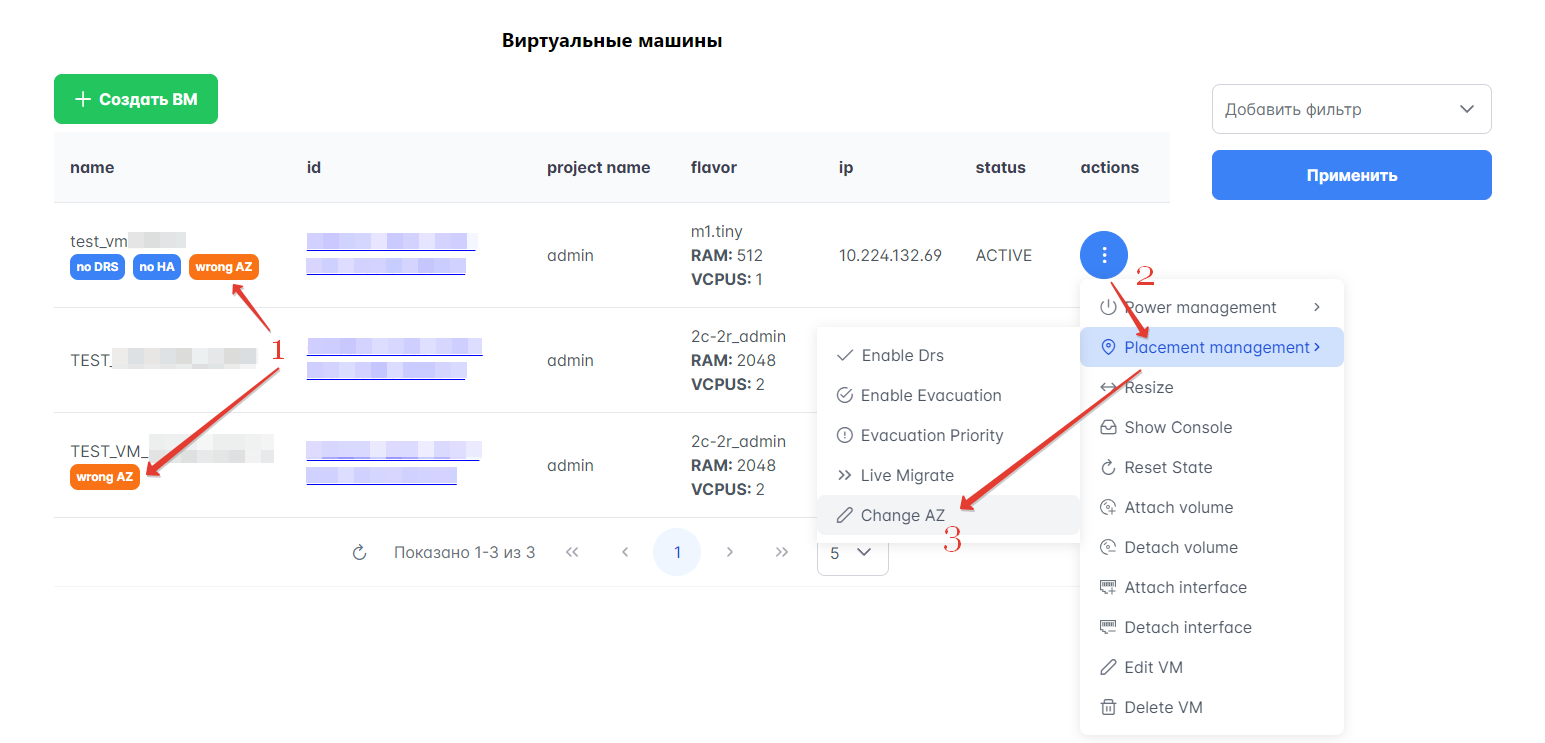
В результате ручной миграции зона доступности виртуальной машины может отличаться от зоны доступности гипервизора, где она находится. Подобные ВМ отмечаются лейблом “wrong AZ” в таблице ВМ на вкладке Ресурсы → ВМ.
Чтобы сменить зону доступности ВМ:
На вкладке Ресурсы → ВМ выберите любую из виртуальных машин, расположенных не в своей зоне доступности.
Нажмите выпадающий список в столбце “Actions” и выберите “Placement management”, а затем “Change AZ”.
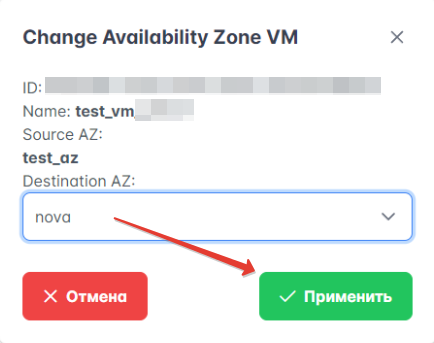
Рисунок 16 – Смена зоны доступности ВМ
В открывшемся окне выберите зону доступности в выпадающем списке и нажмите “Применить”.
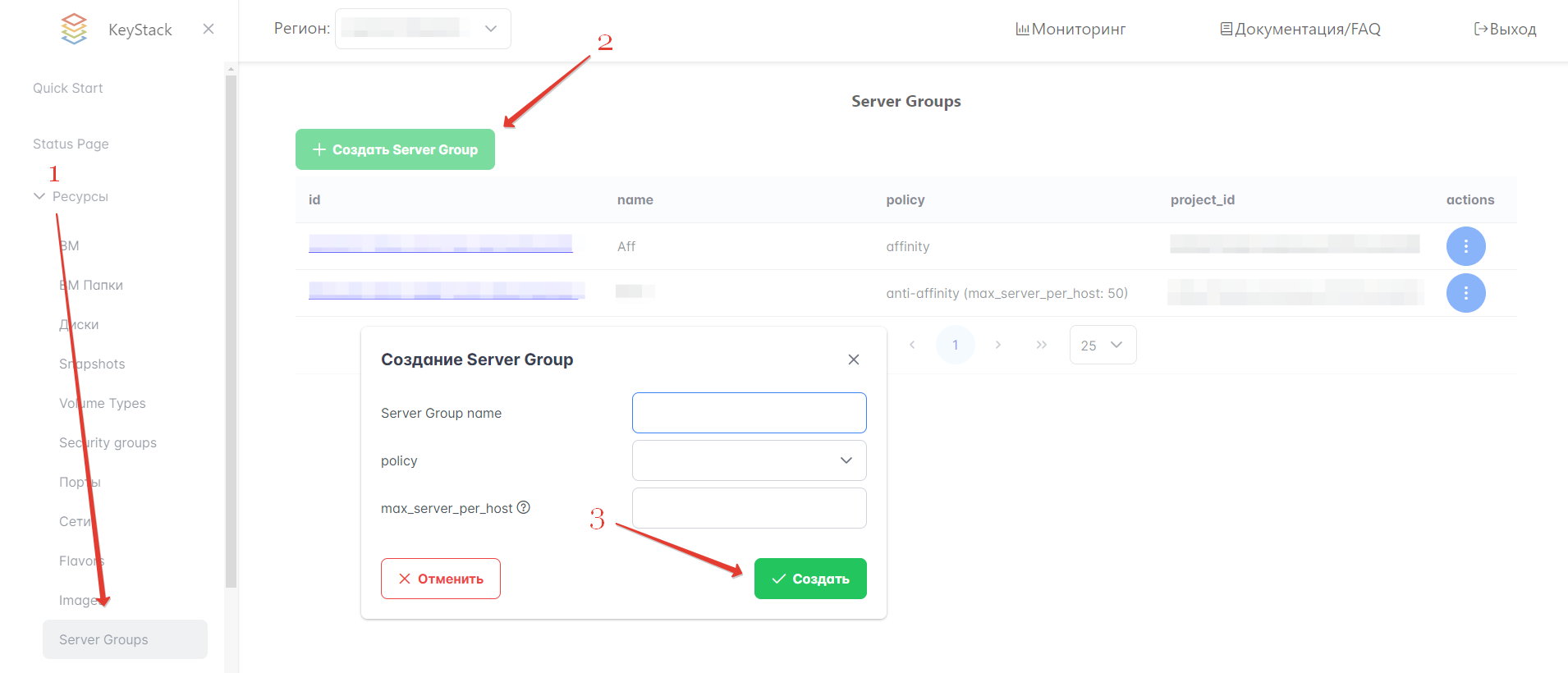
В KeyStack группы серверов ВМ (сервер-группы, server groups) применяются для объединения виртуальных машин в группы, которым можно присвоить определенные свойства. Группы серверов привязаны к конкретному проекту.
Для создания группы серверов ВМ в Портале администратора выполните следующие действия:
В левом меню Портала перейдите в раздел Ресурсы → Server Groups.
Нажмите кнопку “Создать Server Group”.
Заполните поля. Обязательно нужно указать имя группы и политику расположения. При выборе anti-affinity policy необходимо также указать максимально возможное количество ВМ на хост. Когда все поля будут заполнены, нажмите кнопку “Создать”.
Рисунок 18 — Группы серверов ВМ
Для просмотра всех данных о группе серверов нажмите ID группы на странице списка всех групп.
Для удаления группы серверов ВМ найдите в списке нужную группу, нажмите выпадающий список в столбце “Actions” и выберите пункт “Удалить”.
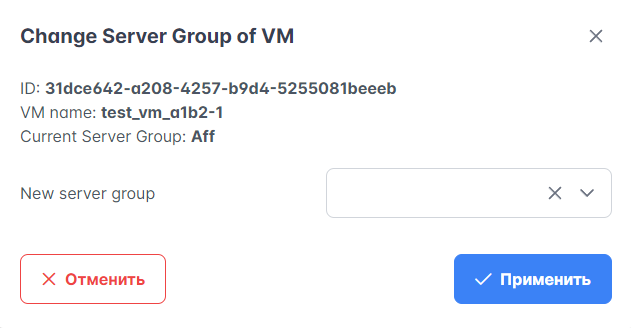
Для добавления ВМ в группу серверов или удаления из нее выполните следующие действия:
На вкладке Ресурсы → ВМ выберите виртуальную машину, которую нужно добавить в группу серверов или удалить из нее. Нажмите “Change Server Group” в столбце “Actions” для этой ВМ.
В открывшемся окне заполните поле “New server group”. Чтобы добавить ВМ в группу, выберите эту группу из выпадающего списка. Чтобы удалить ВМ из группы, нажмите значок X и оставьте поле пустым. Текущая группа ВМ отображается в поле “Current Server Group”.
Удаление ВМ осуществляется в интерфейсе Портала администратора, Horizon или в OpenStack CLI.
Для удаления ВМ в Horizon необходимо выбрать Вычислительные ресурсы → Инстансы в левом меню, далее найти ВМ, которую необходимо удалить, и выбрать в контекстном меню пункт “Удалить инстанс” (см. рисунок ниже).
Рисунок 20 — Удаление ВМ
Если необходимо удалить несколько виртуальных машин, то нужно выбрать их в списке и выбрать в контекстном меню пункт “Удалить” (см. рисунок ниже).
Рисунок 21 — Удаление группы ВМ
Удаление ВМ в CLI выполняется командой serverdelete. Синтаксис команды: openstackserverdelete[--wait]<server>[<server>...]
где:
–wait — дождаться завершения удаления;
<server> [<server> …] — ВМ (список ВМ) для удаления (имя ВМ или ID).
При работе с ВМ с перегруженной памятью компонент Nova по умолчанию использует следующую формулу: Тайм-аут=базовый_тайм-аут(800сек)*объемоперативнойпамяти(ГБ). Таким образом, live-миграция нагруженных ВМ с большим объемом ОЗУ может занимать много времени.
Существует механизм принудительного завершения миграции по истечении тайм-аута, который может использовать два сценария реализации:
Посткопирование (post-copy) — производится перенос ВМ на целевой вычислительный узел и постепенное донесение содержимого оперативной памяти. Работа ВМ до полного переноса памяти проходит в режиме пониженной производительности.
Автоматическая сходимость (auto converge) — если миграция не может завершиться, то компонент начинает замедлять работу процессора ВМ до тех пор, пока процесс копирования памяти не станет быстрее, чем изменение памяти ВМ.
Таким образом, можно оптимизировать процесс live-миграции, подобрав оптимальное время тайм-аута и выбрав предпочтительный сценарий реализации принудительного завершения миграции.
Note
Сценарий механизма администратор может выбрать при инсталляции на свое усмотрение. Для этого в репозитории региона необходимо создать файл config/nova/nova-compute.conf с содержимым:
Администратор задаёт таймаут в секундах в формате целого числа и устанавливает значение True для выбранного сценария.
Также существует возможность принудительной отмены миграции. Когда большая ВМ достаточно долго находится в статусе миграции при live-миграции, становится доступно новое действие — отмена миграции. Это действие можно выполнить с помощью кнопки “Stop migration” в интерфейсе ВМ.
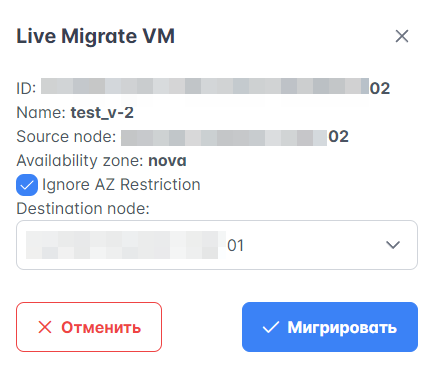
Если у ВМ выставлено свойство availability_zone, при live-миграции этой ВМ не предлагаются хосты (гипервизоры) из других зон доступности. Это можно изменить, выбрав опцию “Ignore AZ restriciton” в интерфейсе ВМ, после чего для миграции станут доступны все хосты, а live-миграция будет проводиться с ключом force.
Чтобы провести live-миграцию ВМ с Портала администратора:
В левом меню Портала перейдите в раздел Ресурсы → ВМ и выберите любую машину из таблицы ВМ.
Нажмите выпадающий список в столбце “Actions” и выберите “Placement management”, а затем “Live Migrate”.
В открывшемся окне поставьте флажок “Ignore AZ restriciton”, выберите нужный гипервизор и нажмите кнопку “Мигрировать”.
Вы можете проводить аварийное восстановление ВМ на Портале администратора. Такие ВМ будут загружены с указанного вами загрузочного образа (обычно с той же ОС, на которой ВМ работает), и к ней будут подключены все ее диски. Статус ВМ изменится на RESCUE.
На вкладке Ресурсы → ВМ выберите виртуальную машину, которую нужно перевести в статус RESCUE. Нажмите “Rescue VM” в столбце “Actions” для этой ВМ.
Заполните поля — пароль и образ. Выбранный образ должен иметь следующие свойства: ‘hw_rescue_device’: ‘disk’ и ‘hw_rescue_bus’: ‘scsi’.
Нажмите кнопку “Запустить”. ВМ перейдет в статус RESCUE, а инстанс будет перезагружен из выбранного образа.
Рисунок 25 — Аварийное восстановление ВМ
Чтобы перевести ВМ обратно в статус ACTIVE, выберите действие “Unrescue VM” в столбце “Actions” для этой ВМ.
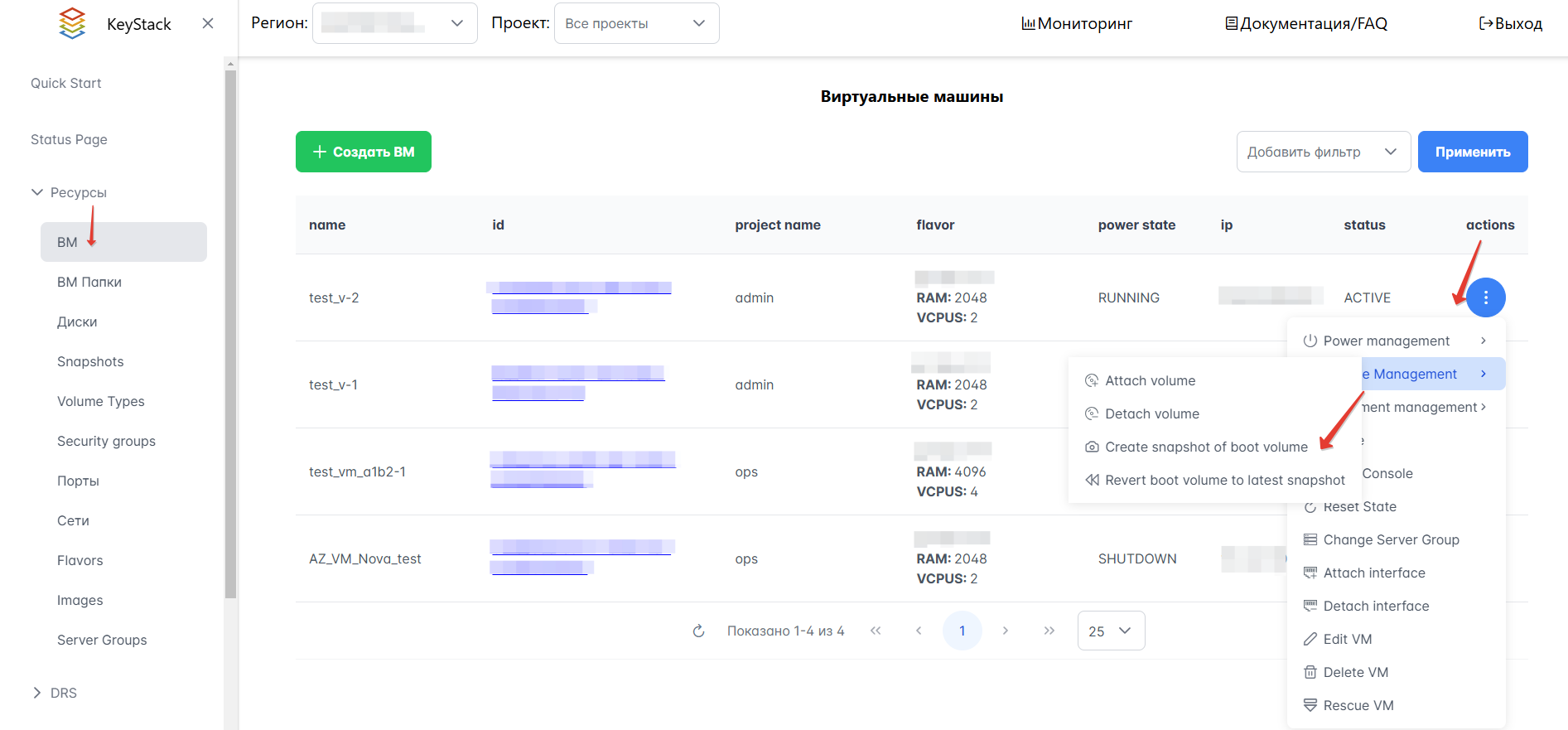
На Портале администратора вы можете создавать моментальные снимки ВМ, чтобы сохранить параметры виртуальных машин и в случае сбоя восстановить машины из этих снимков.
В данный момент технология создания таких снимков ВМ поддерживается только для драйверов Huawei Dorado.
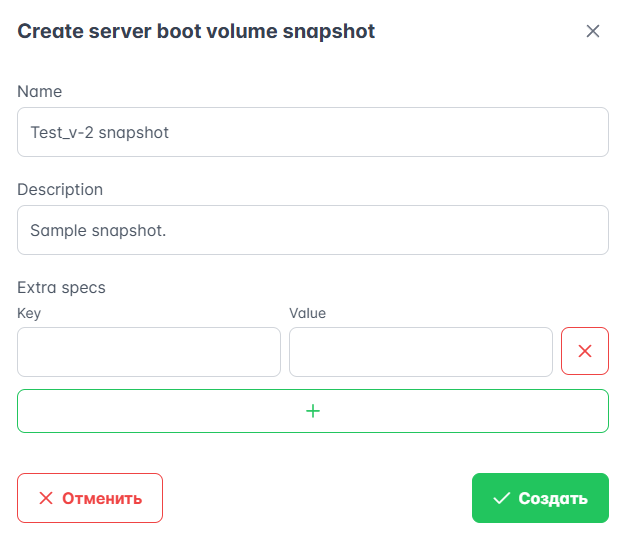
Для создания моментального снимка ВМ:
На вкладке Ресурсы → ВМ выберите виртуальную машину.
Нажмите выпадающий список в столбце “Actions” и выберите “Volume management”, а затем “Create snapshot of boot volume”.
В открывшемся окне укажите имя и название снимка ВМ. Чтобы добавить дополнительные параметры, нажмите + для “Extra specs”. Нажмите “Создать”.
Рисунок 26 — Создание снимка ВМ
Чтобы откатить ВМ к моментальному снимку:
На вкладке Ресурсы → ВМ выберите виртуальную машину.
Нажмите выпадающий список в столбце “Actions” и выберите “Volume management”, а затем “Revert boot volume to latest snapshot”.
В открывшемся окне подтвердите действие. Нажмите “Откатить”.
Рисунок 27 — Восстановление ВМ из снимка
Клонирование существующих виртуальных машин с кастомизацией
Необходимо выполнить следующие действия:
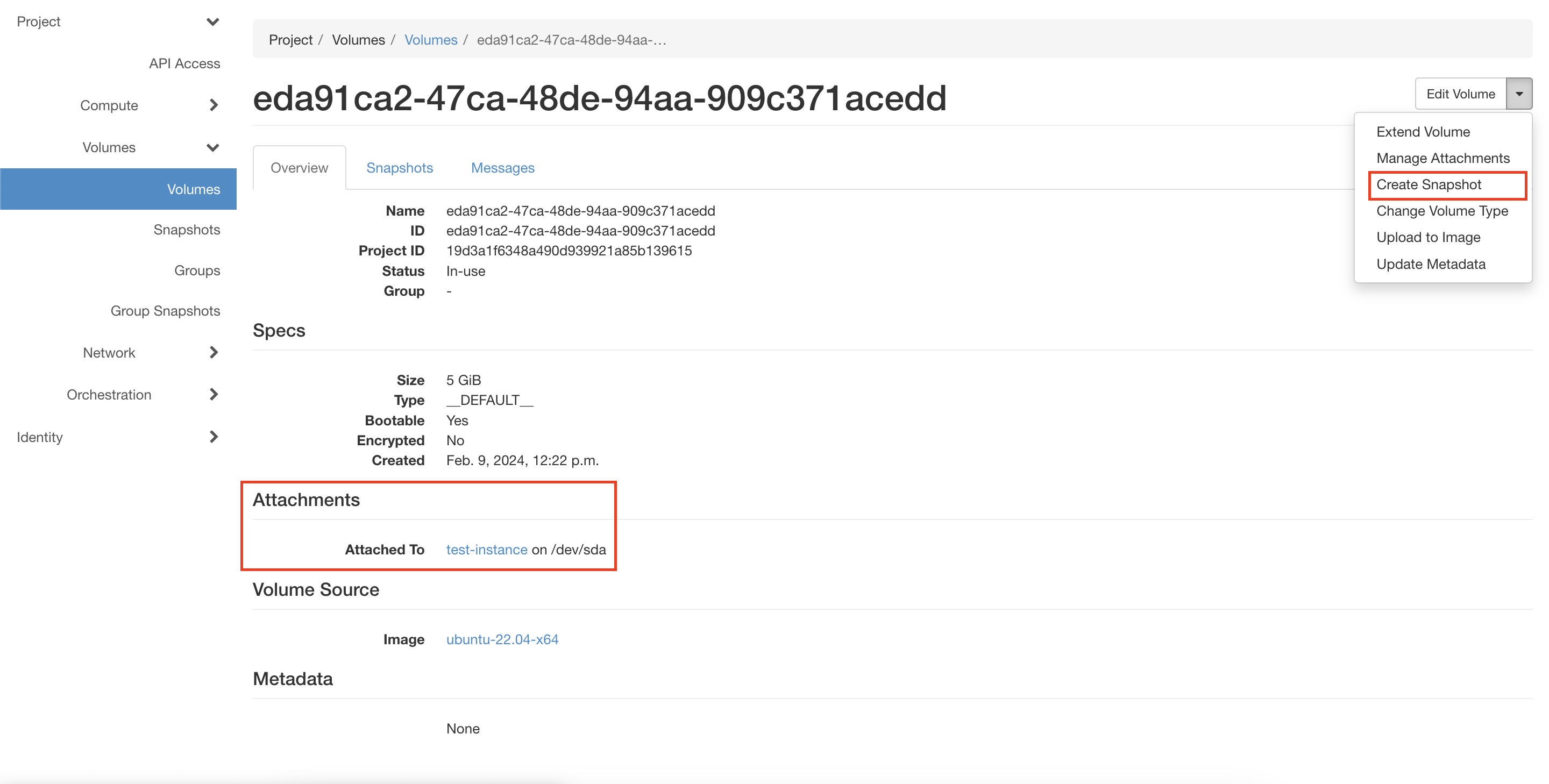
Подключитесь к Порталу самообслуживания.
На странице Project → Volumes → Volumes выберите диск, у которого в колонке “Attached To” указана ВМ, которую нужно скопировать (см. рисунок ниже).
Нажмите выпадающий список в столбце “Actions” и выберите пункт “Create Snapshot”.
Рисунок 28 — Выбор диска
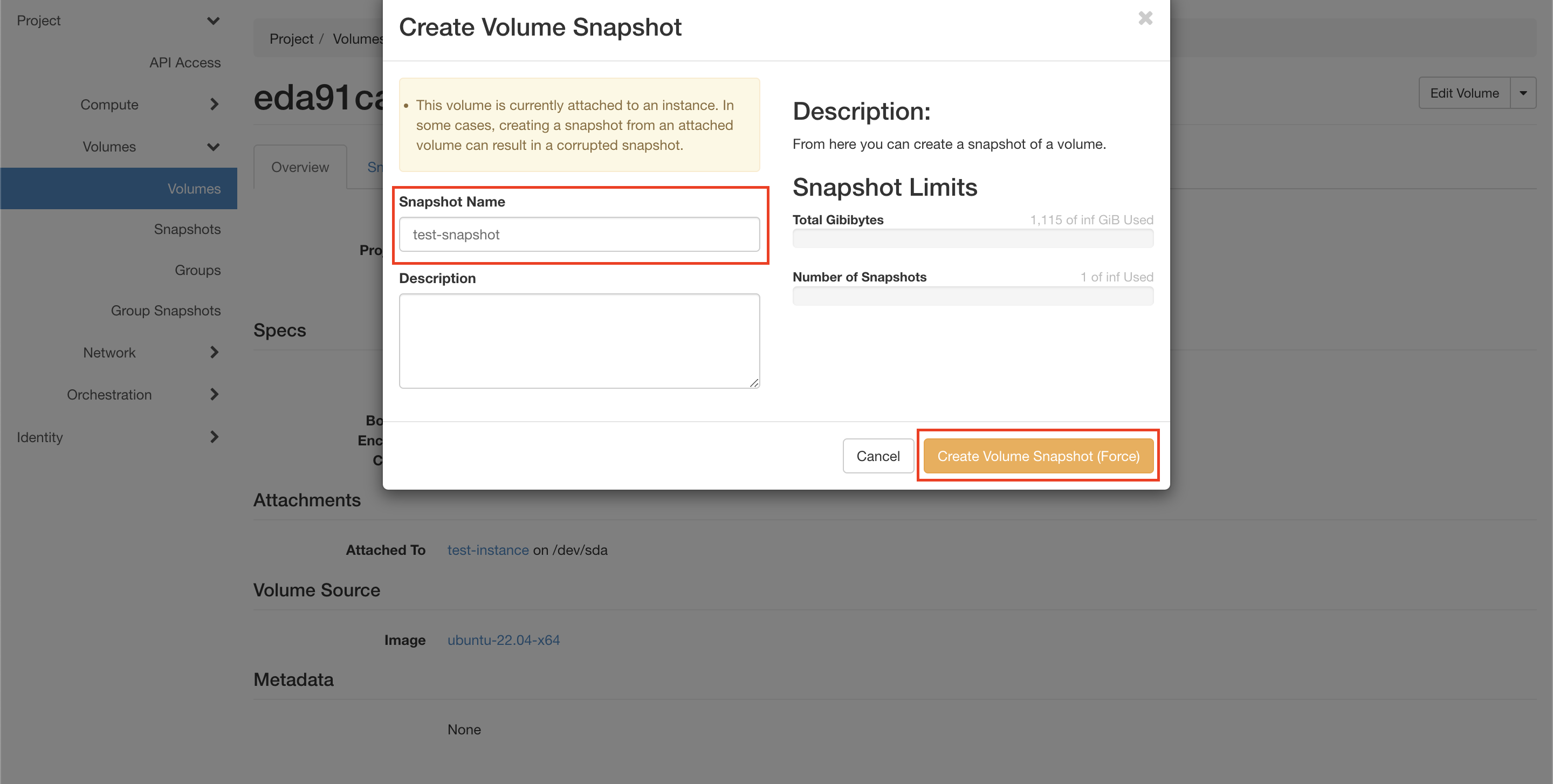
В открывшемся окне введите имя снимка в поле “Snapshot Name” и нажмите кнопку “Create Volume Snapshot (Force)” (см. рисунок ниже).
Рисунок 29 — Создание снимка
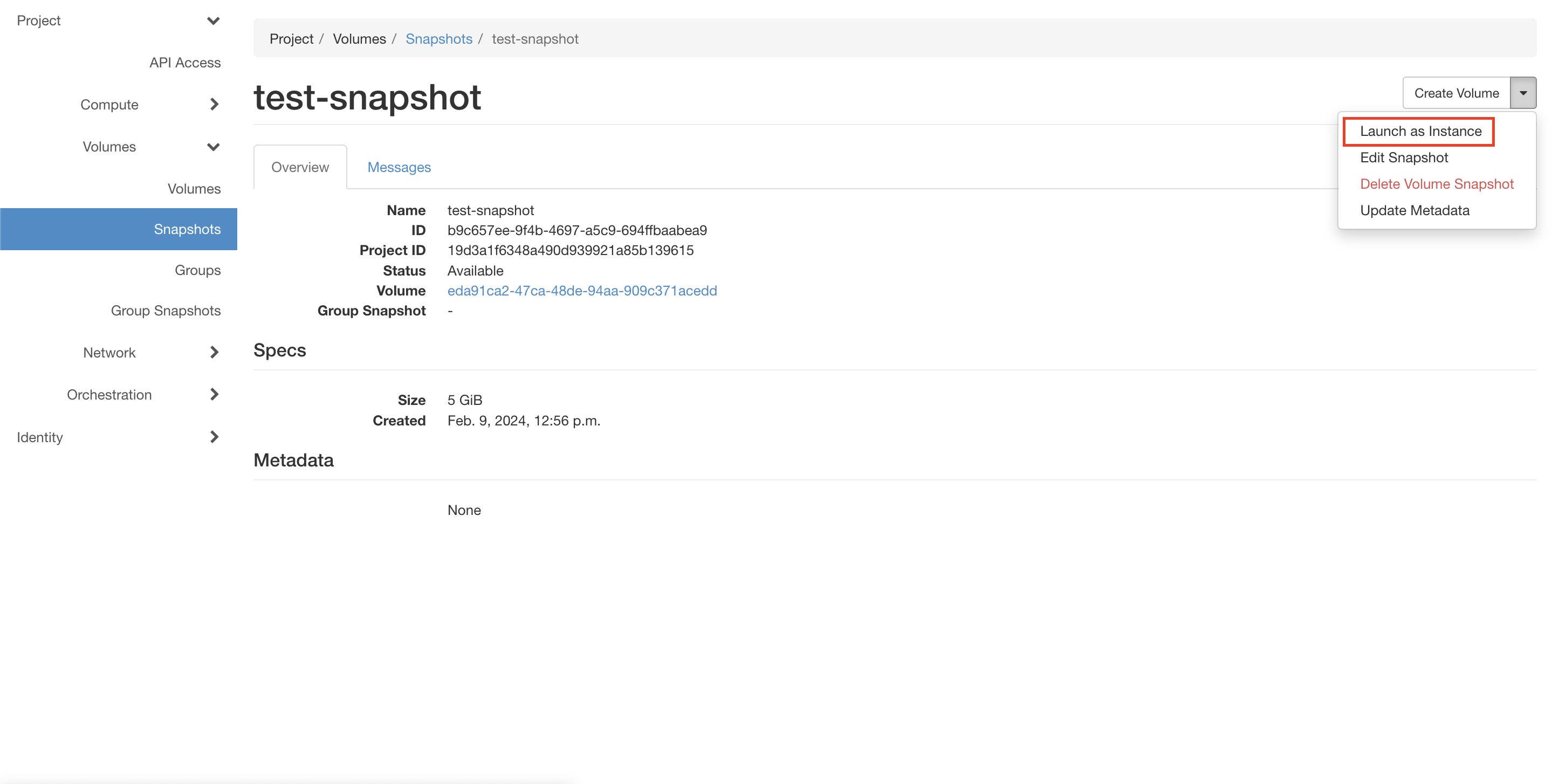
На странице Project → Volumes → Snapshots нажмите выпадающий список в столбце “Actions” в строке тестового снимка.
Выберите пункт “Launch as Instance” (см. рисунок ниже).
Вкладка Configuration: LoadCustomizationScriptfromafile:Загрузитьконфигурационныйскриптввидефайла или CustomizationScript:Ввестиконфигурационныйскриптвполевводатекста
В качестве примера конфигурационного скрипта можно привести следующий скрипт:
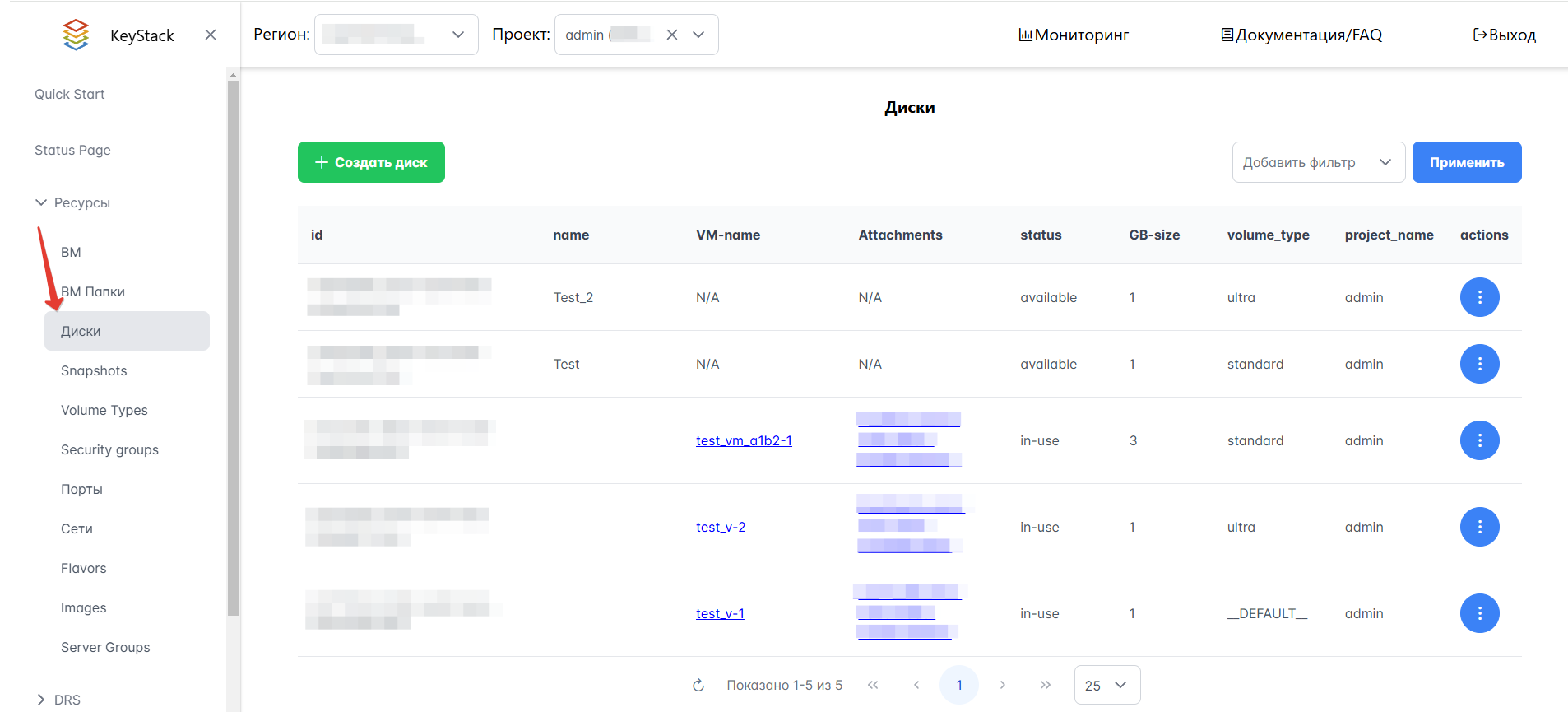
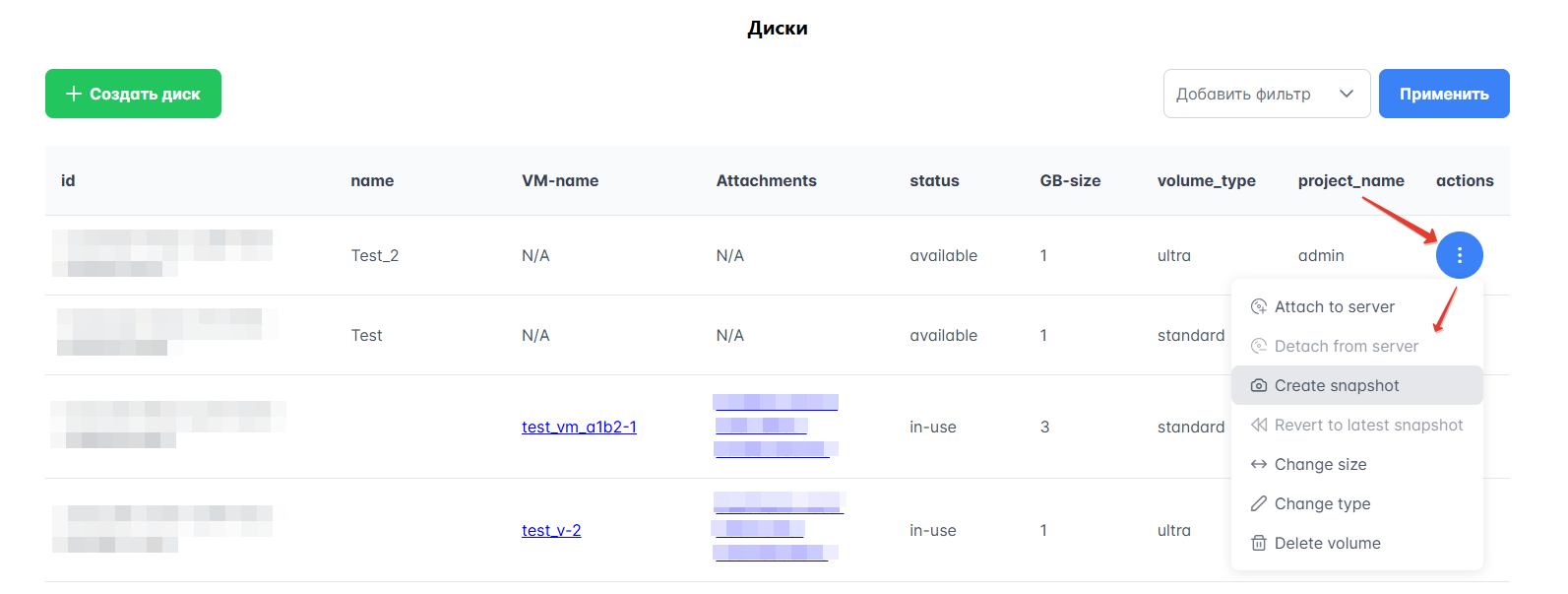
Для просмотра списка дисков на Портале необходимо в левом меню перейти в раздел Ресурсы → Диски. Пример вида раздела представлен на рисунке ниже.
Рисунок 31 — Пример списка дисков
Создание диска
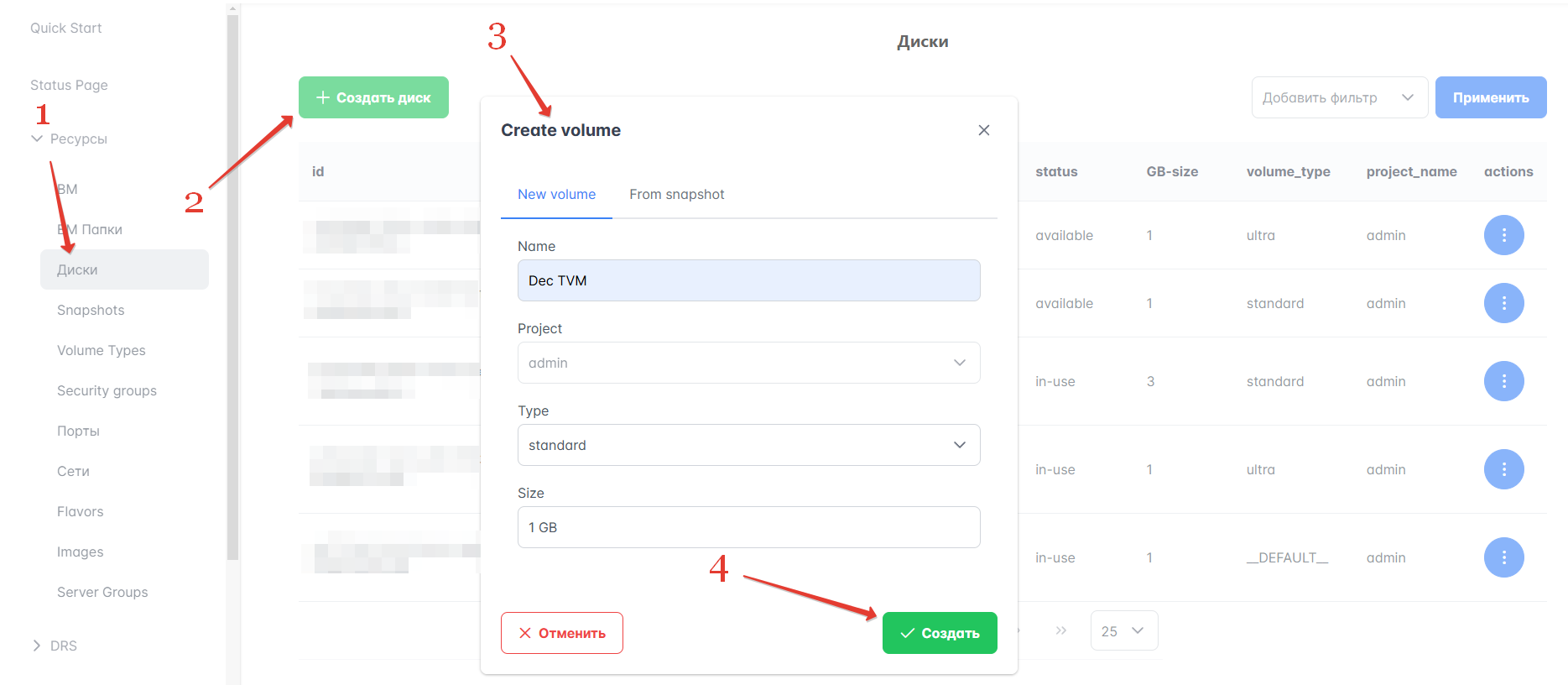
Для создания диска на Портале администратора выполните следующие действия:
В левом меню Портала перейдите в раздел Ресурсы → Диски.
Нажмите кнопку “Создать диск”.
Укажите имя и размер диска. Проект для диска можно изменить в выпадающем списке “Проект” вверху. Пример заполнения см. на рисунке ниже. Чтобы создать диск из снимка, перейдите на вкладку From snapshot и выберите один из доступных снимков в поле Snapshot.
Нажмите кнопку “Создать”.
Рисунок 32 — Создание диска
Изменение параметров диска
Для внесения изменений в параметры диска выполните следующие действия:
В левом меню Портала перейдите в раздел Ресурсы → Диски.
Нажмите выпадающий список в столбце “Actions” и выберите нужный пункт в зависимости от цели:
Чтобы изменить размер диска, нажмите “Change size”. Новый размер должен быть больше текущего значения. В открывшемся окне укажите размер диска в ГБ и нажмите “Сохранить”.
Чтобы удалить диск, нажмите “Delete volume”. Чтобы удалить вместе с диском все снимки, выберите опцию “Remove any snapshots along with the volume”. Подтвердите действие, нажав “Удалить”.
Чтобы изменить тип томов, к которому принадлежит диск, нажмите типа “Change type”. В открывшемся окне выберите тип в поле “Type”. Если планируете миграцию диска, поменяйте значение с “Never” на “On demand” в “Migrate the volume when it is re-typed”. Нажмите “Применить”.
Если диск не прикреплен к ВМ, нажмите “Attach to server”. В открывшемся окне выберите ВМ в поле “Сервер”. Чтобы при удалении ВМ был удален и этот диск, выберите опцию “Delete on termination”. Нажмите “Прикрепить”.
Для работы с QoS на Портале администратора необходимо перейти в раздел Ресурсы → Volume Types в левом меню.
Volume Types
Типы томов необходимы для логического объединения дисков, включенных в определенный том.
По умолчанию Платформа использует тип томов __DEFAULT__. Другие типы томов можно создавать на свое усмотрение. Прежде чем устанавливать параметры QoS, убедитесь, что созданы нужные типы томов. Для просмотра типов томов перейдите в раздел Ресурсы → Volume Types.
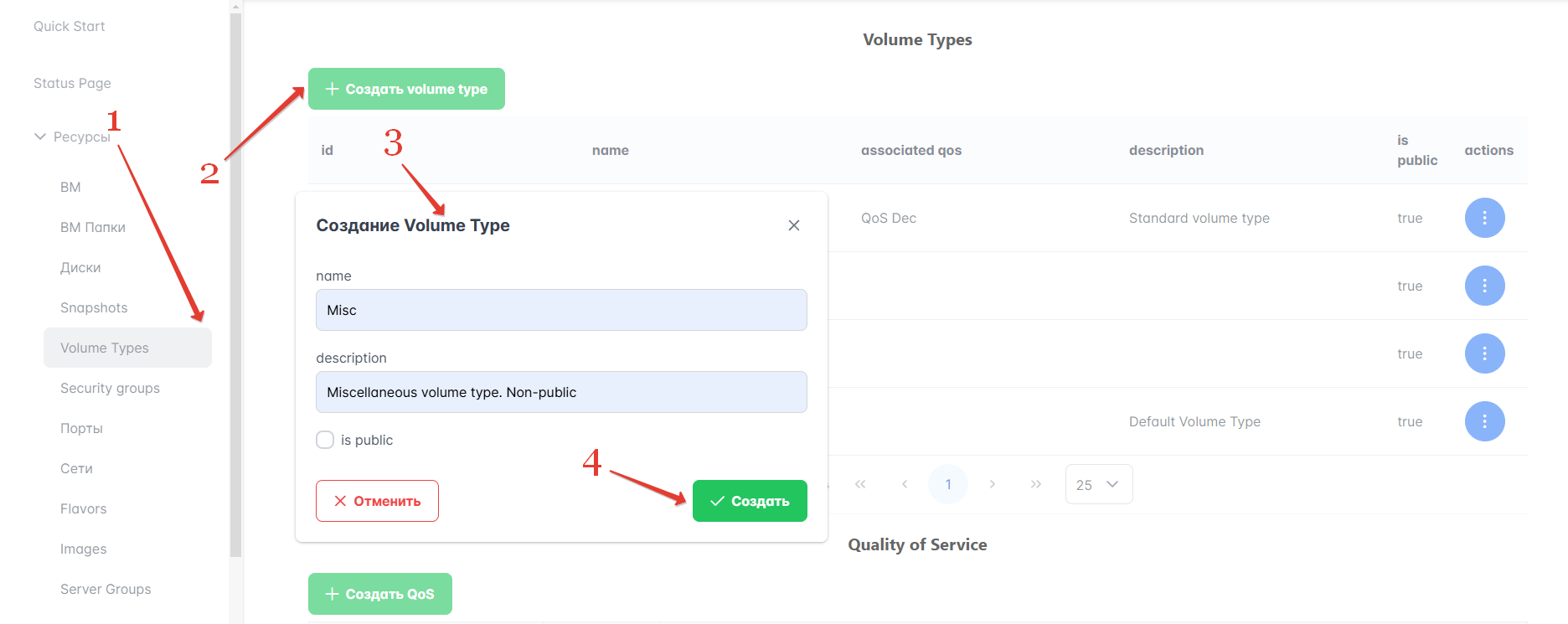
Для создания нового типа томов выполните следующие действия:
В левом меню Портала перейдите в раздел Ресурсы → Volume Types.
Нажмите кнопку “Создать volume type”, расположенную рядом с таблицей Volume Types.
Введите имя и описание типа томов. Чтобы создать приватный тип, доступный только администраторам, снимите флажок для опции “is public”. Эти параметры можно изменить позже для уже созданного типа. Для этого нажмите выпадающий список в столбце “Actions” и выберите “Edit”.
Нажмите кнопку “Создать”.
Рисунок 34 — Создание типа томов
Quality of Service
Quality of Service (QoS) для дисков и томов — это квоты на производительность. QoS регулируют параметры производительности оборудования.
Создавайте QoS, настраивайте их параметры и связывайте их с типами дисков в этом разделе. Таблица Volume Types выше отобразит QoS, связанные с типами томов, в столбце “associated qos”.
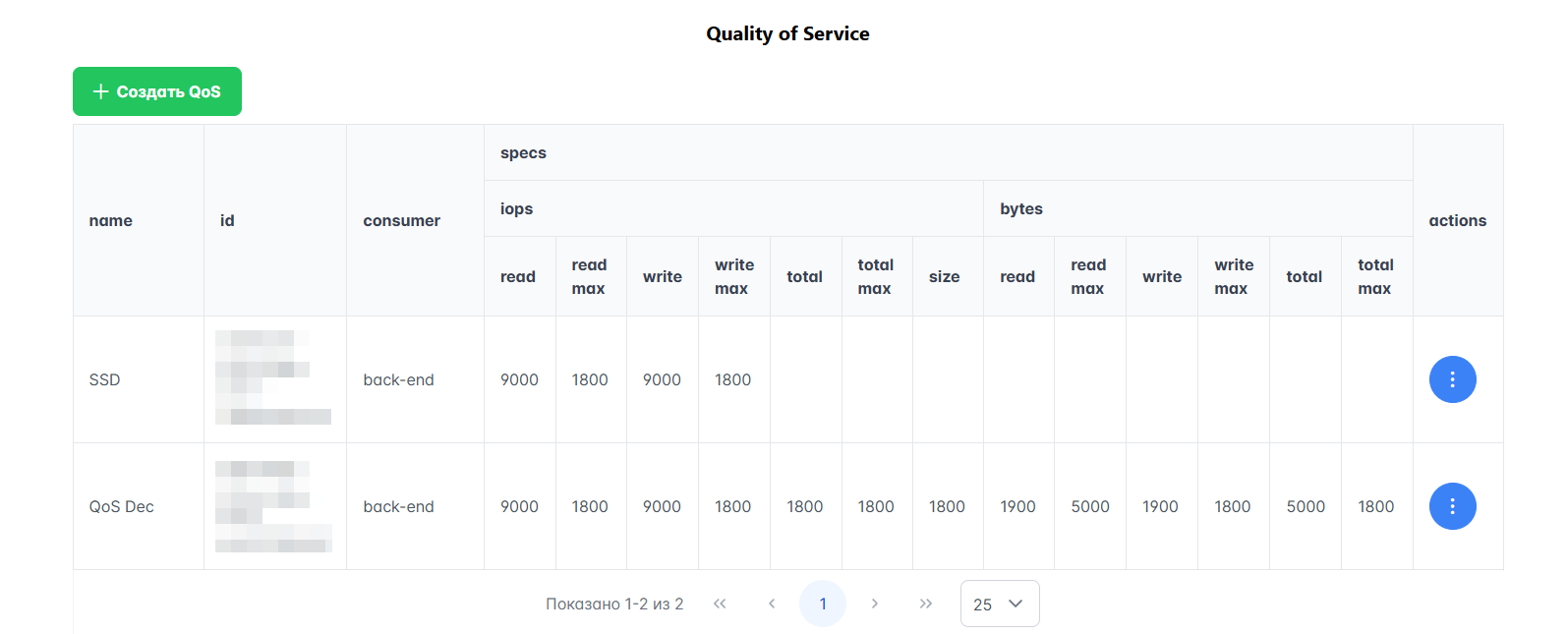
Для создания нового QoS выполните следующие действия:
В левом меню Портала перейдите в раздел Ресурсы → Volume Types.
Нажмите кнопку “Создать QoS”, расположенную рядом с таблицей Quality of Service.
Заполните все поля. Эти параметры можно изменить позже, нажав выпадающий список в столбце “Actions” и выбрав “Update”.
Нажмите кнопку “Создать”.
Рисунок 35 — QoS
Для изменения QoS выполните следующие действия:
В разделе Ресурсы → Volume Types перейдите к таблице Quality of Service.
Нажмите выпадающий список в столбце “Actions” и выберите нужный пункт в зависимости от цели:
Чтобы изменить значения параметров QoS, нажмите “Update”. В открывшемся окне укажите новые значения для существующих параметров и нажмите “Применить”.
Если какие-либо параметры QoS еще не указаны, добавьте их с помощью “Add specs”. В открывшемся окне заполните значения для новых параметров и нажмите “Применить”.
Чтобы удалить параметры у QoS, нажмите “Unset”. Выберите один из параметров в открывшемся окне и нажмите “Удалить”. Повторите для всех параметров, которые нужно удалить.
Чтобы удалить QoS, нажмите “Delete”. Подтвердите действие, нажав “Удалить”.
Чтобы привязать QoS к типу томов, выберите “Associate”. В открывшемся окне выберите тип и нажмите “Применить”. Повторите для всех типов, которые нужно привязать к QoS.
Чтобы отвязать QoS от типа томов, выберите “Disassociate”. В открывшемся окне выберите тип и нажмите “Применить”.
Чтобы отвязать QoS от всех типов томов, выберите “Disassociate all”. Подтвердите действие, нажав “Применить”.
На Портале администратора вы можете создавать моментальные снимки дисков, чтобы сохранить данные виртуальных машин на этих дисках и в случае сбоя восстановить машины из этих снимков.
В данный момент технология создания таких снимков дисков поддерживается только для драйверов Huawei Dorado.
Для создания моментального снимка диска:
На вкладке Ресурсы → ВМ выберите виртуальную машину.
Нажмите выпадающий список в столбце “Actions” и выберите “Volume management”, а затем “Create snapshot of boot volume”.
В открывшемся окне укажите имя и название снимка ВМ. Чтобы добавить дополнительные параметры, нажмите + для “Extra specs”. Нажмите “Создать”.
Рисунок 36 — Создание снимка диска
Чтобы откатить ВМ к моментальному снимку:
На вкладке Ресурсы → ВМ выберите виртуальную машину.
Нажмите выпадающий список в столбце “Actions” и выберите “Volume management”, а затем “Revert boot volume to latest snapshot”.
В открывшемся окне подтвердите действие. Нажмите “Откатить”.
Для этого нужно добавить в Netbox (пароль можно посмотреть в Vault в разделе Accounts) https://netbox.<domain_name>/dcim/devices/ новое устройство (см. рисунок ниже).
Рисунок 38 — Добавление нового устройства в Netbox
Затем необходимо заполнить поля:
Name — имя сервера;
Device role — Server;
Device type — выбрать соответствующий тип;
Site — выбрать соответствующий сайт, например, ks-region1;
Status — Active;
Tenant — выбрать тенант;
Role — выбрать роль в выпадающем списке (controller, compute или network);
Status — Ready.
После того как устройство будет добавлено, зайдите в него и добавьте сетевые интерфейсы аналогично тому, как изображено на рисунке ниже.
Рисунок 39 — Добавление сетевых интерфейсов
Теперь можно устанавливать операционную систему. Для этого требуется запустить пайплайн https://<gitlab_url>/project_k/Deployments/baremetal/-/pipelines и поменять значения для следующих параметров:
TARGET_ROLE — compute, controller или network;
TARGET_CLOUD — ks-region1;
IRONIC_IMAGE_URL — во всех сценариях, кроме TARGET_ROLE=network, оставить как есть, в противном случае — указать http://LCM_IP:8080/ubuntu-20.04-mellanox-keystack.qcow2.
Нужно добавить новый сервер в inventory соответствующего окружения в gitlab.domain_name в группу compute https://<gitlab_url>/project_k/deployments/stage1/-/blob/dev-stage1/inventory (пример для stage1).
Run pipeline → Run pipeline → deploy c указанием –limit на новый гипервизор.
Проверьте, что гипервизор функционирует, как ожидается — создаются виртуальные машины, работает миграция, работает сетевая связность — доступ по SSH до тестовых виртуальных машин:
Создайте виртуальную машину на требуемом гипервизоре через CLI:
Проверьте, что она создалась и перешла в статус ACTIVE, через openstackservershow<server_id>.
Добавьте к ней FIP и проверить SSH-доступ (должно быть соответствующее разрешающее правило).
Убедитесь, что виртуальную машину можно мигрировать (миграция ВМ возможна такая: Mirantis → Keystack или Keystack → Keystack). Сделать это можно через CLI:
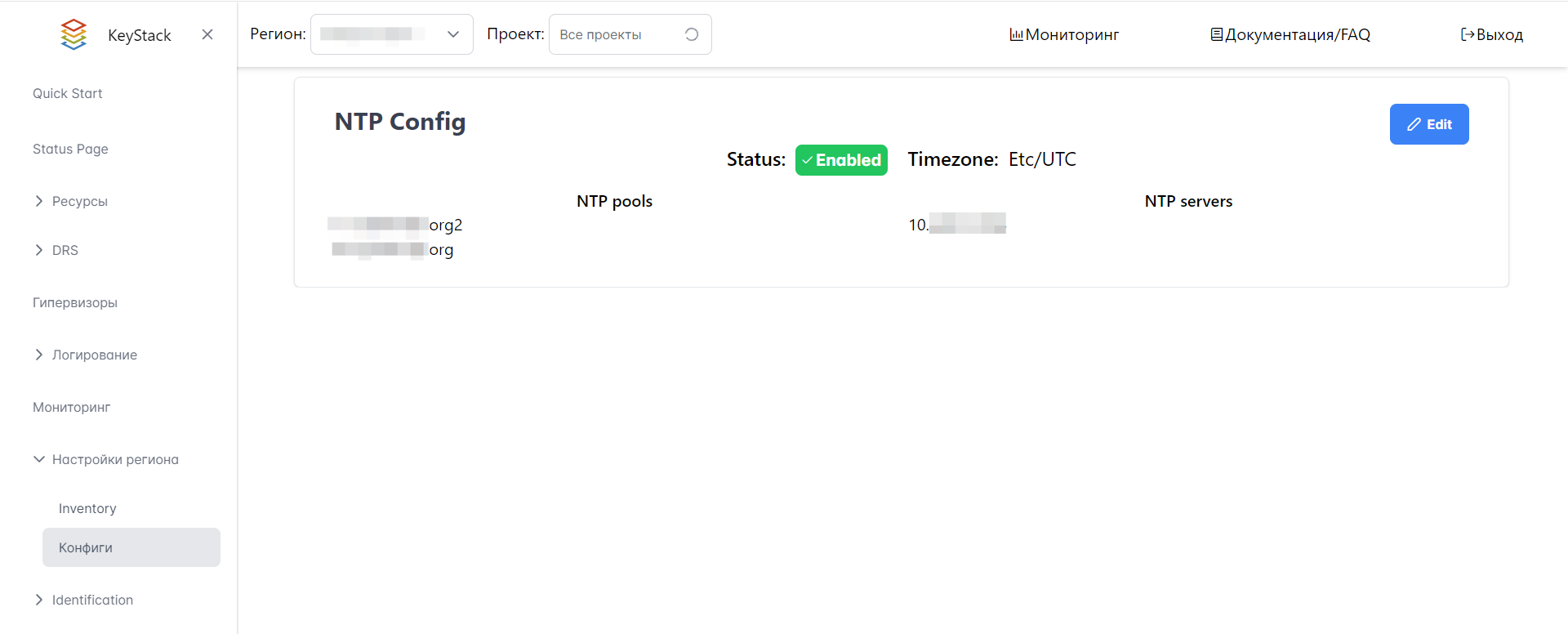
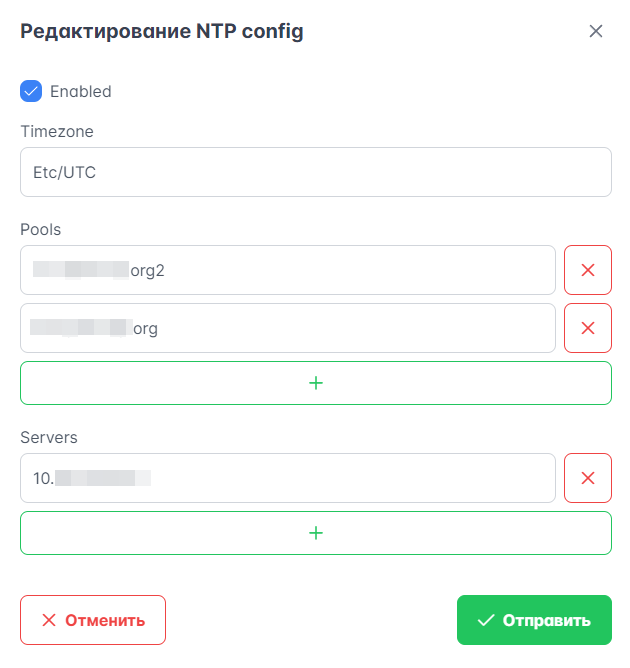
На Портале администратора можно просматривать и менять некоторые настройки серверов NTP (Network Time Protocol).
Рисунок 40 — NTP Config
Для внесения изменений в файл конфигурации NTP нажмите кнопку “Edit”. Можно добавлять, изменять и удалять следующие настройки:
часовой пояс;
пулы;
серверы.
Флажок “Enabled” отображает статус файла конфигурации.
Рисунок 41 — Изменение настроек NTP Config
Изменения файла на Портале администратора передаются в GitLab и там сохраняются. Для того, чтобы применить настройки, их нужно запустить с помощью пайплайна, применив bootstrap-servers и host configs.
Run pipeline → Run pipeline → bootstrap-servers → host configs.
Режим обслуживания вычислительных узлов (гипервизоров)
Для обслуживания вычислительного узла (гипервизора) предусмотрен механизм временного отключения узла из кластера.
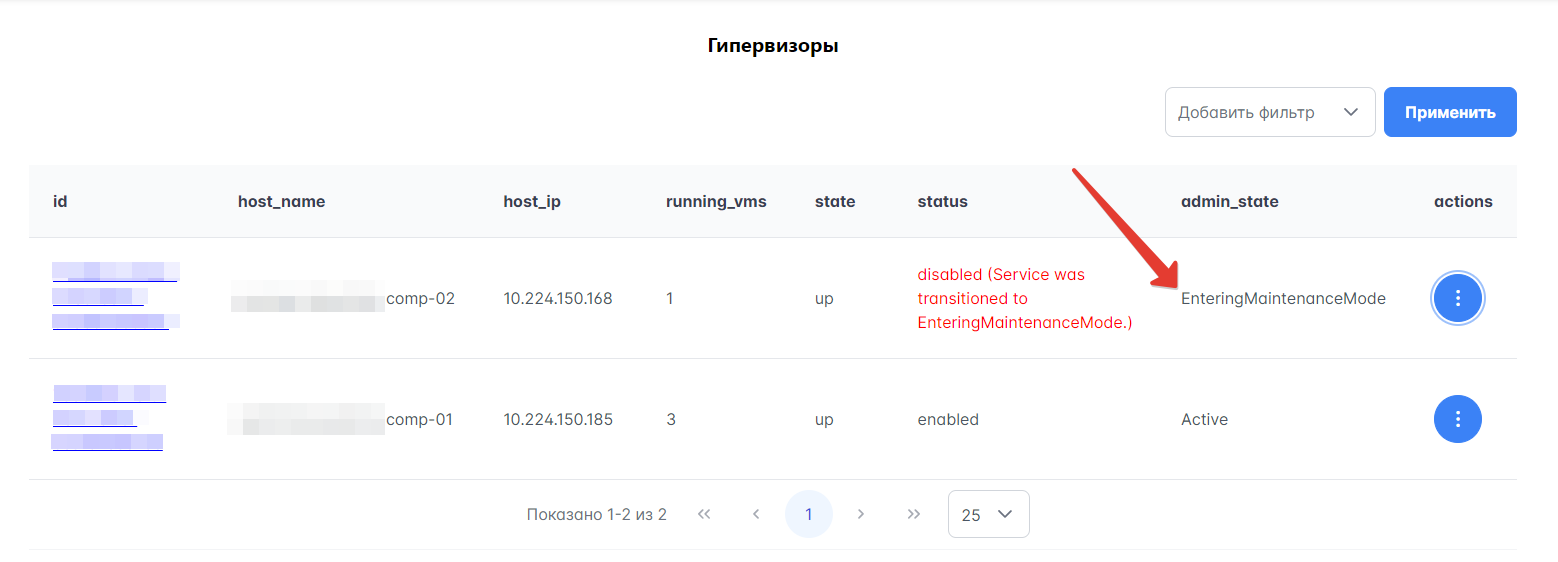
На Портале администратора можно отследить процесс перехода гипервизора в режим обслуживания (maintenance mode). Для этого нужно перейти в раздел Гипервизоры → Гипервизоры и посмотреть значение в столбце “admin_state”. При выборе действия “Enable maintenance mode” гипервизор переходит в режим обслуживания, а статус и значение “admin_state” меняется на EnteringMaintenanceMode.
Перевод вычислительного узла в режим обслуживания
Для перевода узла в режим обслуживания необходимо выполнить следующие действия:
На Портале администратора перейдите в раздел Гипервизоры → Гипервизоры.
В выпадающем списке “Actions” для этого узла выберите действие “Enable maintenance mode”. ВМ при таком состоянии продолжают работать на узле, а новые ВМ не могут быть запущены.
На рисунке ниже показан процесс перевода гипервизора в maintenance mode.
Рисунок 42 — Вычислительные узлы с возможностью отключения
Дождитесь, когда статус гипервизора сменится с EnteringMaintenanceMode на новый. Если по какой-то причине гипервизор не перешел в maintenance mode, это будет отображено в статусе так: disabled(ServicewastransitionedtoError.). В столбце “admin_state” будет описана причина — например, Error(LivemigrationofserverNfailed). В таком случае можно либо повторно попробовать перевести гипервизор в режим обслуживания, нажав “Enable maintenance mode” — либо вернуть его в статус “enabled”, выбрав “Enable Service”.
В процессе перехода в режим обслуживания все ВМ с данного узла мигрируют на другие узлы, включенные без прерывания их работы.
Если гипервизор переведен в режим обслуживания, эвакуация ВМ происходит параллельно. Примерно 3-5 машин могут быть эвакуированы за раз. При этом в качестве причины отключения узла (disable_reason) выставляется maintenancemode: disable_service_by_uuid(token,service_id,reason='maintenancemode',region=region).
После перехода в режим обслуживания вычислительный узел можно отключать от сети, выключать по питанию и производить работы по ремонту или модернизации.
Агрегат (host aggregate) — это группа вычислительных узлов, объединенных логически на основе таких характеристик, как аппаратные средства или показатели производительности. Один вычислительный узел можно назначить как одному, так и нескольким агрегатам.
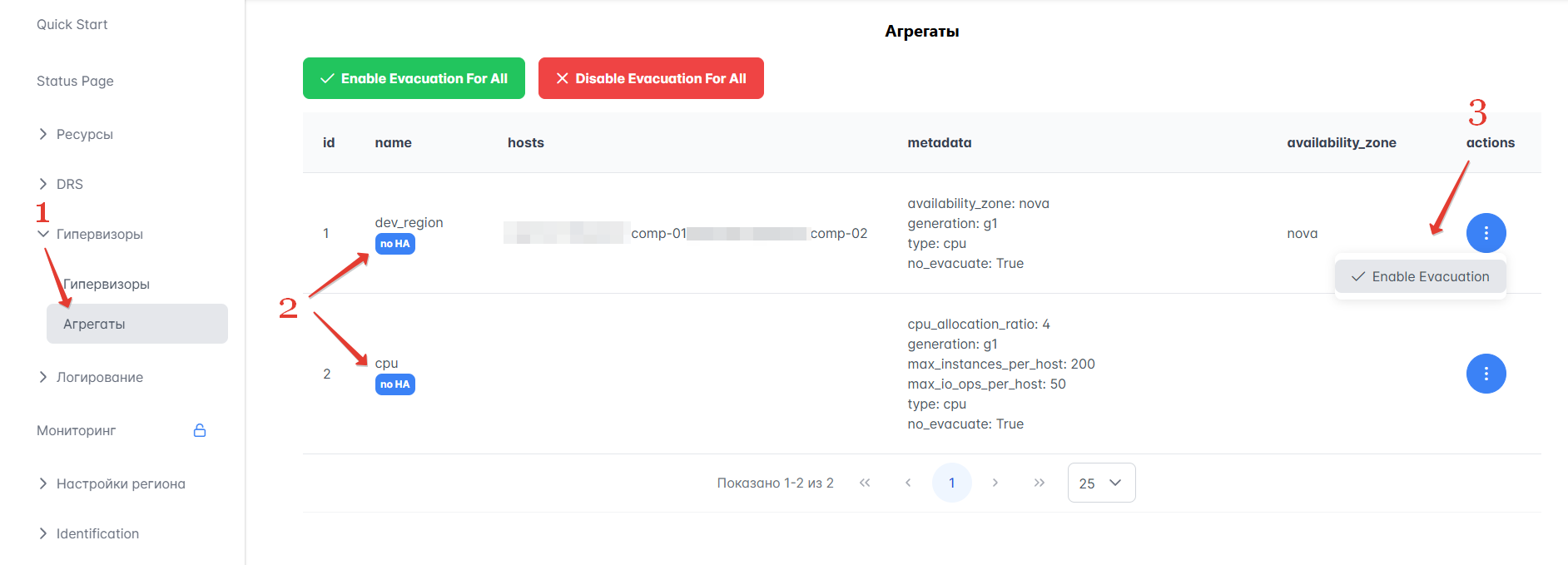
На Портале администратора список агрегатов доступен в разделе Гипервизоры → Агрегаты. Вы можете переводить агрегаты в режим высокой доступности (high availability, или HA) и тем самым эвакуировать их. Если для агрегата не включен режим HA, возле его название есть лейбл noHA.
Для перевода агрегата в режим HA выполните следующие действия:
Перейдите в раздел Гипервизоры → Агрегаты.
Посмотрите, какие агрегаты отмечены лейблом noHA. Эти агрегаты вы сможете эвакуировать.
Переведите один или несколько агрегатов в режим HA:
Чтобы эвакуировать конкретный агрегат, выберите “Enable evacuation” в выпадающем списке “Actions” для этого агрегата. На рисунке ниже приведен пример.
Чтобы эвакуировать все агрегаты, нажмите кнопку “Enable Evacuation For All” вверху.
Рисунок 43 — Эвакуация агрегатов
Подтвердите действие, нажав “Включить” в открывшемся окне.
Для вывода агрегатов из режима HA повторите действия выше с тем отличием, что в выпадающем списке “Actions” нужно будет выбрать “Disable evacuation”, а при выборе всех агрегатов — нажать кнопку “Disable Evacuation For All”.
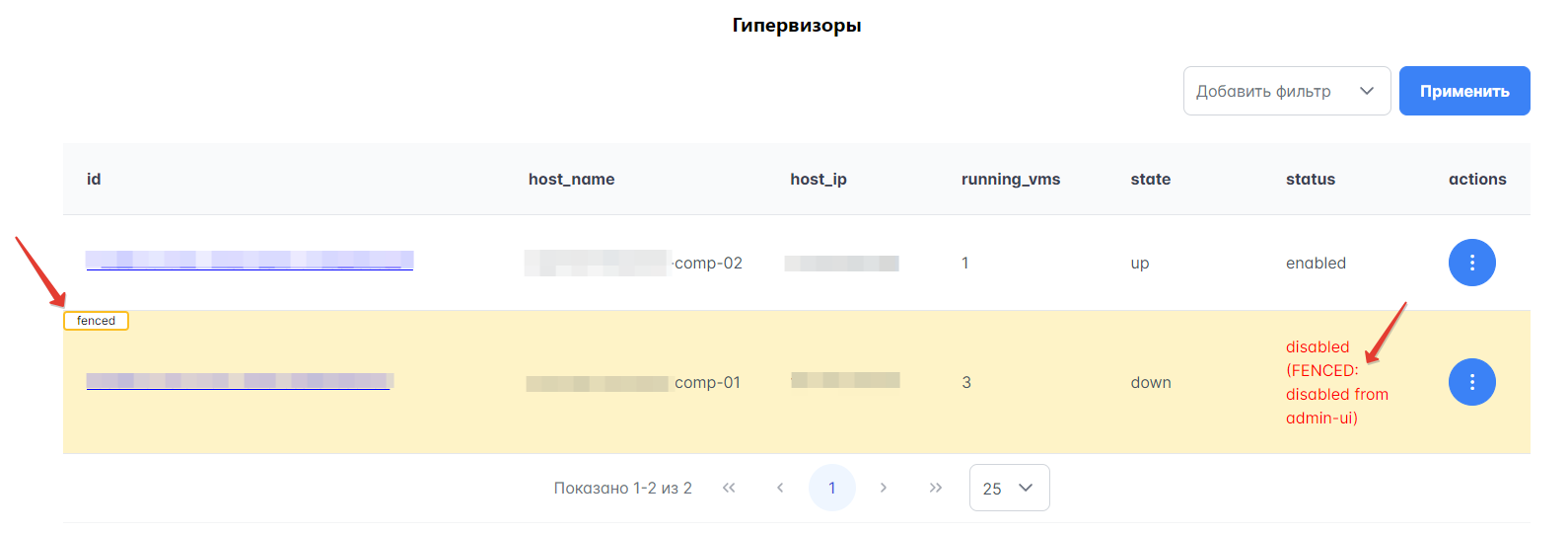
Фенсинг узлов (гипервизоров) проводит HA. Фенсинг — механизм исключения неисправного узла из кластера, чтобы этот узел больше не работал с ВМ. После проведения фенсинга узлы могут оказаться в статусе “fenced”, что будет отражено на Портале администратора. Такие узлы опознаются по префиксу FENCED:``в``disabled_reason.
Чтобы вывести узлы из этого состояния, выполните следующие действия:
В левом меню Портала перейдите в раздел Гипервизоры → Гипервизоры.
Найдите в таблице узел, который выделен желтым цветом и обозначен лейблом “fenced”.
В выпадающем списке “Actions” для этого узла выберите действие “Disable Fence Mode”.
Для просмотра настроек виртуальной сети могут использоваться интерфейсы Портала администратора, Horizon или OpenStack CLI.
Для просмотра настроек виртуальной сети в Horizon необходимо выполнить следующие действия:
Перейдите в раздел Проект → Сети. Будет отображен список сетей, к которым имеет доступ данный проект.
Рисунок 45 — Список сетей проекта
Перейдите в карточку виртуальной сети щелчком мыши по ее названию. Вид раздела настроек виртуальной сети представлен на рисунке ниже.
Рисунок 46 — Отображение настроек виртуальной сети
Для просмотра виртуальной сети с помощью клиента Openstack CLI необходимо подключиться по протоколу SSHv2 к управляющему узлу control1 и выполнить следующую команду в контейнере kolla_toolbox:
openstacknetworkshow<имя_виртуальной_сети>
Для просмотра свойств подсетей (subnet) с помощью клиента Openstack CLI необходимо выполнить команду в контейнере kolla_toolbox:
openstacksubnetshow<имя_subnet>
Создание виртуальной сети и соответствующей ей подсети
Для создания сети используется команда openstacknetworkcreate. Полный синтаксис команды:
–project <project> — проект владельца (наименование или ID);
–project-domain <project-domain> — домен проекта (наименование или ID). Опция используется в случае конфликтов между названиями проектов;
–subnet-pool <subnet-pool> — пул адресов, из которого эта подсеть получит CIDR (наименование или идентификатор);
–prefix-length <prefix-length> — длина префикса для выделения подсети из пула подсетей;
–subnet-range <subnet-range> — диапазон подсети в нотации CIDR (требуется, если –subnet-pool не указан, в противном случае — необязательный);
–dhcp — разрешить DHCP (по умолчанию);
–no-dhcp — запретить DHCP;
–dns-publish-fixed-ip — включить публикацию фиксированных IP-адресов в DNS;
–no-dns-publish-fixed-ip — отключить публикацию фиксированных IP-адресов в DNS;
–gateway <gateway> — шлюз подсети. Доступны три варианта:
<ip-address> — конкретный IP-адрес для использования в качестве шлюза — например, –gateway 192.168.9.1,;
‘auto’ — адрес шлюза должен автоматически выбираться из самой подсети — например, –gateway auto;
‘none’ — подсеть не использует шлюз — например, –gateway none.
–ip-version <IP_VERSION> — версия IP (значение по умолчанию — 4). Версия 6 не доступна в Платформе;
–network-segment <network-segment> — сегмент сети, который нужно связать с этой подсетью (наименование или ID);
–network <network> — сеть, к которой принадлежит эта подсеть (наименование или ID);
–description <description> — описание подсети;
–allocation-pool start=<ip-address>,end=<ip-address> — IP-адреса пула распределения для этой подсети — например, start = 192.168.199.2, end = 192.168.199.254. Можно использовать несколько раз для добавления нескольких пулов;
–dns-nameserver <dns-nameserver> — DNS-сервер для этой подсети. Можно использовать несколько раз для указания нескольких DNS;
–host-route destination=<subnet>,gateway=<ip-address> — дополнительный маршрут для этой подсети — например, destination=10.10.0.0/16,gateway=192.168.71.254. Можно использовать несколько раз для добавления нескольких маршрутов;
–service-type <service-type> — тип сервиса для подсети — например, network:floatingip_agent_gateway. Можно использовать несколько раз для указания нескольких типов сервиса;
–tag <tag> — теги подсети. Можно использовать несколько раз для добавления нескольких тегов;
–dns-publish-fixed-ip — включить публикацию фиксированных IP-адресов в DNS;
–no-dns-publish-fixed-ip — отключить публикацию фиксированных IP-адресов в DNS;
–gateway <gateway> — шлюз подсети. Доступны три варианта:
<ip-address> — конкретный IP-адрес для использования в качестве шлюза — например, –gateway 192.168.9.1,;
‘auto’ — адрес шлюза должен автоматически выбираться из самой подсети — например, –gateway auto;
‘none’ — подсеть не использует шлюз — например, –gateway none.
–network-segment <network-segment> — сегмент сети, который нужно связать с этой подсетью (имя или ID). Разрешается устанавливать сегмент, если текущее значение — None. Сеть также должна иметь только один сегмент, и только одна подсеть может существовать в сети;
–description <description> — установить описание подсети;
–tag <tag> — теги подсети. Можно использовать несколько раз для добавления нескольких тегов;
–no-tag — очистить теги подсети. Указывается как –tag, так и –no-tag, чтобы перезаписать текущие теги;
–allocation-pool start=<ip-address>,end=<ip-address> — IP-адреса пула для этой подсети — например, start = 192.168.199.2, end = 192.168.199.254. Можно указывать несколько раз для добавления нескольких пулов адресов;
–no-allocation-pool — удалить пулы из этой подсети. Указывается как –allocation-pool, так и –no-allocation-pool, чтобы перезаписать информацию о текущем пуле;
–dns-nameserver <dns-nameserver> — DNS-сервер для этой подсети. Можно использовать несколько раз для указания нескольких DNS-серверов;
–no-dns-nameservers — удалить информацию о DNS-серверах в этой подсети. Необходимо использовать –no-dns-nameserver и –dns-nameserver, чтобы перезаписать информацию о DNS-серверах;
–host-route destination=<subnet>,gateway=<ip-address> — – дополнительный маршрут для этой подсети — например, destination=10.10.0.0/16,gateway=192.168.71.254. Можно использовать несколько раз для добавления нескольких маршрутов;
–no-host-route — очистить информацию о маршрутах для этой подсети. Необходимо использовать -no-host-route и –host-route, чтобы перезаписать информацию о маршрутах;
–service-type <service-type> — тип сервиса для подсети — например, network:floatingip_agent_gateway. Можно использовать несколько раз для указания нескольких типов сервиса;
Балансировщики проекта отображаются при переходе в левом меню в раздел Сеть → Балансировщики нагрузки.
Рисунок 48 — Список балансировщиков проекта
Для запуска мастера создания балансировщика нажмите кнопку “Создать балансировщик нагрузки”.
В окне мастера создания балансировщика укажите имя балансировщика, выберите сеть.
Рисунок 49 — Создание балансировщика
Добавьте информацию о слушателе — заполните поля “Имя”, “Протокол” и “Порт” (см. рисунок ниже).
Рисунок 50 — Заполнение информации о слушателе
Далее необходимо заполнить информацию о пуле (см. рисунок ниже).
Рисунок 51 — Заполнение информации о пуле
В настоящий момент балансировщик поддерживает три основных алгоритма балансировки:
LEAST_CONNECTIONS. Учитывает количество подключений, поддерживаемых серверами в текущий момент времени. Каждый следующий запрос передается серверу с наименьшим количеством активных подключений.
ROUND_ROBIN. Представляет собой перебор по кругу: первый запрос передается первому серверу, затем следующий запрос передается второму — и так до достижения последнего сервера, а затем все начинается сначала.
SOURCE_IP. В этом методе сервер, обрабатывающий запрос, выбирается произвольным образом и закрепляется (на сессию, в cookies) за конкретным источником запроса.
Далее укажите ВМ для балансировки. Этот шаг необязательный, и его можно выполнить после создания балансировщика (см. рисунок ниже).
Рисунок 52 — Добавление ВМ балансироки
Настройте параметры интервалов проверки доступности (см. рисунок ниже).
Подсистема обычно является часть платформы, располагается на LCM-узле и находится по адресу https://netbox.<domain_name>.
Вся чувствительная информация должна храниться в этой системе.
Основной файл с секретами passwords_yml должен быть расположен в такой структуре: deployments/itkey/<prod\stage><region>/passwords_yml.
Структура может быть произвольной. Привязаться к существующей можно, изменив соответствующие CI/CD переменные в gitlab.domain_name для репозитория с файлами конфигурации, относящемуся к региону, например: https://<gitlab.domain_name>/project_k/deployments/stage1 → открыть → Settings → CI/CD → Variables:
vault_addr — адрес Vault (https://FQDN);
vault_engine — путь к хранилищу (secret store v2);
vault_method — jwt или password;
vault_password — заполните, если используется пароль для доступа к Vault;
vault_prefix — путь до passwords_yml региона (не включительно), например, deployments/itkey/prod/region1;
vault_role — itkey_deployments (не менять);
vault_username — укажите имя пользователя для доступа в Vault в случае использования парольной аутентификации;
В случае перезапуска контейнера Vault или перезапуска LCM сервера Vault необходимо разблокировать unseal-ключом, полученным при установке и сохраненном в надежном месте, сделать это можно так:
Castellan — это библиотека, предоставляющая собой общий интерфейс для хранения, генерации и извлечения секретов. Она используется большинством сервисов OpenStack для управления секретами. Как библиотека, Castellan сама по себе не предоставляет хранилище секретов. Вместо этого требуется развертывание реализации на стороне сервера.
С помощью интеграции данной библиотеки в oslo.config и корректной настройки Vault можно хранить пароли сервисов OpenStack в Vault вместо текстовых файлов.
Поддерживаются следующие сервисы:
AdminUI
Cinder
DRS
Glance
Keystone
Neutron
Nova
Placement
Для настройки хранения паролей сервисов в Vault необходимо в globals.d/castellan.yml определить services_with_castellan — список сервисов, для которых необходимо включить хранение паролей в Vault.
Пароли к некоторым сервисам можно хранить в хешированном виде.
Реализовано для HAProxy в части:
OpenSearch
Prometheus
Для настройки хеширования паролей сервисов необходимо в globals.d/REGION.yml определить services_with_hashed_password — список сервисов, для которых необходимо включить сокрытие паролей, например:
Необходимо запустить пайплайн для развертывания нужных компонентов.
При этом должна автоматически запуститься задача setup-castellan, которая предзаполнит значения паролей в Vault.
Для добавления настраиваемых Ansible ролей перейдите в репозиторий региона и создайте директорию client_config со следующей структурой:
group_vars/# Директория общих переменных для ролейroles/# Директория для хранения ролейsome-role/# Директория соответствующая названию ролиtasks/# Директория файлов с задачамиmain.yml# Основной файл задач ролиhandlers/# Директория обработчиков событий, которые выполняются при вызове из задач через ``notify``main.yml# Основной файл обработчиковtemplates/# Директория jinja2-шаблонов, которые можно использовать для динамического создания конфигурационных файловntp.conf.j2# Jinja2-шаблонfiles/# Директория статических файлов роли, которые могут быть скопированы на целевые хосты без измененийbar.txt# Статический файлvars/# Директория переменных роли с высоким приоритетом. Используются для ключевых параметров, которые редко изменяютсяmain.yml# Файл с переменнымиdefaults/# Директория переменных по умолчанию, которые могут быть переопределены. Имеют самый низкий приоритетmain.yml# Файл с переменнымиmeta/# Директория с метаданными роли, такие как зависимости и информация о поддержкеmain.yml# Файл зависимостейlibrary/# Директория для хранения пользовательских модулей Ansiblemodule_utils/# Директория для хранения вспомогательных утилит и библиотек, которые могут использоваться в пользовательских модуляхlookup_plugins/# Директория для хранения пользовательских плагинов для функций lookup, которые используются для получения данных из внешних источниковclient-config.yml# Конфигурационный файл для использования ролей (ansible плейбук)
В созданной директории создайте Ansible плейбук client-config.yml. Вариант содержимого client-config.yml:
----hosts:allroles:-some_role
Для применения создайте новый пайплайн: Build → Pipelines → Run Pipeline, затем запустите его. После завершения шага setup запустите задачу client-config.
Important
Перед запуском задачи client-config необходимо убедиться, что в директории <regionname>/client_config/roles присутствует директория some_role.
Подсистема мониторинга предназначена для решения задач мониторинга Платформы и ее сервисов.
За мониторинг Платформы отвечают компоненты, построенные на базе решений Opensearch, Prometheus и Grafana.
Описание работы с OpenSearch, панели (OpenSearch Dashboards) и запросы
OpenSearch — инструмент для поиска и анализа данных в документах с открытым исходным кодом. Разработанный на основе Elasticsearch, OpenSearch предоставляет эффективное хранилище и обработку данных, а также масштабируемую архитектуру.
OpenSearch Dashboards — инструмент для визуализации данных, с помощью которого пользователи могут создавать информативные и интерактивные панели на основе данных из OpenSearch.
Пользователи могут взаимодействовать с данными на дашбордах, применять фильтры и детализировать информацию для более глубокого анализа.
Инструмент предоставляет различные типы визуализаций, включая графики, диаграммы и карты, чтобы визуально представлять разнообразные данные.
OpenSearch Dashboards поддерживает совместную работу, что позволяет нескольким пользователям одновременно создавать и редактировать дашборды.
Помимо этого, дашборды можно импортировать и экспортировать для обмена настройками и визуализациями между различными инсталляциями OpenSearch Dashboards.
В составе настоящего релиза OpenSearch поставляется без преднастроенных панелей.
Предполагается, что администраторы кастомизируют панели под бизнес-задачи.
Создание пользовательских панелей с использованием различных виджетов и визуализаций
Процесс создания дашборда включает следующие этапы:
Выбор источника данных: происходит определение источника данных из OpenSearch для визуализации.
Добавление визуализаций: выбор и настройка виджетов и визуализаций для отображения данных.
Конфигурация фильтров: применение фильтров для уточнения отображаемых данных.
Определение компоновки: размещение визуализаций на дашборде с учетом их взаимодействия.
Сохранение и публикация: сохранение созданного дашборда и возможность его публикации для общего доступа.
Рисунок 54 — Создание пользовательской панели. Выбор визуализации
Рисунок 55 — Создание пользовательской панели. Применение фильтров
Рисунок 56 — Создание пользовательской панеи. Размещение визуализации
Подробнее о работе с OpenSearch Dashboards см. в документации OpenSearch Dashboards.
Данная настройка выполняется в самом OpenSearch. Для этого нужно перейти на сайт https://opensearch.<domain_name> → Index Management → Index Policies и добавить или изменить политику:
Это конфигурируемая опция. Чтобы изменить параметры глубины хранения, внесите изменения в globals.yml соответствующего региона в параметр prometheus_cmdline_extras, например:
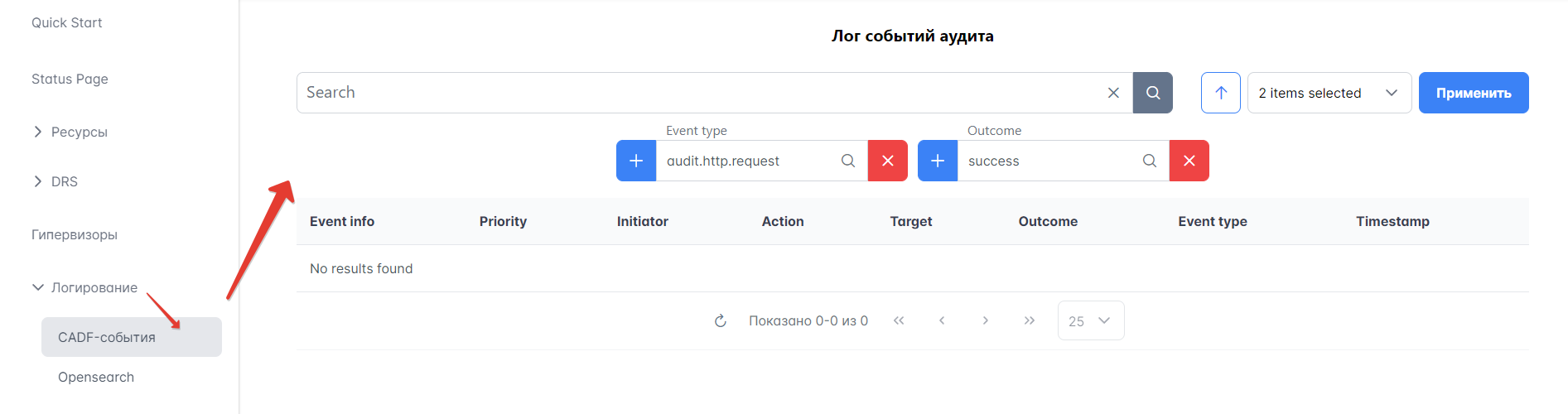
На Портале администратора можно отслеживать все события, которые произошли в системе OpenStack, на вкладке “Лог событий аудита”. Для этого нужно перейти в Логирование → CADF-события.
События можно фильтровать по различным параметрам, например, по типу (Event type), результату (Outcome) и др., а также комбинировать любые требуемые фильтры.
Рисунок 58 — Фильтры событий аудита
Настройка дополнительного приемника журналов KeyStack в формате syslog
После развертывания kolla-ansible конфигурационный файл (td-agent.conf) контейнера fluentd будет содержать следующие данные:
# Outputs# Included from conf/output/00-local.conf.j2:# Included from /etc/kolla/config/fluentd/output/fluent-plugin-remote_syslog.conf:<match**>@typeremote_sysloghost10.120.120.125port514protocoltcp</match>
Пример возможной конфигурации плагина fluent-plugin-remote_syslog с секциями
if value is true, raise exception by transfer timeout
keep_alive
bool (default: false)
use TCP keep alive
keep_alive_idle
integer
set TCP keep alive idle time
keep_alive_cnt
integer
set TCP keep alive probe count
keep_alive_intvl
integer
set TCP keep alive probe interval
Конфигурационные параметры для секции buffer
name
default
flush_mode
interval
flush_interval
5
flush_thread_interval
0.5
flush_thread_burst_interval
0.5
Конфигурационные параметры для секции format
name
default
@type
ltsv
License
Copyright (c) 2014-2017 Richard Lee. Copyright (c) 2022 Daijiro Fukuda.
See LICENSE for details.
Подсистема хранения кода и запуска пайплайнов (Gitlab)
Структура репозиториев в gitlab.domain_name https://<gitlab_url>
Все репозитории хранятся в группе project_k.
Kolla ansible — репозиторий, в котором хранятся плэйбуки и роли ansible от текущего релиза. Носит информативный характер и в жизненном цикле участия не принимают.
Kolla — репозиторий с исходным кодом для сборки образов docker для компонентов Openstack. Носит информативный характер и в жизненном цикле участия не принимает.
Keystack — репозиторий, который содержит базовые файлы конфигурации со значениями параметров для сервисов, рекомендуемыми вендором.
Dib — репозиторий для сборки образов операционных систем.
Ci — репозиторий с базовыми скриптами и пайпланами, которые используются для деплойментов окружений.
Deployments — группа, которая содержит набор репозиториев для создания и управления регионами/инсталляциями Openstack, а также общие репозитории для всех площадок — baremetal, bifrost и backup.
Baremetal — репозиторий для установки и базовой настройки операционных систем на физические сервера, которые планируется добавить в инсталляцию.
Bifrost — репозиторий, который содержит код для запуска контейнера bifrost, используемого логикой baremetal.
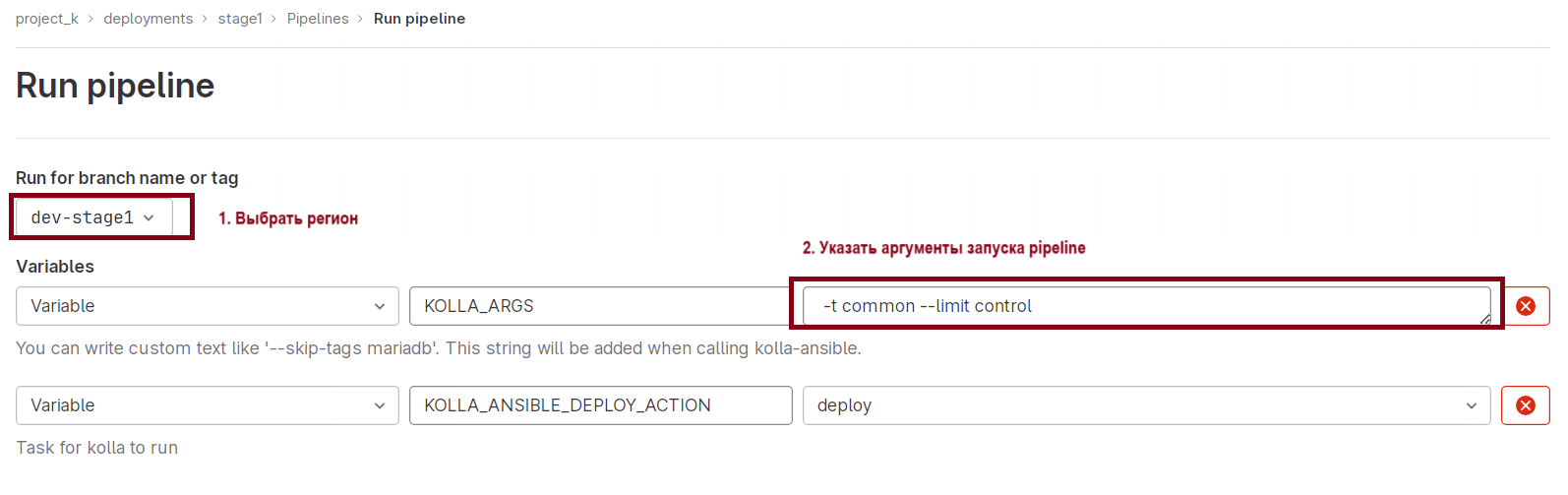
Для запуска деплоя какого-либо компонента запустите пайплайн из репозитория соответствующего окружения и укажите тег нужного компонента и лимит при необходимости.
Открыть страницу https://gitlab.domain_name/project_k/deployments/<REGION>/-/pipelines → Run Pipeline.
KOLLA_ANSIBLE_DEPLOY_ACTION — выберите “deploy”.
KOLLA_ARGS — укажите тег компонента, который собираемся деплоить. Например, для Cinder укажите -tcinder, а для ограничения набора серверов для обновления — --limit<server/rolename>.
Для деплоя данных сервисов нужно убедиться в наличии соответствующих переменных в REGION.yml соответствующего региона https://gitlab.domain_name/project_k/deployments/<REGION>/globals.d/REGION.yml.
Если все эти переменные существуют и имеют значение “yes”, то они будут установлены при деплое региона.
Если какие-то переменные отсутствовали, или же у них было выставлено значение “no”, то их можно установить отдельно.
Для этого добавьте переменную со значением “yes”, если переменной не было, либо выставите это значение, если было “no” — например, enable_opensearch: “yes”.
Далее откройте страницу https://gitlab.domain_name/project_k/deployments/<REGION>/-/pipelines → Run Pipeline.
KOLLA_ANSIBLE_DEPLOY_ACTION — выберите “deploy”.
KOLLA_ARGS — укажите тег компонента, который нужно деплоить. Для OpenSearch нужно указать -topensearch.
Neutron — сетевая служба, бесконтрольный деплой которой приведет к нарушению сетевой доступности облака, поэтому выкатка этого компонента выполняется с предварительной подготовкой и нюансами.
Деплой тега neutron на сервера с ролью control — обязательно указывать лимит на 1 узел, затем после выполнения пайплайна можно указать лимит на оставшиеся 2 узла и запустить пайплайн.
Деплой тега neutron на сервера с ролью network:
Получите список L3-агентов и их идентификаторы:
openstacknetworkagentlist--agent-typel3
Выключите L3-агент на том узле, на который планируется внести изменения:
openstacknetworkagentset--disable<l3_agent_uuid>
Подождите 5 минут.
Запустите пайлайн с тегом neutron и лимитом на тот сервер, на котором выключен L3-агент:
Рисунок 60 — Параметры запуска пайплайна
openstacknetworkagentset--enable<l3_agent_uuid>
Подождите 30 минут, отслеживая сообщения в логах /var/log/kolla/neutron/neutron-l3-agent.log (в логах дождаться окончания синков на сотни секунд).
Повторите итерацию для каждого L3-агента (для каждого узла с ролью network).
В KeyStack в качестве второго фактора используется пара сертификат/ключ для защиты аккаунта.
На первом этапе аутентификации пользователь указывает свой сертификат и ключ, на втором — имя пользователя и пароль от своей учетной записи.
Клиентский сертификат должен содержать следущий атрибуты:
1. Клиентский сертификат подписан центром сертификации, выпускающим сертификаты для региона Keystack.
2. Заданы назначения сертификата (OID):
Проверка подлинности сервера (1.3.6.1.5.5.7.3.1)
Проверка подлинности клиента (1.3.6.1.5.5.7.3.2)
Задан Subject, совпадающий с основным доменом региона Keystack.
2. Импортируйте получившийся сертификат в формате p12 в используемый браузер.
Пример для Chrome: <Настройки - Конфиденциальность и безопасность - Безопасность - Настроить сертификаты - Сертификаты - Личные>.
3. Перейдите по адресу Horizon или AdminUI и выберите сертификат для авторизации в всплывающем окне.
4. Используйте данные от своего аккаунта (имя пользователя и пароль) для авторизации в Horizon или AdminUI.
Настройка данной интеграции состоит из нескольких частей:
Создайте домен. Для этого при помощи OpenStack CLI выполните команду создания домена:
openstackdomaincreateldap, где ldap — это имя добавляемого домена (оно должно быть указано также в globals и участвовать в имени файла конфигурации для Keystone).
Добавьте параметры в globals и файлы конфигурации:
globals.yml соответствующего региона (в интерфейсе Horizon в выпадающем списке домены будут отображаться в той последовательности, в которой были указаны. В данном случае первым будет default, затем — ldap):
keystone.ldap.conf соответствующего региона https://<gtilab_url>/project_k/deployments/<regionname>/config/keystone/domains/keystone.ldap.conf (значения параметров, начинающихся с YOUR, нужно заполнить своими данными):
При интеграции по ldaps протоколу, добавьте цепочку из рутовых и промежуточных сертификатов в файл certificates/ca/ca-bundle.crt
Поместить пароль пользователя YOUR_SERVICE_USER_DN в Vault в файл паролей региона deployments/<regionname>/passwords_yml в поле ldap_password.
Выполните деплой тегов keystone и horizon. Подробнее о запуске деплоя см. в разделе Деплой компонентов.
Проверьте, что видно пользователей и группы LDAP в Keystack в Openstack CLI:
# openstack user list --domain ldap+------------------------------------------------------------------+----------------+|ID|Name|+------------------------------------------------------------------+----------------+|f82090b43940df5f7b8e77fb5e4ddaf04e60cecebc5e94dd63a5e0f53f219fe5|user1|+------------------------------------------------------------------+----------------+# openstack group list --domain ldap+------------------------------------------------------------------+--------+|ID|Name|+------------------------------------------------------------------+--------+|ec6d01371e3160ab417c404fa07828a2e4c2d2e3147b762f9cf6f3555a601280|group1|+------------------------------------------------------------------+--------+
Создайте проект в Openstack CLI или с помощью интерфейса Horizon:
openstackprojectcreatedemo--domainldap
Добавьте пользователей или группы в проект demo и дайте им права в них в Openstack CLI:
Реализовано резервное копирование данных LCM узла и баз данных для регионов Openstack. Резервные копии баз данных регионов шифруются алгоритмом AES-256 с использованием PBKDF2 для усиления безопасности ключа.
Резервное копирование LCM осуществляется через запуск запланированного задания в Gitlab из репозитория: https://<gtilab_url>/project_k/Deployments/backup.
Рисунок 61 — Резервное копирование LCM
Кроме того, выполнить резервное копирование LCM можно, запустив скрипт backupLCM.sh (находится в директории с инсталлятором).
В результате выполнения скрипта backupLCM.sh в директории /installer/backup создается архив с именем в формате backupLCM-31-08-2022-1661925161.tar.gz. Этот файл требуется скопировать в надежное хранилище данных.
Резервное копирования баз данных регионов Openstack осуществляется через запуск запланированного задания из соответствующего региону репозитория: https://<gitlab.domain_name> project_k/Deployments//-/pipeline_schedules.
Рисунок 62 — Резервное копирование баз данных регионов Openstack
Восстановление осуществляется путем запуска скрипта restoreLCM.sh.
Для запуска скрипта восстановления LCM необходимо положить резервную копию LCM с именем в формате backupLCM-31-08-2022-1661925161.tar.gz в ту же директорию рядом с ним, после чего запустить скрипт.
Восстановление базы данных регионов Openstack из резервной копии
За помощью в восстановлении баз данных регионов Openstack следует обратиться к вендору.
Подсистема хранения данных о физических серверах Netbox
Netbox — компонент в составе инсталлятора, размещенный на LCM-узле. Данный сервис включен в базовую последовательность установку продукта. Netbox предоставляет собой веб-интерфейс для хранения и внесения информации о серверах, сетевых интерфейсах и других данных, которые будут использоваться при автоматизированной установке и настройке операционной системы для серверов.
Пользовательский веб-интерфейс доступен по адресу https://netbox.<domain_name>.
Рисунок 63 — Интерфейс Netbox
Навигация по основным разделам веб-интерфейса осуществляется с помощью меню слева.
В Netbox всегда можно отследить внесенные изменения (время, автора изменений и т.д.) в разделе Change Log (Operations → Logging → Change Log).
Кроме того, можно осуществлять операции с целой группой сущностей, а не с каждой по отдельности. Для этого необходимо выделить выбранные сущности и нажать Edit Selected под таблицей с ними. Другие кнопки позволяют настроить параметры по-другому: например, переименовать или удалить.
Для базовой настройки сервиса достаточно заполнить следующие разделы: Organization, Customization, IPAM, Provisioning и Devices.
В первую очередь нужно настроить параметры в разделах Sites и Tenancy. Последовательность создания сущностей для работы с Netbox такая: сайт-группа → регион → сайт.
В разделе Custom Fields можно создавать дополнительные поля и задавать набор предопределенных параметров для каждого из них. Пример таких добавочных полей — два поля: role и state.
Дополнительные поля создаются и конфигурируются в Customization → Customization → Custom Fields.
Custom Fields, необходимые для работы Gitlab.domain_name Pipelines:
Теги — важный элемент в разделе Customization, поскольку сбор всей информации происходит по ним. По тегам ищутся сервера, которые нужно раздеплоить. По тегам можно также фильтровать разные сущности, например, девайсы.
Теги необходимо создать в Customization → Customization → Tags соответственно регионам/деплойментам у заказчика.
Раздел IPAM включает настройки для модулей IPAM и содержит все, что относится к сетям. Префикс для сети создается в разделе IPAM → Prefixes → Prefixes. Затем нужно выбрать сайт и VLAN для префикса.
В этом разделе нужно заполнять все по данным заказчика:
Чтобы определить производителей в Netbox, откройте Devices → Device Types → Manufacturers и заполните там данные, т.е. марку сервера. Если марка отсутствует, ее необходимо добавить.
Пайплайн по зачистке RabbitMQ и рестарту сервисов
Пайплайн по зачистке RabbitMQ (RMQ) и рестарту сервисов можно применять в случаях, перечисленных далее (по мониторингу или при соответствующих проверках через CLI).
При постоянном росте на протяжении 5 минут следующих метрик:
“Messages ready to be delivered to consumers”
“Messages pending consumer acknowledgement”
“Unroutable messages dropped”
“Unacknowledged messages”
При постоянном снижении на протяжении 5 минут следующих метрик:
“Total queues”
“Total channels”
“Total connections”
После применения пайплайна перечисленные выше метрики должны стабилизироваться.
Если вы столкнулись с описанными выше проблемами с RabbitMQ, свяжитесь со службой поддержки.
Далее нужно зайти по ssh на любой узел с Openstack клиентом и, используя файл admin-openrc.sh, обратиться к API OpenStack, чтобы получить статус компонентов сервиса neutron.
Если управляющие узлы выключались штатно, то нужно запомнить последовательность выключения серверов и включить их в обратной последовательности с задержкой в 5 минут.
Обычно 5 мминут достаточно, чтобы узлы galera добавились в кластер и синхронизировали свое состояние.
При этом крайне желательно после загрузки сервера (в данном примере — controller1) выполнить проверку статуса MariaDB.
Пример:
sshcontroller2mysql-uroot-pPassW0rd-s-s--execute="SHOW GLOBAL STATUS LIKE 'wsrep_local_state_comment';"wsrep_local_state_commentSyncedsshcontroller3mysql-uroot-pPassW0rd-s-s--execute="SHOW GLOBAL STATUS LIKE 'wsrep_local_state_comment';"wsrep_local_state_commentSynced
На сервере, пережившем failover, выполните следующие проверки:
Проверьте состояние контейнеров nova_compute на вычислительном узле. Выполните команду на вычислительном узле:
dockerps-a|grep-inova_compute
Убедитесь, что контейнер nova_compute находится в состоянии Up.
На вычислительном узле проверьте лог /var/log/kolla/nova/nova-compute.log на отсутствие событий ERROR или Traceback.
При их наличии убедитесь, что на вычислительном узле нет запущенных ВМ. Для этого на LCM-узле (или любом узле с установленным клиентом OpenStack CLI) выполните команду :
Если команда вернула информацию о каких-либо виртуальных машинах, тогда следует удалить их в контейнере nova_libvirt на вычислительном узле. Для этого для каждой ВМ:
Получите имя ВМ в среде libvirt, для этого выполните команду:
Решение виртуализации, при котором ядро операционной системы поддерживает несколько изолированных экземпляров пространства пользователя вместо одного. Эти экземпляры (обычно называемые контейнерами или зонами) с точки зрения пользователя полностью идентичны отдельному экземпляру операционной системы.