Руководство администратора KeyStack
Введение
Полное наименование системы — KeyStack.
Краткое наименование системы — Платформа.
Разработчик системы — ITKey.
Краткое описание возможностей
Платформа динамической инфраструктуры предназначена для предоставления сервисов IaaS.
Требования к квалификации персонала
Системные администраторы Платформы отвечают за комплексную настройку инфраструктуры Платформы, предоставляемой в качестве услуги конечным потребителям, за устранение неисправностей, сбор диагностической информации и эскалацию неисправностей производителю аппаратной или программной составляющей Платформы.
Системные администраторы выполняют следующие функциональные обязанности в рамках работы с Платформой:
настройка и диагностирование системы;
обслуживание системного и прикладного программного обеспечения системы;
администрирование базы данных;
резервное копирование и восстановление данных;
производство регламентных работ и анализ их результатов.
К системным администраторам предъявляются следующие требования:
Навыки системного администрирования Linux;
Прохождение обучения от компании ITKey по использованию компонентов, разработанных вендором: DRS, HA, Portal;
Навыки работы со службами Платформы, в том числе способность самостоятельно осуществлять:
мониторинг программными средствами, внешний осмотр аппаратной составляющей комплекса;
изменение настроек Платформы;
сбор диагностических данных и эскалацию сложных проблем по гарантийным обязательствам производителю.
Для обеспечения функционирования системы необходимо наличие как минимум одного системного администратора.
Перечень эксплуатационной документации
Документация Платформы включает в себя следующие документы:
Паспорт облака
План по резервному копированию и восстановлению компонентов Платформы
Инструкция администратора
Инструкция пользователя
Инструкция по резервному копированию и восстановлению всех компонентов
Назначение и условия применения
Виды деятельности, функции
В состав Платформы входят следующие подсистемы:
Подсистема вычислительных ресурсов — обеспечивает виртуализацию вычислительных ресурсов и управление ими;
Подсистема хранения данных — обеспечивает управление ресурсами хранения;
Подсистема передачи данных — обеспечивает реализацию и управление виртуальной сетевой инфраструктурой;
Подсистема мониторинга — обеспечивает сбор метрик с ресурсов Платформы, мониторинг Платформы и ее сервисов;
Подсистема Оркестрации — обеспечивает возможность автоматизированного управления ресурсами виртуальной инфраструктуры Платформы.
Программные и аппаратные требования к Платформе
Требования к инфраструктуре приведены в Инструкции по установке.
Подготовка к работе
Перечень программного обеспечения, включающий системное, базовое и прикладное ПО, приведен в Пояснительной записке.
Системный администратор использует в работе следующие интерфейсы Платформы, доступные по представленным далее ссылкам:
Портал самообслуживания;
интерфейс Horizon;
Opensearch;
Grafana;
Prometheus
API компонентов Платформы.
Основным рабочим веб-интерфейсом является Horizon.
Помимо веб-интерфейса, в работе используется Openstack CLI.
Подключение к порталу самообслуживания
Подключение к порталу самообслуживания производится с помощью веб-браузера. Для доступа к интерфейсам управления портала самообслуживания могут использоваться браузеры актуальных версий:
Google Chrome 72 и выше;
Mozilla Firefox 63 и выше.
При запросе логина и пароля необходимо ввести учетные данные. Внешний вид формы авторизации приведен на рисунке ниже.

Рисунок 1 — Окно авторизации в портале самообслуживания
Главная страница интерфейса управления имеет тематическое боковое меню (далее в тексте — левое меню), с помощью которого выполняется переход к различным разделам интерфейса управления Платформы.
Подключение к интерфейсу управления Openstack CLI
Перед началом работы в CLI необходимо получить исходный файл openrc и загрузить его на локальный компьютер администратора для установки переменных среды. Для получения файла openrc необходимо перейти в интерфейс портала администратора и скачать его на странице Status Page.
Important
Если используется библиотека Castellan, то при работе в Openstack CLI у администратора при каждом подключении будет запрашиваться пароль.
Openstack клиент можно установить на рабочее место администратора. Ниже приведен порядок установки Openstack клиента для различных ОС.
Установка Openstack клиента под Linux
Установка клиента Openstack:
sudo pip install python-openstackclient
Для проверки корректности настроек можно выполнить команду openstack server list, которая возвращает список ВМ.
Обновление клиента Openstack:
sudo pip install --upgrade python-openstackclient
Удаление клиента Openstack:
sudo pip uninstall python-openstackclient
Установка OpenStack CLI под Windows
Требуется установка последней версии Python с официального сайта http://python.org/downloads/windows. Дальнейшие инструкции выполняются в PowerShell.
Проверка работоспособности Python:
pip
Команда выводит справочную информацию о приложении. Если команда завершилась ошибкой, необходимо проверить правильность путей в переменной PATH.
Установка, обновление и удаление клиента Openstack выполняются аналогично разделу Установка Openstack клиента под Linux.
Запуск и выключение Платформы
Запуск Платформы
Почти все сервисы платформы — stateless, или имеют внутренние механизмы failover, прихода к консенсусу в кластере. Но есть сервис, на который надо обратить особое внимание — Galera Cluster. Поэтому в пункте Выключение всех компонентов Платформы важно было делать паузы перед выключением следующего узла и запомнить порядок выключения — это минимизирует до определенной степени шанс получить с “несобранным” кластером Galera Cluster с MariaDB после включения.
Порядок включения серверов Платформы в общем случае выглядит так:
Включите с паузами и по очереди управляющие узлы. Включайте в обратном порядке относительно выключения, т.е. если серверы были выключены в порядке controller1 → controller2 → controller3, то тогда, выдерживая достаточные паузы в 5-10 минут после загрузки Linux, производите включение в порядке controller3 → controller2 → controller1. При этом крайне желательно после загрузки сервера (в данном примере controller1) выполнить проверку статуса MariaDB.
Пример:
ssh controller1
mysql -uroot -pPassW0rd -s -s --execute="SHOW GLOBAL STATUS LIKE 'wsrep_local_state_comment';"
wsrep_local_state_comment Synced
Если в течение 5 минут статус не перейдет в Synced, все равно продолжайте с запуском остальных управляющих узлов. Когда узлы будут запущены, и позже будут запущены контейнеры consul-server, произойдет автоматический ребутстрап кластера MariaDB.
Включите вычислительные узлы.
Выполните проверку всех узлов с помощью инструкций, приведенных в разделе Порядок проверки сервисов при failover.
Оповестите владельцев workload’ов о возможности запуска их нагрузок в облаке — либо самостоятельно включите инстансы в зависимости от технического регламента.
Выключение всех компонентов Платформы
Для отключения платформы и её компонентов с сохранением данных необходимо выполнить следующие шаги:
Оповестить владельцев виртуальных машин о предстоящем отключении.
Выключить сервис DRS, деактивировав задание в панели администратора, затем последовательно подключившись к каждому контроллеру и введя команду
systemctl stop kolla-drs-container.service.Выключить сервис HA, последовательно подключившись к каждому контроллеру и введя команду
systemctl stop kolla-consul-container.service.Подключиться к серверу LCM для выполнения дальнейших действий.
Пример:
ssh lcm
source admin-openrc.sh
Зафиксировать состояние виртуальных машин на момент выключения региона, введя команду:
openstack server list --all-projects > VMs.$(date "+%Y-%m-%d-%H-%M-%S").txt
Выключить виртуальные машины средствами OpenStack, введя команду:
openstack server list --all-projects -c ID -f value | \
xargs -n1 openstack server stop
Проверить выключение всех виртуальных машин командой:
openstack server list --all-projects -c ID -c Status -f value | \
grep -v Active
Note
Если проверка покажет наличие виртуальных машин в статсуе ACTIVE, то необходимо повторить выключение каждой такой виртуальной машины индивидуально, введя команду openstack server stop <VM ID>, подставляя в качестве VM ID значенем из столбца ID предыдущего вывода.
Выключить узлы-гипервизоры средствами операционной системы:
for HOST in $(openstack hypervisor list -c "Hypervisor Hostname" -f value);\
do \
ssh -x ${HOST} "shutdown -h now";\
done
В строгом порядке очерёдности control3 → control2 → control1, с паузами достаточными для полного выключения сервера (время зависит от используемого аппаратного комплекса и должно быть уточнено в момент проведения ПСИ) средствами операционной системы выключить узлы слоя управления, проверяя процесс выключения и состояние серверов через IPMI:
ssh -x ctl3 ‘shutdown -h now’
# пауза до полного выключения
ssh -x ctl2 ‘shutdown -h now’
# пауза до полного выключения
ssh -x ctl1 ‘shutdown -h now’
# пауза до полного выключения
После выполнения этих шагов регион платформы будет полностью выключен.
Описание операций
В частной инсталляции Платформы не все опции команд Openstack CLI могут быть использованы, поэтому они приводятся для справки. Некоторые виды и типы интеграций могут быть недоступны и через API.
Управление квотами проекта
Квоты предоставляют возможность ограничивать использование ресурсов в проекте. Администратор может ограничивать ресурсы для каждого проекта по отдельности. В случае превышения квоты новый объект не сможет быть создан.
Управление квотами проекта осуществляется через CLI.
Пример запроса квот проекта по API (CLI)
С помощью команды openstack quota show --default можно увидеть список всех квот по умолчанию:
openstack quota show --default
+------------------------------+----------+
| Field | Value |
+------------------------------+----------+
| backup-gigabytes | 1000 |
| backups | 10 |
| cores | 100 |
| fixed-ips | -1 |
| floating-ips | 10 |
| gigabytes | 650 |
| gigabytes___DEFAULT__ | -1 |
| gigabytes_volumes-huawei | -1 |
| gigabytes_volumes-huawei-new | -1 |
| gigabytes_volumes-ssd | -1 |
| groups | 10 |
| health_monitors | None |
| injected-file-size | 10240 |
| injected-files | 5 |
| injected-path-size | 255 |
| instances | 50 |
| key-pairs | 10000 |
| l7_policies | None |
| listeners | None |
| load_balancers | None |
| name | None |
| networks | 100 |
| per-volume-gigabytes | -1 |
| pools | None |
| ports | 10000 |
| project | None |
| project_name | admin |
| properties | 128 |
| ram | 358400 |
| rbac_policies | 10000 |
| routers | 10 |
| secgroup-rules | 10000 |
| secgroups | 10000 |
| server-group-members | 100 |
| server-groups | 50 |
| snapshots | 10 |
| snapshots___DEFAULT__ | -1 |
| snapshots_volumes-huawei | -1 |
| snapshots_volumes-huawei-new | -1 |
| snapshots_volumes-ssd | -1 |
| subnet_pools | -1 |
| subnets | 100 |
| volumes | 50 |
| volumes___DEFAULT__ | -1 |
| volumes_volumes-huawei | -1 |
| volumes_volumes-huawei-new | -1 |
| volumes_volumes-ssd | -1 |
+------------------------------+----------+
Также можно увидеть все квоты для конкретного проекта. Для этого необходимо использовать ID проекта:
openstack quota show f538ffe832f34890ab5402995ff73102
+------------------------------+------------------+
| Field | Value |
+------------------------------+------------------+
| backup-gigabytes | 1000 |
| backups | 10 |
| cores | 100 |
| fixed-ips | -1 |
| floating-ips | 10 |
| gigabytes | 1000 |
| gigabytes___DEFAULT__ | -1 |
| gigabytes_volumes-huawei | -1 |
| gigabytes_volumes-huawei-new | -1 |
| gigabytes_volumes-ssd | -1 |
| groups | 10 |
| health_monitors | None |
| injected-file-size | 10240 |
| injected-files | 5 |
| injected-path-size | 255 |
| instances | 40 |
| key-pairs | 10000 |
| l7_policies | None |
| listeners | None |
| load_balancers | None |
| name | None |
| networks | 100 |
| per-volume-gigabytes | -1 |
| pools | None |
| ports | 500 |
| project_name | xcloud-devops |
| properties | 128 |
| ram | 200000 |
| rbac_policies | 10000 |
| routers | 100 |
| secgroup-rules | 1000 |
| secgroups | 1000 |
| server-group-members | 10 |
| server-groups | 10 |
| snapshots | 100 |
| snapshots___DEFAULT__ | -1 |
| snapshots_volumes-huawei | -1 |
| snapshots_volumes-huawei-new | -1 |
| snapshots_volumes-ssd | -1 |
| subnet_pools | -1 |
| subnets | 100 |
| volumes | 100 |
| volumes___DEFAULT__ | -1 |
| volumes_volumes-huawei | -1 |
| volumes_volumes-huawei-new | -1 |
| volumes_volumes-ssd | -1 |
+------------------------------+------------------+
Подсистема вычислительных ресурсов
Работа с шаблонами ВМ
Просмотр списка шаблонов ВМ
Просмотр списка шаблонов выполняется в Openstack CLI командой:
openstack flavor list
Пример вывода команды:
+-----+-----------+-------+------+-----------+-------+-----------+
| ID | Name | RAM | Disk | Ephemeral | VCPUs | Is_Public |
+-----+-----------+-------+------+-----------+-------+-----------+
| 1 | m1.tiny | 512 | 1 | 0 | 1 | True |
+-----+-----------+-------+------+-----------+-------+-----------+
Создание шаблона ВМ
Создание нового шаблона выполняется в Openstack CLI командой flavor create. Пример:
openstack flavor create --ram 512 --disk 1 --vcpus 1 <flavor-name>
где ram — размер оперативной памяти, disk — объем диска в GB, vcpus — количество vCPU, а <flavor-name> — наименование шаблона.
Полный перечень опций команды выглядит следующим образом:
openstack flavor create
[--id <id>]
[--ram <size-mb>]
[--disk <size-gb>]
[--ephemeral <size-gb>]
[--swap <size-mb>]
[--vcpus <vcpus>]
[--rxtx-factor <factor>]
[--public | --private]
[--property <key=value>]
[--project <project>]
[--description <description>]
[--project-domain <project-domain>]
<flavor-name>
где:
–id <id> — ID шаблона; ‘auto’ создает UUID (значение по умолчанию: auto);
–ram <MB> — размер памяти в MB (значение по умолчанию: 256MB);
–disk <GB> — размер диска в GB (значение по умолчанию: 0GB);
–ephemeral <GB> — размер эфемерного диска в GB (значение по умолчанию: 0GB);
–swap <MB> — дополнительный размер swap в MB (значение по умолчанию: 0MB);
–vcpus <vcpus> — количество vCPU (значение по умолчанию: 1);
–rxtx-factor <factor> — RX/TX фактор (значение по умолчанию: 1.0);
–public — шаблон доступен в других проектах (значение по умолчанию);
–private — шаблон недоступен в других проектах;
–property <key=value> — дополнительные свойства шаблона (опция может использоваться несколько раз для установки различных свойств);
–project <project> — разрешает доступ к шаблону из проекта <project> (по имени проекта или его ID), опция используется совместно с –private;
–description <description> — описание шаблона;
–project-domain <project-domain> — домен проекта (имя домена или его ID). Опция используется в случае конфликтов между названиями проектов;
<flavor-name> — наименование шаблона.
Удаление шаблона ВМ
Удаление шаблона ВМ выполняется в Openstack CLI командой:
openstack flavor delete <flavor> [<flavor> ...]
где <flavor> — наименование или ID шаблона. Одновременно может быть удалено несколько шаблонов.
Работа с образами ВМ
Просмотр списка образов
Просмотр образов осуществляется на Портале самообслуживания или с использованием Openstack CLI.
Для просмотра списка образов на Портале необходимо в левом меню перейти в раздел Вычислительные ресурсы → Образы. Пример вида раздела представлен на рисунке ниже.

Рисунок 2 — Пример списка образов
Для просмотра списка образов в Openstack CLI выполните команду: openstack image list
Пример вывода команды:
+--------------------------------------+-----------------------------------+--------+
| ID | Name | Status |
+--------------------------------------+-----------------------------------+--------+
| 42f43e9d-7c53-46fa-ad87-846ef524d721 | CentOS-7-x86_64-GenericCloud-1905 | active |
Создание образа
Создание образа осуществляется в Портале самообслуживания или с использованием Openstack CLI. Образ можно создать путем загрузки файла в формате .raw или .qcow2 либо путем создания из существующего диска.
Создание образа из файла
Для создания образа в Портале самообслуживания из файла необходимо в левом меню перейти в раздел Вычислительные ресурсы → Образы и нажать кнопку “Create Image”.
В качестве источника необходимо указать “Файл” (см. рисунок ниже), выбрать файл, указать название образа и нажать кнопку “Create Image” и заполнить необходимые поля.

Рисунок 3 — Создание образа из файла
Для загрузки образа размером более 20GB рекомендуется использовать клиента командной строки.
Для загрузки образа в Openstack CLI выполните команду: openstack image create --private --container-format bare --disk-format qcow2 --file <имя_файла.raw> <имя_образа>
Если необходимо загрузить образ с поддержкой резервного копирования или смены пароля, добавьте свойства для работы с qemu-guest-agent: openstack image create --private --container-format bare --disk-format qcow2 --file <имя_файла.raw> --property hw_qemu_guest_agent=yes --property os_require_quiesce=yes <имя_образа>
Создание образа из существующего диска
Для создания образа из существующего образа в Портале самообслуживания необходимо в левом меню перейти в раздел Диски, найти диск, из которого будет создаваться образ, и затем в выпадающем списке выбрать пункт меню “Загрузить образ”.
В форме создания образа нужно выбрать формат диска (см. рисунок ниже), указать название образа и нажать кнопку “Загрузить”.

Рисунок 4 — Создание образа из существующего диска
Выгрузка образа
Выгрузка образа в файл выполняется в Openstack CLI следующей командой: openstack image save --file <file-name> <image-id>
где <file-name> — имя локального файла, а <image-id> — ID образа.
Удаление образа
Для удаления образа в Портале самообслуживания необходимо в левом меню перейти в раздел Вычислительные ресурсы → Образы, в списке образов выбрать образ для удаления и в контекстном меню выбрать действие “Удалить образ” (см. рисунок ниже).

Рисунок 5 — Удаление образа
Работа с ВМ
Просмотр списка ВМ
Просмотр списка ВМ проекта осуществляется в интерфейсе Портала самообслуживания или в Openstack CLI.
Для просмотра списка ВМ проекта необходимо в левом меню Портала выбрать Вычислительные ресурсы → Инстансы (см. рисунок ниже).

Рисунок 6 — Список ВМ проекта
Просмотр списка ВМ в CLI выполняется командой server list. Полный перечень опций выглядит следующим образом:
openstack server list
[--sort-column SORT_COLUMN]
[--reservation-id <reservation-id>]
[--ip <ip-address-regex>]
[--name <name-regex>]
[--instance-name <server-name>]
[--status <status>]
[--flavor <flavor>]
[--image <image>]
[--host <hostname>]
[--all-projects]
[--project <project>]
[--project-domain <project-domain>]
[--user <user>]
[--user-domain <user-domain>]
[--long]
[-n | --name-lookup-one-by-one]
[--marker <server>]
[--limit <num-servers>]
[--deleted]
[--changes-before <changes-before>]
[--changes-since <changes-since>]
[--locked | --unlocked]
[--tags <tag>]
[--not-tags <tag>]
где:
–sort-column SORT_COLUMN — столбцы для сортировки данных (несуществующие столбцы игнорируются);
–reservation-id <reservation-id> — возвращать экземпляры ВМ, соответствующие резервированию;
–ip <ip-address-regex> — регулярное выражение для отбора ВМ по соответствующим адресам;
–name <name-regex> — регулярное выражение для отбора ВМ по имени;
–instance-name <server-name> — регулярное выражение для отбора ВМ по имени инстанса;
–status <status> — отбирать ВМ по указанному статусу;
–flavor <flavor> — отбирать ВМ по указанному шаблону ВМ (по наименованию или ID);
–image <image> — отбирать ВМ по указанному образу (по наименованию или ID);
–host <hostname> — отбирать ВМ по гипервизору размещения;
–all-projects — включать в выборку все проекты;
–project <project> — отбирать ВМ в указанном проекте (по наименованию или ID);
–project-domain <project-domain> — отбирать ВМ по домену проекта (по наименованию или ID). Опция используется в случае конфликтов между названиями проектов;
–user <user> — отбирать ВМ указанного пользователя (по имени или ID);
–user-domain <user-domain> — отбирать ВМ по домену пользователя (по имени или ID). Опция используется в случае конфликтов между именами пользователей;
–long — выводить дополнительные поля;
-n, –no-name-lookup — пропустить разрешение имен шаблонов ВМ и образов. Не используется совместно с опцией –name-lookup-one-by-one;
–name-lookup-one-by-one — при разрешении имен шаблонов ВМ и образов искать из по мере необходимости. Не используется совместно с опцией –no-name-lookup|-n;
–marker <server> — последняя ВМ предыдущей страницы. Выводит весь список ВМ после <server>, если не указано иное. Если используется с опцией –deleted, маркер <server> должен быть идентификатором (ID), иначе допускается использование наименование ВМ или ID;
–limit <num-servers> — максимальное количество ВМ в выводимом списке. Если указывается значение -1, тогда выводятся все ВМ. Если указанное значение <num-servers> превышает значение конфигурационного параметра osapi_max_limit, то выводится osapi_max_limit ВМ;
–deleted — выводить только удаленные ВМ;
–changes-before <changes-before> — выводить список ВМ, измененных до указанного момента времени. Указываемое время должно быть в формате ISO 8061 (например, 2016-03-05T06: 27: 59Z);
–changes-since <changes-since> — выводить список ВМ, измененных после указанного момента времени. Указываемое время должно быть в формате ISO 8061 (например, 2016-03-05T06: 27: 59Z);
–locked — выводить в список только заблокированные ВМ;
–unlocked — выводить в спискок только незаблокированные ВМ;
–tags <tag> — выводить ВМ с указанными тегами. Может использоваться несколько раз для отбора ВМ по нескольким тегам;
–not-tags <tag> — выводить только те ВМ, у которых нет указанного тега. Может использоваться несколько раз для указания нескольких тегов.
Запуск, перезапуск и остановка ВМ
Запуск, перезапуск и остановка ВМ осуществляется в интерфейсе Портала самообслуживания или в OpenStack CLI.
Для управления состоянием ВМ в Портале самообслуживания используйте кнопки “Выключить инстанс”, “Горячая перезагрузка инстанса” и “Холодная перезагрузка инстанса” (см. рисунок ниже).

Рисунок 7 — Кнопки управления состоянием ВМ
Текущий статус виртуальной машины отображается в столбце “Status” (см. рисунок выше).
В Openstack CLI операции запуска, перезапуска и остановки ВМ выполняются командами server start, server reboot и server stop соответственно. Синтаксис команд:
openstack server start <server> [<server> ...]
openstack server reboot [--hard | --soft] [--wait] <server>
openstack server stop <server> [<server> ...]
где:
<server> [ …] — ВМ или список ВМ (имя ВМ или ID);
–hard — “жесткая” перезагрузка;
–soft — “мягкая” перезагрузка;
–wait — дождаться завершения перезагрузки.
Создание ВМ
Создание ВМ осуществляется в интерфейсе Портала самообслуживания или в OpenStack CLI.
Для создания ВМ необходимо в левом меню Портала выбрать Вычислительные ресурсы → Инстансы и нажать кнопку “Запустить инстанс”.
В форме “Создание нового инстанса” необходимо указать параметры создаваемой ВМ (см. рисунок ниже):
Instance — укажите имя ВМ;
Volume size — размер диска в GB;
Image — выберите образ из списка доступных;
Flavor — шаблон виртуальной машины, выберите из списка доступных
Key pairs — создайте новую ключевую пару или используйте существующую в проекте;
Network — укажите сеть, в которой будет доступна ВМ из списка сетей;
Security groups — укажите одну или несколько групп безопасности из списка доступных.

Рисунок 8 — Создание новой ВМ
Создание ВМ в Openstack CLI выполняется следующей командой:
openstack server create
(--image <image> | --image-property <key=value> | --volume <volume>)
[--password <password>]
--flavor <flavor>
[--security-group <security-group>]
[--key-name <key-name>]
[--property <key=value>]
[--file <dest-filename=source-filename>]
[--user-data <user-data>]
[--description <description>]
[--availability-zone <zone-name>]
[--host <host>]
[--hypervisor-hostname <hypervisor-hostname>]
[--boot-from-volume <volume-size>]
[--block-device-mapping <dev-name=mapping>]
[--nic <net-id=net-uuid,v4-fixed-ip=ip-addr,v6-fixed-ip=ip-addr,port-id=port-uuid,auto,none>]
[--network <network>]
[--port <port>]
[--hint <key=value>]
[--use-config-drive | --no-config-drive | --config-drive <config-drive-volume>|True]
[--min <count>]
[--max <count>]
[--wait]
[--tag <tag>]
<server-name>
где:
–image <image> — создать ВМ с использованием существующего образа (наименование или ID);
–image-property <key=value> — изменяемые свойства используемого образа;
–volume <volume> — создать ВМ с использованием указанного диска (наименование или ID). Данная опция автоматически создает отображение блочного устройства с индексом загрузки 0. Не следует использовать дублирующее сопоставление с использованием опции –block-device-mapping;
–password <password> — установить пароль для создаваемой ВМ;
–flavor <flavor> — использовать указанный шаблон (наименование или ID);
–security-group <security-group> — группа безопасности, назначаемая ВМ. Может использоваться несколько раз для назначения нескольких групп безопасности;
–key-name <key-name> — используемая ключевая пара (необязательный параметр);
–property <key=value> — установить дополнительные свойства ВМ (может указываться несколько раз для установки нескольких свойств);
–file <dest-filename=source-filename> — добавить в образ ВМ указанный файл (может указываться несколько раз для добавления разных файлов);
–user-data <user-data> — файл данных пользователя для обслуживания с сервера метаданных;
–description <description> — описание создаваемой ВМ;
–availability-zone <zone-name> — установить зону доступности ВМ;
–host <host> — создать ВМ с использованием службы Nova на конкретном гипервизоре;
–hypervisor-hostname <hypervisor-hostname> — создавать ВМ на указанном гипервизоре;
–boot-from-volume <volume-size> — при использовании в сочетании с параметром –image или –image-property этот параметр создает сопоставление блочного устройства с индексом загрузки 0 и сообщает службе compute создать том заданного размера (в GB) из указанного образа и использовать его в качестве корневого тома. Корневой том не будет удален при удалении ВМ. Этот параметр является взаимоисключающим с параметром –volume;
–block-device-mapping <dev-name=mapping> — создать блочное устройство. Блочное устройство указывается в формате <dev-name>=<id>:<type>:<size(GB)>:<delete-on-terminate>, где:
<dev-name> — наименование блочного устройства, например, vdb, xvdc (обазательный параметр);
<id> — наименование или ID тома, снапшота или образа (обязательный параметр);
<type> — volume (том), snapshot (снапшот) или image (образ). Значение по умолчанию — volume;
<size(GB)> — размер тома, если он создается из снапшота или образа (необязательный параметр);
<delete-on-terminate> — true или false, удалять при удалении ВМ. Значение по умолчанию — false (необязательный параметр);
–nic <net-id=net-uuid,v4-fixed-ip=ip-addr,port-id=port-uuid,auto,none> — создать сетевой адаптер. Опция используется несколько раз для создания нескольких адаптеров. Необходимо указывать ID сети или ID порта, но не оба сразу;
net-id — подключить сетевой адаптер к сети с UUID net-uuid;
port-id — подключить сетевой адаптер к порту с UUID port-uuid;
v4-fixed-ip — фиксированный IPv4-адрес сетевого адаптера (необязательный параметр);
none — сеть не подключена;
auto — автоматическое выделение сети.
–network <network> — создать сетевой адаптер и подключить к сети. Можно указывать несколько раз для создания нескольких сетевых адаптеров. Данная опция является оболочкой для опции –nic net-id=<network>, которая обеспечивает простой синтаксис для стандартного варианта подключения новой ВМ к сети. Для более сложных случаев рекомендуется использовать полный синтаксис –nic;
–port <port> — создать сетевой адаптер и подключить его к порту. Можно указывать несколько раз для создания нескольких сетевых адаптеров. Данная опция является оболочкой для опции –nic port-id=<port>, которая обеспечивает простой синтаксис для стандартного подключения новой ВМ к заданному порту. Для более сложных случаев рекомендуется использовать полный синтаксис –nic;
–hint <key=value> — подсказки для планировщика (необязательный параметр);
–use-config-drive — разрешает использование конфигурационного диска;
–no-config-drive — запрещает использование конфигурационного диска;
–config-drive <config-drive-volume>|True — устаревшая опция указания использования указанного тома в качестве диска конфигурации. Заменено на –use-config-drive;
–min <count> — минимальное количество ВМ для запуска. Значение по умолчанию — 1;
–max <count> — максимальное количество ВМ для запуска. Значение по умолчанию — 1;
–wait — дождаться окончания сборки;
–tag <tag> — теги ВМ. Можно указывать несколько раз для добавления нескольких тегов;
<server-name> — наименование ВМ.
Создание ВМ с поддержкой secure boot
Предварительные требования:
образ, из которого будет создаваться виртуальная машина, должен быть собран с поддержкой UEFI;
- в метаданные образа добавлены свойства os_secure_boot=required и hw_firmware_type=uefi.Добавить свойства можно через Horizon или CLI:
openstack image set --property hw_firmware_type=uefi --property os_secure_boot=required $IMAGE.
Администратор может запретить безопасную загрузку даже при наличии необходимых свойств в метаданных образа: openstack flavor set --property os:secure_boot=disabled $FLAVOR
Также есть возможность запрашивать безопасную загрузку, если хост ее поддерживает. Это делается через настройку метаданных образа: openstack image set --property os_secure_boot=optional $IMAGE
Узнать, поддерживает ли хост безопасную загрузку, можно таким образом:
COMPUTE_UUID=$(openstack resource provider list --name $HOST -f value -c uuid)
openstack resource provider trait list $COMPUTE_UUID | grep COMPUTE_SECURITY_UEFI_SECURE_BOOT
CPU Pinning
- Настройка гипервизора.Настройка предполагает добавление опций в загрузку ядра — isolcpus=2,3,4,5,6,7… - перечислите все ядра, которые нужно изолировать — добавление данной настройки предполагает перезагрузку сервера.
- Настройка сервиса nova-compute.Далее необходимо доработать конфигурацию сервиса nova-compute — добавьте в nova.conf гипервизора, на котором выполнена настройка isolcpus.
[compute]
cpu_dedicated_set=2-10 #указать желаемый набор ядер, который коррелирует с isolcpus
- Настройка host aggregate и flavor.Создайте агрегат, в который нужно добавить гипервизоры, где будет использоваться механизим CPU pinning. В метаданные агрегата добавьте параметр: pinned = true
Создайте флейвор нужного размера и добавьте в него метаданные:
aggregate_instance_extra_specs:pinned = true
hw:cpu_policy = dedicated
Использование механизма Memory ballooning
Memory ballooning — это технология управления оперативной памятью в виртуализированных средах, включая OpenStack. Она позволяет гипервизору динамически изменять объем оперативной памяти, доступной виртуальной машине, в зависимости от текущих потребностей.
Как работает memory ballooning:
В каждой ВМ устанавливается специальный драйвер (balloon driver), который взаимодействует с гипервизором. Гипервизор использует этот драйвер, чтобы запрашивать у ВМ “освободить” или “предоставить” память.
Когда гипервизору требуется освободить память, он посылает запрос balloon-драйверу в ВМ. Balloon-драйвер “заполняет” память ВМ с помощью выделения фиктивных блоков памяти, которые более не используются ВМ. Эти блоки памяти возвращаются гипервизору и могут быть перераспределены другим ВМ.
Когда ВМ требуется больше памяти, гипервизор может “сдуть” balloon, освобождая память, ранее выделенную другим ВМ.
Этот механизм включен в продукте по умолчанию, но для его работы необходимо выполнить требования к подготовке образов гостевых операционных систем.
Требование к образам Windows:
наличие Balloon драйвера, включен в VirtIO Windows Driver Pack,
установленая служба BalloonService (тип запуска службы - Auto).
Требования к образам Linux:
наличие VirtIO драйверов. Модуль virtio_balloon обычно включён в большинство современных дистрибутивов.
Изменение ресурсов ВМ
Изменение ресурсов виртуальной машины используется для увеличения или уменьшения количества виртуальных CPU или RAM виртуальной машины. Изменение ресурсов ВМ осуществляется в интерфейсе Портала самообслуживания или в OpenStack CLI.
Для изменения ресурсов ВМ необходимо в левом меню Портала выбрать Вычислительные ресурсы → Инстансы, далее выбрать ВМ, ресурсы которой необходимо изменить, и выбрать в контекстном меню “Изменить размер инстанса” (см. рисунок ниже).

Рисунок 9 — Меню изменения размера ВМ
В окне изменения размера нужно указать новый шаблон ВМ.
Изменение размера ВМ реализуется путем создания новой ВМ и копирования исходного диска ВМ в новый. Это двухэтапный процесс: первый шаг — изменение размера, второй шаг — либо подтверждение и успеха операции и освобождение старой ВМ, либо объявление возврата операции (освобождение новой ВМ и запуск старой ВМ).
В OpenStack CLI изменение размера ВМ выполняется командой server resize:
openstack server resize
[--flavor <flavor> | --confirm | --revert]
[--wait]
<server>
где:
–flavor <flavor> — новый шаблон ВМ;
–confirm — подтверждение завершения операции изменения размера ВМ;
–revert — восстановление состояния ВМ до изменения;
–wait — дождаться окончания операции;
<server> — изменяемая ВМ (имя или ID).
Удаление ВМ
Удаление ВМ осуществляется в интерфейсе Портала самообслуживания или в OpenStack CLI.
Для удаления ВМ необходимо в левом меню Портала выбрать Вычислительные ресурсы → Инстансы, далее выбрать ВМ, которую необходимо удалить, и выбрать в контекстном меню пункт “Удалить инстанс” (см. рисунок ниже).

Рисунок 10 — Удаление ВМ
Если необходимо удалить несколько виртуальных машин, то нужно выбрать их в списке и выбрать в контекстном меню пункт “Удалить” (см. рисунок ниже).

Рисунок 11 — Удаление группы ВМ
Удаление ВМ в CLI выполняется командой server delete. Синтаксис команды: openstack server delete [--wait] <server> [<server> ...]
где:
–wait — дождаться завершения удаления;
<server> [<server> …] — ВМ (список ВМ) для удаления (имя ВМ или ID).
Миграция ВМ
Миграция ВМ в CLI выполняется командой server migrate. Синтаксис команды:
openstack server migrate --os-compute-api-version 2.87
[--live-migration]
[--host <hostname>]
[--shared-migration | --block-migration]
[--disk-overcommit | --no-disk-overcommit]
[--wait]
<server>
где:
–live-migration — выполнить live-миграцию ВМ. Нужно использовать опцию –host для указания целевого вычислительного узла;
–host <hostname> — выполнить миграцию на вычислительный узел <hostname>;
–shared-migration — выполнить общую live-миграцию (миграция по умолчанию);
–block-migration — выполнить блочную live-миграцию;
–disk-overcommit — разрешить избыточную фиксацию диска на целевом управляющем узле;
–no-disk-overcommit — не выполнять избыточную фиксацию диска на целевом управляющем узле;
–wait — дождаться завершения миграции;
<server> — мигрируемая ВМ (имя или ID).
Миграция ВМ с перегрузкой по памяти
При работе с ВМ с перегруженной памятью компонент Nova по умолчанию использует следующую формулу: Тайм-аут = базовый_тайм-аут (800 сек) * объем оперативной памяти (ГБ). Таким образом, живая миграция нагруженных ВМ с большим объемом ОЗУ может занимать много времени. Существует механизм принудительного завершения миграции по истечении тайм-аута, который может использовать два сценария реализации:
Посткопирование (post-copy) — производится перенос ВМ на целевой вычислительный узел и постепенное донесение содержимого оперативной памяти. Работа ВМ до полного переноса памяти проходит в режиме пониженной производительности.
Автоматическая сходимость (auto converge) — если миграция не может завершиться, то компонент начинает замедлять работу процессора ВМ до тех пор, пока процесс копирования памяти не станет быстрее, чем изменение памяти ВМ.
Таким образом, можно оптимизировать процесс живой миграции, подобрав оптимальное время тайм-аута и выбрав предпочтительный сценарий реализации принудительного завершения миграции.
Эвакуация ВМ с вычислительного узла
В контейнере kolla_toolbox на управляющем узле необходимо выполнить команду для эвакуации ВМ на другие вычислительные узлы в составе кластера:
nova host-evacuate-live <хостнейм_удалаяемого_узла>
Клонирование существующих виртуальных машин с кастомизацией
Необходимо выполнить следующие действия:
Подключитесь к Порталу самообслуживания.
На странице Project → Volumes → Volumes выберите диск, у которого в колонке “Attached To” указана ВМ, которую нужно скопировать (см. рисунок ниже).
Нажмите выпадающий список в столбце “Actions” и выберите пункт “Create Snapshot”.
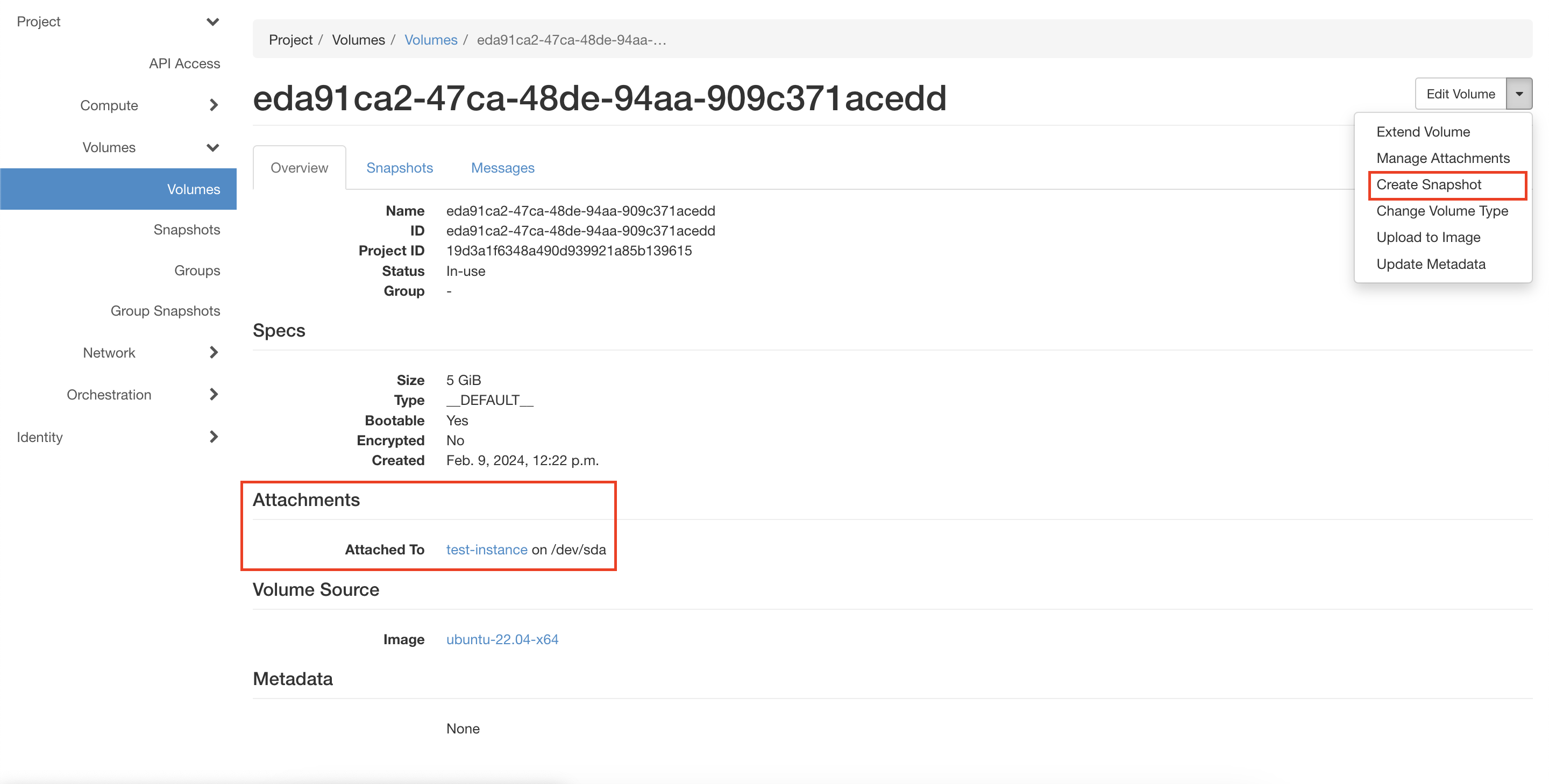
Рисунок 12 — Проверка параметров выбранного диска
В открывшемся окне введите имя снимка в поле “Snapshot Name” и нажмите кнопку “Create Volume Snapshot (Force)” (см. рисунок ниже).
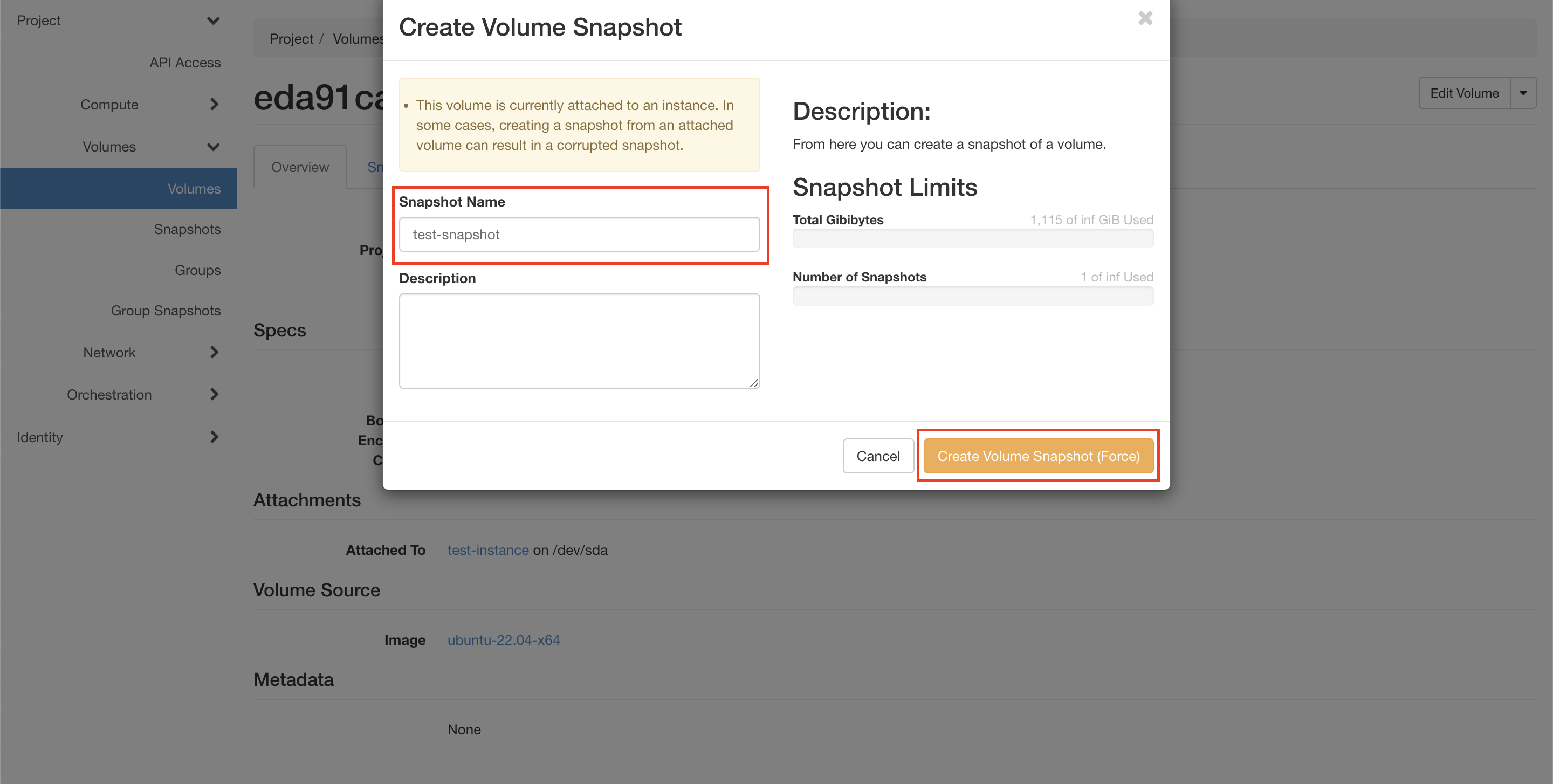
Рисунок 13 — Создание снимка
На странице Project → Volumes → Snapshots нажмите выпадающий список в столбце “Actions” в строке тестового снимка.
Выберите пункт “Launch as Instance” (см. рисунок ниже).
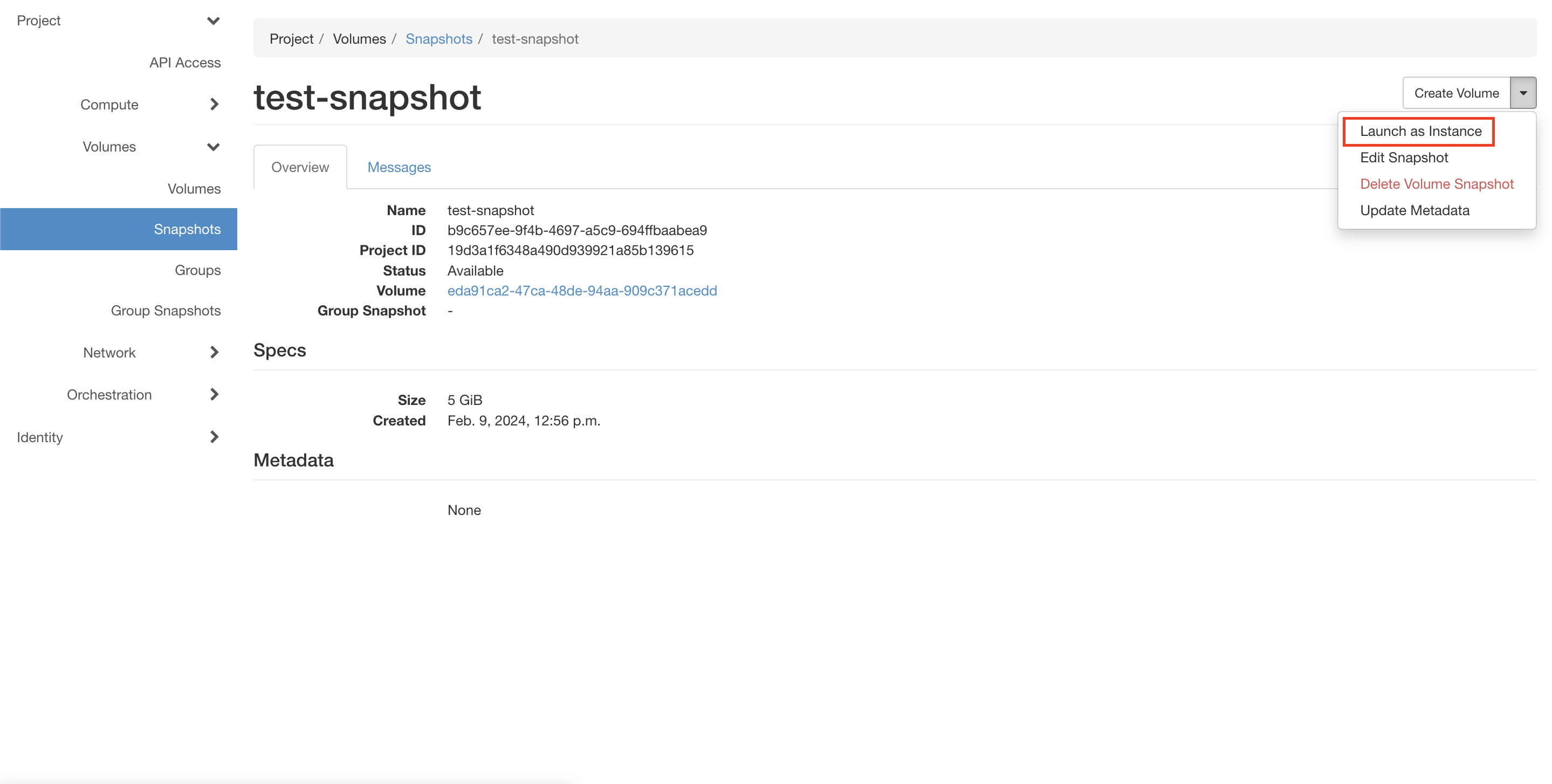
Рисунок 14 — Запуск клонированной ВМ
В открывшемся окне заполните следующее:
Вкладка Details:
Instance name: VM_with_CustomizationВкладка Flavor:
Allocated: m1.tinyВкладка Network:
Allocated: privateВкладка Configuration:
Load Customization Script from a file: Загрузить конфигурационный скрипт в виде файлаилиCustomization Script: Ввести конфигурационный скрипт в поле ввода текста
В качестве примера конфигурационного скрипта можно привести следующий скрипт:
#cloud-config
ssh_pwauth: yes
chpasswd:
list: |
ubuntu:123456
root:1234567
expire: False
Нажмите кнопку “Launch as Instance”.
Подключение к VM по SSH должно быть доступно для следующих username/password:
ubuntu/123456root/1234567
Добавление новых вычислительных узлов
Подготовьте описание серверов для Netbox. Подробнее о Netbox см. в разделе Подсистема хранения данных о физических серверах Netbox.
Для этого нужно добавить в Netbox (пароль можно посмотреть в Vault в разделе Accounts)
https://netbox.<domain_name>/dcim/devices/новое устройство (см. рисунок ниже).
Рисунок 15 — Добавление нового устройства в Netbox
Затем необходимо заполнить поля:
Name — имя сервера;
Device role — Server;
Device type — выбрать соответствующий тип;
Site — выбрать соответствующий сайт, например, ks-region1;
Status — Active;
Tenant — выбрать тенант;
Role — выбрать роль в выпадающем списке (controller, compute или network);
Status — Ready.
После того как устройство будет добавлено, зайдите в него и добавьте сетевые интерфейсы аналогично тому, как изображено на рисунке ниже.

Рисунок 16 — Добавление сетевых интерфейсов
Теперь можно устанавливать операционную систему. Для этого требуется запустить пайплайн
https://<gitlab_url>/project_k/Deployments/baremetal/-/pipelinesи поменять значения для следующих параметров:TARGET_ROLE — compute, controller или network;
TARGET_CLOUD — ks-region1;
IRONIC_IMAGE_URL — во всех сценариях, кроме TARGET_ROLE=network, оставить как есть, в противном случае — указать
http://LCM_IP:8080/ubuntu-20.04-mellanox-keystack.qcow2.
Нужно добавить новый сервер в inventory соответствующего окружения в gitlab.domain_name в группу compute
https://<gitlab_url>/project_k/deployments/stage1/-/blob/dev-stage1/inventory(пример для stage1).Теперь можно запускать kolla-ansible bootstap:
https://<gitlab_url>/project_k/Deployments/<ENV>/-/pipelines
https://<gitlab_url>/project_k/deployments/stage1/-/pipelinesПроверьте, что гипервизор функционирует, как ожидается — создаются виртуальные машины, работает миграция, работает сетевая связность — доступ по SSH до тестовых виртуальных машин:
Создайте виртуальную машину на требуемом гипервизоре через CLI:
openstack server create --image <image_id> --flavor <flavor_id> --availability-zone nova:<hypervisor_host_name> --nic net-id=<network_id> Test-VMПроверьте, что она создалась и перешла в статус ACTIVE, через
openstack server show <server_id>.Добавьте к ней FIP и проверить SSH-доступ (должно быть соответствующее разрешающее правило).
Убедитесь, что виртуальную машину можно мигрировать (миграция ВМ возможна такая: Mirantis → Keystack или Keystack → Keystack). Сделать это можно через CLI:
openstack server migrate --os-compute-api-version 2.87 --live-migration <instance_id> --host <new_host_name>
Удаление вычислительного узла из кластера
Удалите описание сервера из Netbox: https://netbox.<domain_name>/dcim/devices/
Удалите сервер из inventory из группы [compute]: https://<gitlab_url>/project_k/deployments/stage1/-/blob/dev-stage1/inventory (пример для stage1).
Далее следует удалить связанные сущности в Openstack (предполагается, что виртуальных машин на сервере нет):
HOST_FOR_REMOVAL=<computeN>
openstack --os-compute-api-version 2.87 compute service list --host $HOST_FOR_REMOVAL --service nova-compute -f value -c ID | xargs openstack --os-compute-api-version 2.87 compute service delete
openstack network agent list --host $HOST_FOR_REMOVAL -f value -c ID | while read agent_id; do openstack network agent delete $agent_id; done
openstack resource provider list --name $HOST_FOR_REMOVAL -f value -c uuid | xargs openstack resource provider show --allocations -f json |jq .allocations | jq 'keys[]' | xargs -n1 openstack resource provider allocation delete
openstack resource provider list --name $HOST_FOR_REMOVAL -f value -c uuid | xargs openstack resource provider delete
Перевод вычислительного узла в режим обслуживания
Для обслуживания вычислительного узла предусмотрен механизм временного отключения узла из кластера.
Вывод вычислительного узла на обслуживание осуществляется через интерфейс управления Horizon some_url.
Для перевода узла в режим обслуживания необходимо выполнить следующие действия:
В интерфейсе администратора Horizon перейдите в раздел “Вычислительные ресурсы” → “Гипервизоры”. Отключите выбранный узел (кнопка “Отключить службу”). ВМ при таком состоянии продолжают работать на узле, а новые ВМ не могут быть запущены.
На рисунке ниже показан пример с возможностью отключения.

Рисунок 17 — Вычислительные узлы с возможностью отключения
Для отключенного узла из выпадающего списка выберите пункт “Evacuate”.
Подсистема передачи данных
В Платформе используется топология сети с плоскими VLAN, часть параметров GRE / VXLAN не поддерживается.
Просмотр сетей
openstack network listopenstack subnet pool listПросмотр настроек виртуальной сети
Для просмотра настроек виртуальной сети могут использоваться следующие интерфейсы портала самообслуживания или OpenStack CLI.
Для просмотра настроек виртуальной сети в Портале самообслуживания необходимо выполнить следующие действия:
Перейдите в раздел Проект → Сети. Будет отображен список сетей, к которым имеет доступ данный проект.

Рисунок 18 — Список сетей проекта
Перейдите в карточку виртуальной сети щелчком мыши по ее названию. Вид раздела настроек виртуальной сети представлен на рисунке ниже.

Рисунок 19 — Отображение настроек виртуальной сети
Для просмотра виртуальной сети с помощью клиента Openstack CLI необходимо подключиться по протоколу SSHv2 к управляющему узлу control1 и выполнить следующую команду в контейнере kolla_toolbox:
openstack network show <имя_виртуальной_сети>
Для просмотра свойств подсетей (subnet) с помощью клиента Openstack CLI необходимо выполнить команду в контейнере kolla_toolbox:
openstack subnet show <имя_subnet>
Создание виртуальной сети и соответствующей ей подсети
Для создания сети используется команда openstack network create. Полный синтаксис команды:
openstack network create
[--share | --no-share]
[--enable | --disable]
[--project <project>]
[--description <description>]
[--mtu <mtu>]
[--project-domain <project-domain>]
[--availability-zone-hint <availability-zone>]
[--enable-port-security | --disable-port-security]
[--external | --internal]
[--default | --no-default]
[--qos-policy <qos-policy>]
[--transparent-vlan | --no-transparent-vlan]
[--provider-network-type <provider-network-type>]
[--provider-physical-network <provider-physical-network>]
[--provider-segment <provider-segment>]
[--dns-domain <dns-domain>]
[--tag <tag> | --no-tag]
--subnet <subnet>
<name>
где:
–share — сеть доступна другим проектам;
–no-share — сеть недоступна другим проектам;
–enable — включить сеть;
–disable — отключить сеть;
–project — проект владельца сети (наименование или ID);
–description — описание сети;
–mtu — установить указанный MTU;
–project-domain <project-domain> — домен проекта (наименование или ID). Опция используется в случае конфликтов между названиями проектов;
–availability-zone-hint <availability-zone> — зона доступности, в которой необхоодимо создать сеть;
–enable-port-security — включить защиту порта по умолчанию для портов, созданных в этой сети (опция по умолчанию);
–disable-port-security — отключить защиту порта по умолчанию для портов, созданных в этой сети;
–external — признак внешней сети;
–internal — признак внутренней сети;
–default — признак использования сети в качестве внешней по умолчанию;
–no-default — не использовать сеть в качестве внешней по умолчанию;
–qos-policy <qos-policy> — политика QoS для подключения к этой сети (имя или идентификатор);
–transparent-vlan — сделать сеть VLAN прозрачной;
–no-transparent-vlan — не делать сеть VLAN прозрачной;
–provider-network-type <provider-network-type> — физический механизм реализации виртуальной сети. Например: flat, geneve, gre, local, vlan, vxlan;
–provider-physical-network <provider-physical-network> — имя физической сети, в которой реализована виртуальная сеть;
–provider-segment <provider-segment> — VLAN ID для сетей VLAN или Tunnel ID для сетей GENEVE / GRE / VXLAN;
–dns-domain <dns-domain> — установить DNS-домен для этой сети;
–tag <tag> — добавить тег к сети. Может использоваться несколько раз для указания нескольких тегов;
–no-tag — нет тегов, связанных с сетью;
–subnet <subnet> — подсеть IPv4 для фиксированных IP-адресов (в нотации CIDR);
<name> — наименование создаваемой сети.
Создание подсети
Для создания подсети используется команда openstack subnet crate. Полный синтаксис команды:
openstack subnet create
[--project <project>]
[--project-domain <project-domain>]
[--subnet-pool <subnet-pool>]
[--prefix-length <prefix-length>]
[--subnet-range <subnet-range>]
[--dhcp | --no-dhcp]
[--dns-publish-fixed-ip | --no-dns-publish-fixed-ip]
[--gateway <gateway>]
[--ip-version {4,6}]
[--network-segment <network-segment>]
--network <network>
[--description <description>]
[--allocation-pool start=<ip-address>,end=<ip-address>]
[--dns-nameserver <dns-nameserver>]
[--host-route destination=<subnet>,gateway=<ip-address>]
[--service-type <service-type>]
[--tag <tag> | --no-tag]
<name>
где:
–project <project> — проект владельца (наименование или ID);
–project-domain <project-domain> — домен проекта (наименование или ID). Опция используется в случае конфликтов между названиями проектов;
–subnet-pool <subnet-pool> — пул адресов, из которого эта подсеть получит CIDR (наименование или идентификатор);
–prefix-length <prefix-length> — длина префикса для выделения подсети из пула подсетей;
–subnet-range <subnet-range> — диапазон подсети в нотации CIDR (требуется, если –subnet-pool не указан, в противном случае — необязательный);
–dhcp — разрешить DHCP (по умолчанию);
–no-dhcp — запретить DHCP;
–dns-publish-fixed-ip — включить публикацию фиксированных IP-адресов в DNS;
–no-dns-publish-fixed-ip — отключить публикацию фиксированных IP-адресов в DNS;
–gateway <gateway> — шлюз подсети. Доступны три варианта:
<ip-address> — конкретный IP-адрес для использования в качестве шлюза — например, –gateway 192.168.9.1,;
‘auto’ — адрес шлюза должен автоматически выбираться из самой подсети — например, –gateway auto;
‘none’ — подсеть не использует шлюз — например, –gateway none.
–ip-version <IP_VERSION> — версия IP (значение по умолчанию — 4). Версия 6 не доступна в Платформе;
–network-segment <network-segment> — сегмент сети, который нужно связать с этой подсетью (наименование или ID);
–network <network> — сеть, к которой принадлежит эта подсеть (наименование или ID);
–description <description> — описание подсети;
–allocation-pool start=<ip-address>,end=<ip-address> — IP-адреса пула распределения для этой подсети — например, start = 192.168.199.2, end = 192.168.199.254. Можно использовать несколько раз для добавления нескольких пулов;
–dns-nameserver <dns-nameserver> — DNS-сервер для этой подсети. Можно использовать несколько раз для указания нескольких DNS;
–host-route destination=<subnet>,gateway=<ip-address> — дополнительный маршрут для этой подсети — например, destination=10.10.0.0/16,gateway=192.168.71.254. Можно использовать несколько раз для добавления нескольких маршрутов;
–service-type <service-type> — тип сервиса для подсети — например, network:floatingip_agent_gateway. Можно использовать несколько раз для указания нескольких типов сервиса;
–tag <tag> — теги подсети. Можно использовать несколько раз для добавления нескольких тегов;
–no-tag — не ассоциировать теги с этой подсетью;
<name> — наименование подсети.
Изменение параметров сети
Изменение параметров сети выполняется командой network set. Полный синтаксис команды:
openstack network set
[--name <name>]
[--enable | --disable]
[--share | --no-share]
[--description <description]
[--mtu <mtu]
[--enable-port-security | --disable-port-security]
[--external | --internal]
[--default | --no-default]
[--qos-policy <qos-policy> | --no-qos-policy]
[--tag <tag>]
[--no-tag]
[--provider-network-type <provider-network-type>]
[--provider-physical-network <provider-physical-network>]
[--provider-segment <provider-segment>]
[--dns-domain <dns-domain>]
<network>
где:
–name <name> — установить наименование сети;
–enable — включить сеть;
–disable — выключить сеть;
–share — сделать доступной для других проектов;
–no-share — сделать недоступной для других проектов;
–description <description> — описание сети;
–mtu <mtu> — установить MTU;
–enable-port-security — включить защиту порта в этой сети;
–disable-port-security — выключить защиту порта в этой сети;
–external — установить сеть как внешнюю;
–internal — установить сеть как внутреннюю;
–default — установить эту сеть как внешнюю по умолчанию;
–no-default — не использовать эту сеть как внешнюю по умолчанию;
–qos-policy <qos-policy> — политика QoS для подключения к этой сети (наименование политики или ID);
–no-qos-policy — удалить политику QoS для подключения к этой сети;
–tag <tag> — теги сети. Можно использовать несколько раз для добавления нескольких тегов;
–no-tag — очистить теги сети. Указывается как –tag, так и –no-tag, чтобы перезаписать текущие теги;
–provider-network-type <provider-network-type> — физический механизм реализации виртуальной сети. Например: flat, geneve, gre, local, vlan, vxlan;
–provider-physical-network — наименование физической сети, в которой реализована виртуальная сеть;
–provider-segment <provider-segment> — VLAN ID для сетей VLAN или Tunnel ID для сетей GENEVE / GRE / VXLAN;
–dns-domain <dns-domain> — установить DNS-домен для этой сети;
network — изменяемая сеть (имя или ID).
Изменение параметров подсети
Изменение параметров подсети выполняется командой subnet set. Полный синтаксис команды:
openstack subnet set
[--name <name>]
[--dhcp | --no-dhcp]
[--dns-publish-fixed-ip | --no-dns-publish-fixed-ip]
[--gateway <gateway>]
[--network-segment <network-segment>]
[--description <description>]
[--tag <tag>]
[--no-tag]
[--allocation-pool start=<ip-address>,end=<ip-address>]
[--no-allocation-pool]
[--dns-nameserver <dns-nameserver>]
[--no-dns-nameservers]
[--host-route destination=<subnet>,gateway=<ip-address>]
[--no-host-route]
[--service-type <service-type>]
<subnet>
где:
–name <name> — установить имя подсети;
–dhcp — включить DHCP;
–no-dhcp — выключить DHCP;
–dns-publish-fixed-ip — включить публикацию фиксированных IP-адресов в DNS;
–no-dns-publish-fixed-ip — отключить публикацию фиксированных IP-адресов в DNS;
–gateway <gateway> — шлюз подсети. Доступны три варианта:
<ip-address> — конкретный IP-адрес для использования в качестве шлюза — например, –gateway 192.168.9.1,;
‘auto’ — адрес шлюза должен автоматически выбираться из самой подсети — например, –gateway auto;
‘none’ — подсеть не использует шлюз — например, –gateway none.
–network-segment <network-segment> — сегмент сети, который нужно связать с этой подсетью (имя или ID). Разрешается устанавливать сегмент, если текущее значение — None. Сеть также должна иметь только один сегмент, и только одна подсеть может существовать в сети;
–description <description> — установить описание подсети;
–tag <tag> — теги подсети. Можно использовать несколько раз для добавления нескольких тегов;
–no-tag — очистить теги подсети. Указывается как –tag, так и –no-tag, чтобы перезаписать текущие теги;
–allocation-pool start=<ip-address>,end=<ip-address> — IP-адреса пула для этой подсети — например, start = 192.168.199.2, end = 192.168.199.254. Можно указывать несколько раз для добавления нескольких пулов адресов;
–no-allocation-pool — удалить пулы из этой подсети. Указывается как –allocation-pool, так и –no-allocation-pool, чтобы перезаписать информацию о текущем пуле;
–dns-nameserver <dns-nameserver> — DNS-сервер для этой подсети. Можно использовать несколько раз для указания нескольких DNS-серверов;
–no-dns-nameservers — удалить информацию о DNS-серверах в этой подсети. Необходимо использовать –no-dns-nameserver и –dns-nameserver, чтобы перезаписать информацию о DNS-серверах;
–host-route destination=<subnet>,gateway=<ip-address> — – дополнительный маршрут для этой подсети — например, destination=10.10.0.0/16,gateway=192.168.71.254. Можно использовать несколько раз для добавления нескольких маршрутов;
–no-host-route — очистить информацию о маршрутах для этой подсети. Необходимо использовать -no-host-route и –host-route, чтобы перезаписать информацию о маршрутах;
–service-type <service-type> — тип сервиса для подсети — например, network:floatingip_agent_gateway. Можно использовать несколько раз для указания нескольких типов сервиса;
subnet — изменяемая подсеть (имя или ID).
Создание балансировщика нагрузки
Балансировщики проекта отображаются при переходе в левом меню в раздел Сеть → Балансировщики нагрузки.

Рисунок 20 — Список балансировщиков проекта
Для запуска мастера создания балансировщика нажмите кнопку “Создать балансировщик нагрузки”.
В окне мастера создания балансировщика укажите имя балансировщика, выберите сеть.

Рисунок 21 — Создание балансировщика
Добавьте информацию о слушателе — заполните поля “Имя”, “Протокол” и “Порт” (см. рисунок ниже).

Рисунок 22 — Заполнение информации о слушателе
Далее необходимо заполнить информацию о пуле (см. рисунок ниже).

Рисунок 23 — Заполнение информации о пуле
В настоящий момент балансировщик поддерживает три основных алгоритма балансировки:
LEAST_CONNECTIONS. Учитывает количество подключений, поддерживаемых серверами в текущий момент времени. Каждый следующий запрос передается серверу с наименьшим количеством активных подключений.
ROUND_ROBIN. Представляет собой перебор по кругу: первый запрос передается первому серверу, затем следующий запрос передается второму — и так до достижения последнего сервера, а затем все начинается сначала.
SOURCE_IP. В этом методе сервер, обрабатывающий запрос, выбирается произвольным образом и закрепляется (на сессию, в cookies) за конкретным источником запроса.
Далее укажите ВМ для балансировки. Этот шаг необязательный, и его можно выполнить после создания балансировщика (см. рисунок ниже).

Рисунок 24 — Добавление ВМ балансироки
Настройте параметры интервалов проверки доступности (см. рисунок ниже).

Рисунок 25 — Добавление правила. Параметры интервалов проверки доступности
После указания всех параметров балансировщика нажмите кнопку “Создать балансировщик нагрузки” и дождитесь завершения операции.
Подсистема хранения секретов Vault
Подсистема обычно является часть платформы, располагается на LCM-узле и находится по адресу https://netbox.<domain_name>.
Вся чувствительная информация должна храниться в этой системе.
Основной файл с секретами passwords_yml должен быть расположен в такой структуре: deployments/itkey/<prod\stage><region>/passwords_yml.
Структура может быть произвольной. Привязаться к существующей можно, изменив соответствующие CI/CD переменные в gitlab.domain_name для репозитория с файлами конфигурации, относящемуся к региону, например: https://<gitlab.domain_name>/project_k/deployments/stage1 → открыть → Settings → CI/CD → Variables:
vault_addr — адрес Vault (https://FQDN);
vault_engine — путь к хранилищу (secret store v2);
vault_method — jwt или password;
vault_password — заполните, если используется пароль для доступа к Vault;
vault_prefix — путь до passwords_yml региона (не включительно), например, deployments/itkey/prod/region1;
vault_role — itkey_deployments (не менять);
vault_username — укажите имя пользователя для доступа в Vault в случае использования парольной аутентификации;
В случае перезапуска контейнера Vault или перезапуска LCM сервера Vault необходимо разблокировать unseal-ключом, полученным при установке и сохраненном в надежном месте, сделать это можно так:
docker exec -it vault vault operator unseal
Система запросит ключ, который требуется ввести.
Мониторинг
Описание работы с OpenSearch, панели (OpenSearch Dashboards) и запросы
OpenSearch — инструмент для поиска и анализа данных в документах с открытым исходным кодом. Разработанный на основе Elasticsearch, OpenSearch предоставляет эффективное хранилище и обработку данных, а также масштабируемую архитектуру.
Создание пользовательских панелей с использованием различных виджетов и визуализаций
Процесс создания дашборда включает следующие этапы:
Выбор источника данных: происходит определение источника данных из OpenSearch для визуализации.
Добавление визуализаций: выбор и настройка виджетов и визуализаций для отображения данных (см. рисунок 26).
Конфигурация фильтров: применение фильтров для уточнения отображаемых данных (см. рисунок 27).
Определение компоновки: размещение визуализаций на дашборде с учетом их взаимодействия (см. рисунок 28).
Сохранение и публикация: сохранение созданного дашборда и возможность его публикации для общего доступа.
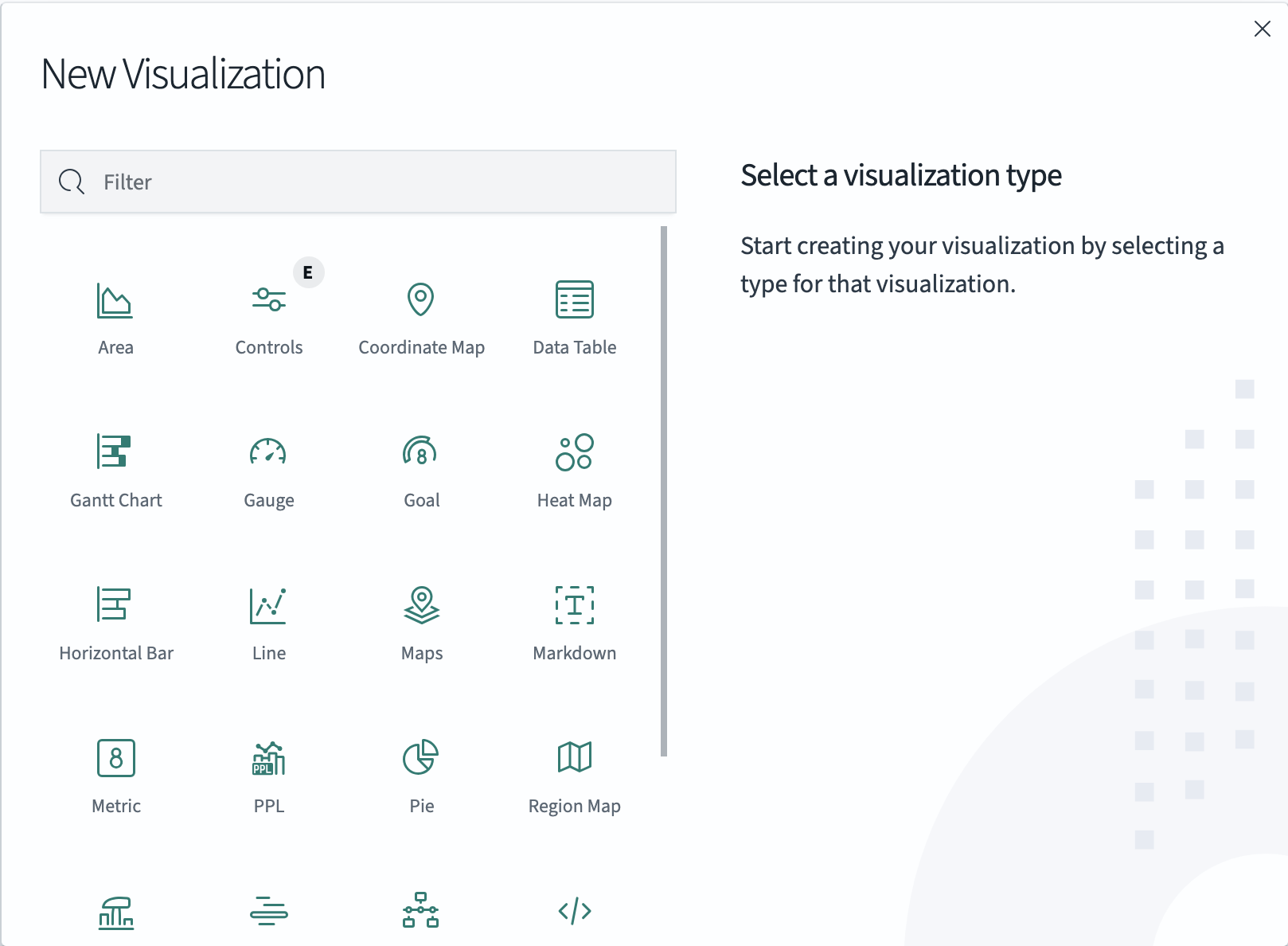
Рисунок 26 — Создание пользовательской панели. Выбор визуализации
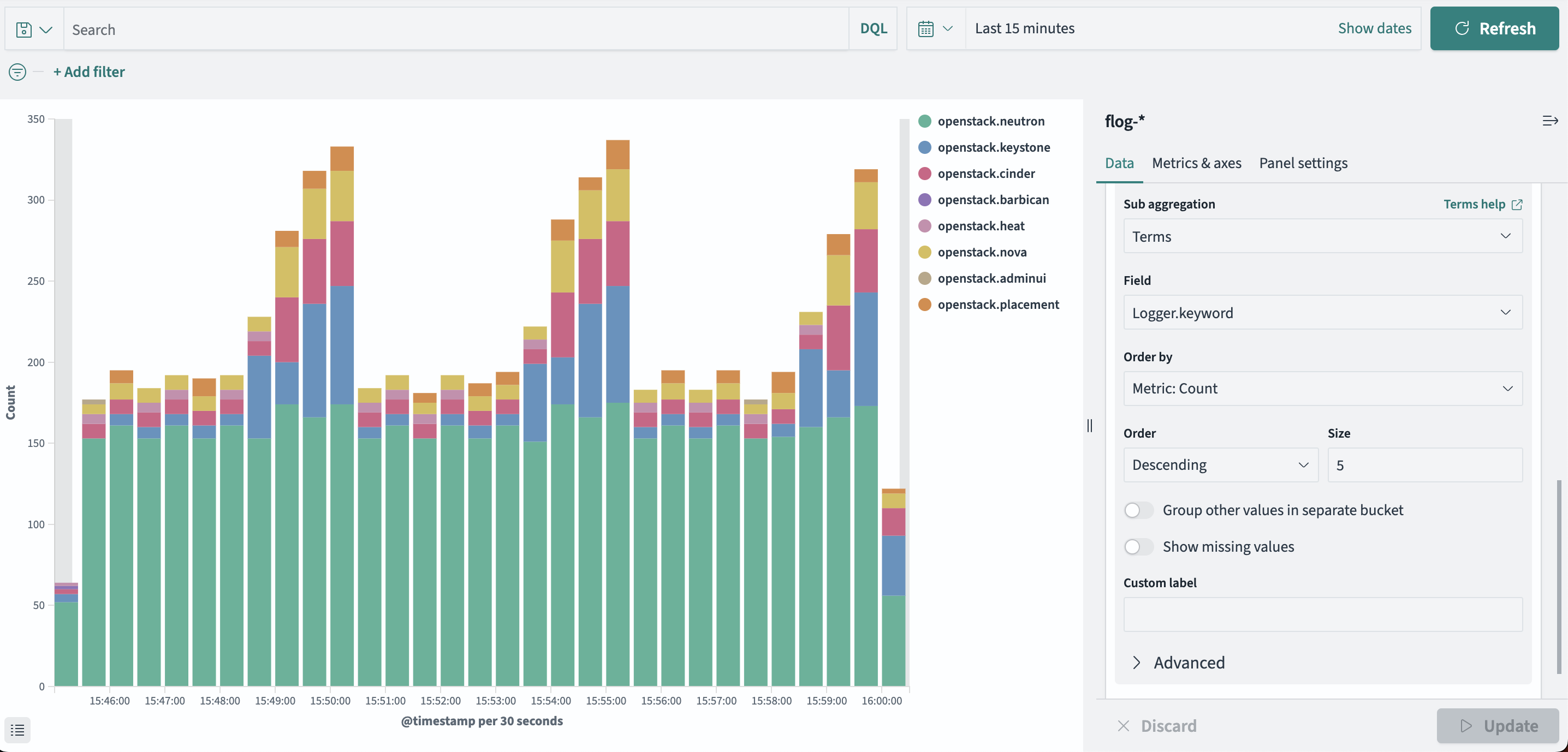
Рисунок 27 — Создание пользовательской панели. Применение фильтров
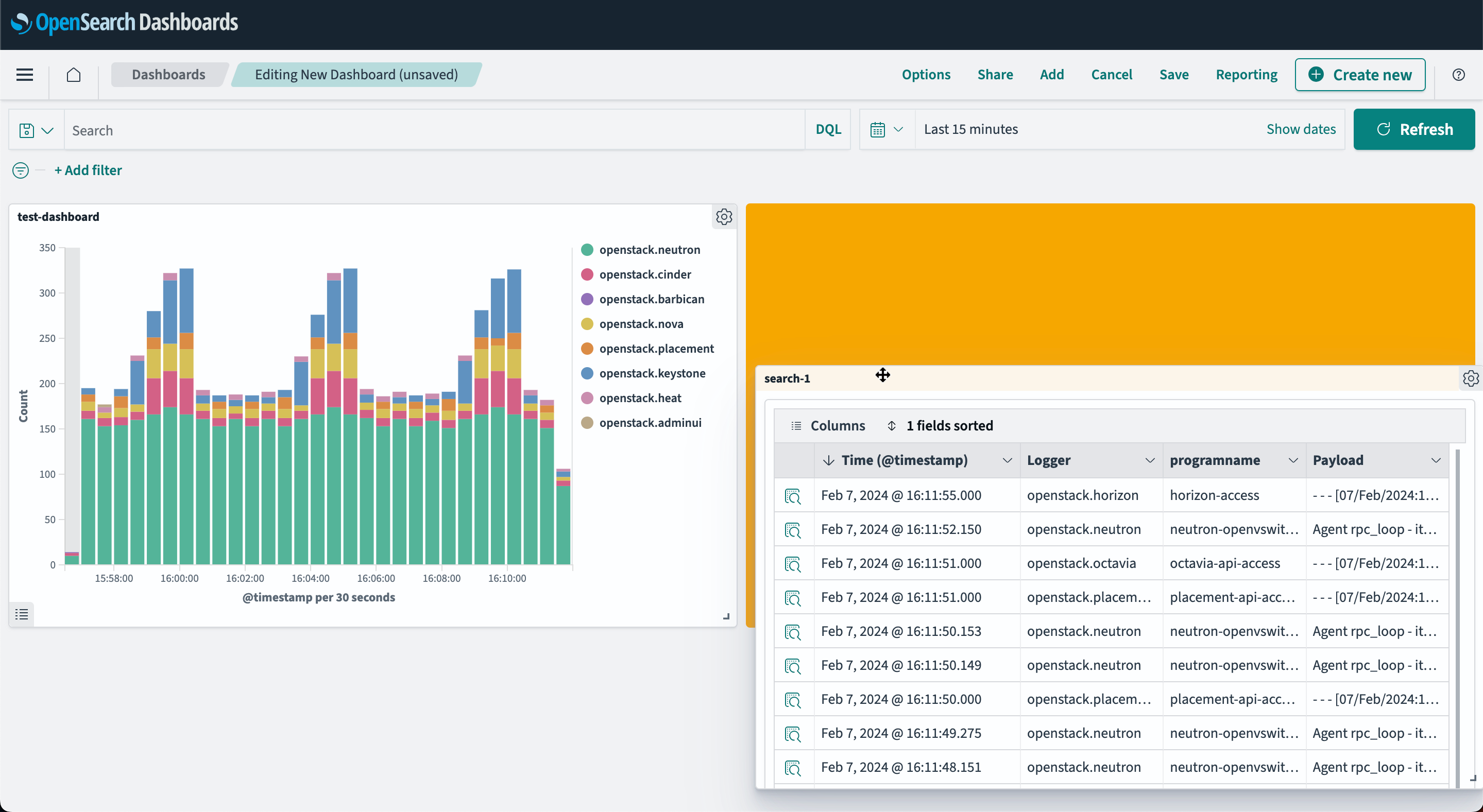
Рисунок 28 — Создание пользовательской панеи. Размещение визуализации
Подробнее о работе с OpenSearch Dashboards см. в документации OpenSearch Dashboards.
Добавление нового output для сборщика логов
Если требуется сбор логов в дополнительный output, необходимо выполнить следующие действия:
В репозитории региона в директории
config/fluentd/output(создать при отсутствии) создайте (или отредактируйте при наличии) файл03-opensearch.conf.
Содержание 03-opensearch.conf:
<match **>
@type copy
<store>
@type opensearch
hosts http://{{ opensearch_address }}:{{ opensearch_port }},https://адрес_нового_сборщика:порт_нового_сборщика
{% if fluentd_opensearch_path != '' %}
path {{ fluentd_opensearch_path }}
{% endif %}
{% if fluentd_opensearch_scheme == 'https' %}
ssl_version {{ fluentd_opensearch_ssl_version }}
ssl_verify {{ fluentd_opensearch_ssl_verify }}
{% if fluentd_opensearch_cacert | length > 0 %}
ca_file {{ fluentd_opensearch_cacert }}
{% endif %}
{% endif %}
{% if fluentd_opensearch_user != '' and fluentd_opensearch_password != ''%}
user {{ fluentd_opensearch_user }}
password {{ fluentd_opensearch_password }}
{% endif %}
logstash_format true
logstash_prefix {{ opensearch_log_index_prefix }}
reconnect_on_error true
reload_connections false
reload_on_failure true
request_timeout {{ fluentd_opensearch_request_timeout }}
suppress_type_name true
ssl_verify false
<buffer>
@type file
path /var/lib/fluentd/data/opensearch.buffer/openstack.*
flush_interval 15s
chunk_limit_size 10M
</buffer>
</store>
</match>
Далее в интерфейсе Gitlab в репозитории региона запустите выполнение пайплайна с тегом
commonи лимитом на мастер-узлы:`-t common --limit control`
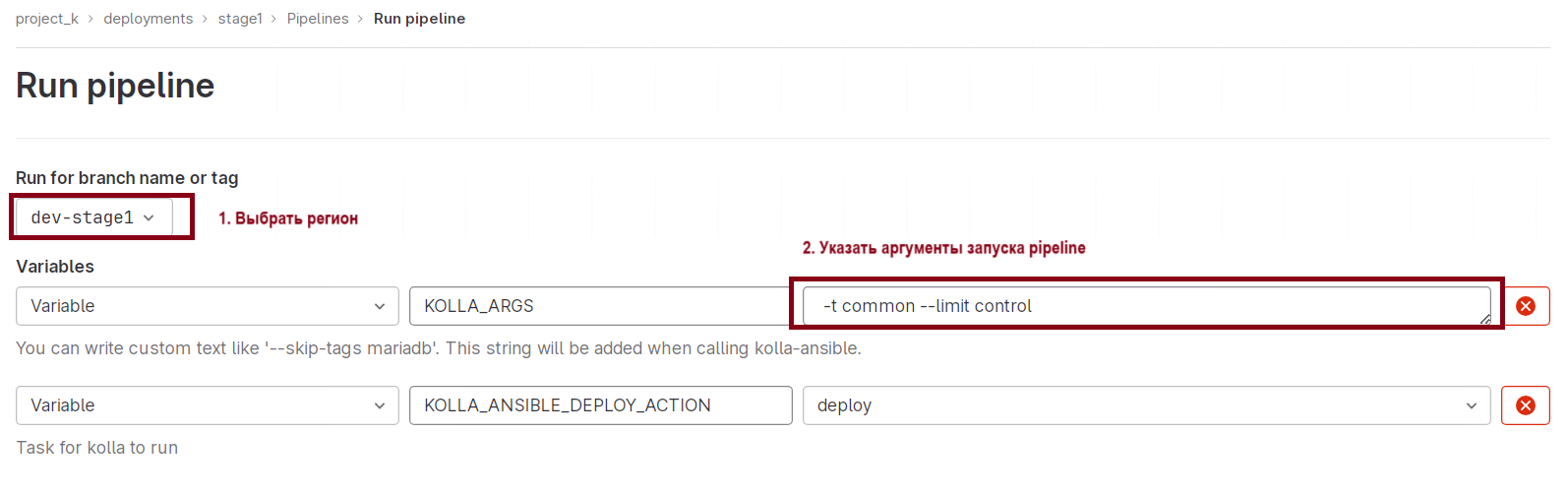
Рисунок 29 — Запуск пайплайна с нужным тегом
Нажмите “Run Pipeline”.
Создание шаблона индексов в OpenSearch
https://opensearch.<domain_name>.Нажмите кнопку “Create index patern”.
В появившемся окне в поле “index patern name” укажите flog* и нажмите “Next Step”.
Далее в поле “Time field” выберите из выпадающего списка @timestamp и нажмите “Create index pattern”.
Настройка глубины хранения индексов в Opensearch
Данная настройка выполняется в самом OpenSearch. Для этого нужно перейти на сайт https://opensearch.<domain_name> → Index Management → Index Policies и добавить или изменить политику:
{
"policy": {
"policy_id": "Retention",
"description": "hot warm delete workflow",
"schema_version": 16,
"default_state": "hot",
"states": [
{
"name": "hot",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"replica_count": {
"number_of_replicas": 1
}
}
],
"transitions": [
{
"state_name": "warm",
"conditions": {
"min_index_age": "30d"
}
}
]
},
{
"name": "warm",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"replica_count": {
"number_of_replicas": 0
}
}
],
"transitions": [
{
"state_name": "delete",
"conditions": {
"min_index_age": "60d"
}
}
]
},
{
"name": "delete",
"actions": [
`{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"delete": {}
}
],
"transitions": []
}
],
"ism_template": [
{
"index_patterns": [
"flog-*"
],
"priority": 100,
}
]
}
}
В данной политике hot–индексы хранятся 30 дней с репликой 1 и переходят в warm.
warm–индексы хранятся 60 дней с репликой 0 и переходят в delete.
delete–индексы удаляются через 90 дней.
Просмотр состояния сервисов мониторинга Платформы
Просмотр состояния контейнеров OpenSearch (выполняется на управляющих узлах):
docker ps –f name=opensearch
Просмотр состояния контейнера Prometheus (выполняется на управляющих узлах):
docker ps –f name=prometheus
Просмотр состояния Kibana (выполняется на управляющих узлах):
docker ps –f name=kibana
Просмотр состояния fluentd (на любом сервере):
docker ps | grep fluentd
Настройка глубины хранения метрик в Prometheus
Это конфигурируемая опция. Чтобы изменить параметры глубины хранения, внесите изменения в globals.yml соответствующего региона в параметр prometheus_cmdline_extras, например:
prometheus_cmdline_extras: "--storage.tsdb.retention.time=60d --storage.tsdb.retention.size=500GB"
и запустите пайплайн в gitlab: https://<gitlab_url>/project_k/deployments/<REGION>/-/pipelines→ Run Pipeline с параметрами:
KOLLA_ANSIBLE_DEPLOY_ACTION – deploy
KOLLA_ARGS – -t prometheus
Файлы журналов компонентов Платформы
В таблице 1 представлен список служб подсистем и соответствующие им лог-файлы.
Таблица 1 — Cписок служб подсистем и соответствующие им лог-файлы
Служба |
Расположение файла |
Тип узла |
|---|---|---|
Nova |
||
nova-api |
/var/log/kolla/nova/nova-api.log |
Управляющий узел |
nova-manage |
/var/log/kolla/nova/nova-manage.log |
Управляющий узел |
placement |
/var/log/kolla/nova/placement-api.log |
Управляющий узел |
nova-conductor |
/var/log/kolla/nova/nova-conductor.log |
Управляющий узел |
nova-scheduler |
/var/log/kolla/nova/nova-scheduler.log |
Управляющий узел |
nova-consoleauth |
/var/log/kolla/nova/nova-consoleauth.log |
Управляющий узел |
nova-novncproxy |
/var/log/kolla/nova/nova-novncproxy.log |
Управляющий узел |
nova-compute |
/var/log/kolla/nova/nova-compute.log |
Вычислительный узел |
Libvirt |
/var/log/kolla/libvirt/libvirtd.log |
Вычислительный узел |
Cinder |
||
cinder-api |
/var/log/kolla/cinder/cinder-api.log |
Управляющий узел |
cinder-manage |
/var/log/kolla/cinder/cinder-manage.log |
Управляющий узел |
cinder-scheduler |
/var/log/kolla/cinder/cinder-scheduler.log |
Управляющий узел |
cinder-volume |
/var/log/kolla/cinder/cinder-volume.log |
Управляющий узел |
cinder-wsgi |
/var/log/kolla/cinder/cinder-wsgi.log |
Управляющий узел |
Glance |
||
glance-api |
/var/log/kolla/glance/glance-api.log |
Управляющий узел |
Keystone |
||
keystone |
/var/log/kolla/keystone/* |
Управляющий узел |
Neutron |
||
neutron-server |
/var/log/kolla/neutron/neutron-server.log |
Управляющий узел |
neutron-openvswitch-agent |
/var/log/kolla/neutron/neutron-openvswitch-agent.log |
Сетевой узел |
neutron-dhcp-agent |
/var/log/kolla/neutron/neutron-dhcp-agent.log |
Сетевой узел |
neutron-l3-agent |
/var/log/kolla/neutron/neutron-l3-agent.log |
Сетевой узел |
neutron-metadata-agent |
/var/log/kolla/neutron/neutron-metadata-agent.log |
Сетевой узел |
neutron-metering-agent |
/var/log/kolla/neutron/neutron-metering-agent.log |
Сетевой узел |
OpenvSwitch |
Сетевой узел Вычислительный узел |
|
Openvswitch DB |
/var/log/kolla/openvswitch/ovsdb-server.log |
Сетевой узел |
neutron-openvswitch-agent |
/var/log/kolla/neutron/neutron- openvswitch -agent.log |
Сетевой узел Вычислительный узел |
Horizon |
||
horizon |
/var/log/kolla/horizon/horizon.log |
Управляющий узел |
Heat |
||
heat-api |
/var/log/kolla/heat/heat-api.log |
Управляющий узел |
Rabbitmq |
||
rabbitmq |
/var/log/kolla/rabbitmq/* |
Управляющий узел |
Mariadb |
||
mariadb |
/var/log/kolla/mariadb/mariadb.log |
Управляющий узел |
Octavia |
||
octavia-api |
/var/log/kolla/octavia/octavia-api.log |
Управляющий узел |
octavia-housekeeping |
/var/log/kolla/octavia/octavia-housekeeping.log |
Управляющий узел |
octavia-worker |
/var/log/kolla/octavia/octavia-worker.log |
Сетевой узел |
octavia-health-manager |
/var/log/kolla/octavia/octavia-health-manager.log |
Сетевой узел |
Opensearch |
||
opensearch |
/var/log/kolla/opensearch/kolla_logging.log |
Управляющий узел |
opensearch-dashoards |
/var/log/kolla/opensearch/opensearch-dashboards.log |
Управляющий узел |
Логирование
Настройка дополнительного приемника журналов KeyStack в формате syslog
Для вывода логов в удаленный сервис системного журнала (syslog) используется fluent-plugin-remote_syslog — плагин Fluentd.
При работе с данным плагином необходимо выполнить следующие действия:
В репозитории региона https://<gitlab_url>/project_k/deployments/<region_name>/config создать файл
fluentd/output/fluent-plugin-remote_syslog.conf.Файл будет иметь следующее содержание (при этом нужно заменить значения на свои):
<match **>
@type remote_syslog
host <remote_syslog_IP_address>
port 514
protocol tcp
</match>
Где (заменить значения на свои):
match ** — регулярное выражение соответствия “всем” логам;
host <remote_syslog_IP_address> — ip-адрес (fqdn) сервиса syslog;
port 514 — порт прослушивания сервиса syslog;
protocol tcp — протокол передачи данных.
После развертывания kolla-ansible конфигурационный файл (td-agent.conf) контейнера fluentd будет содержать следующие данные:
# Outputs
# Included from conf/output/00-local.conf.j2:
# Included from /etc/kolla/config/fluentd/output/fluent-plugin-remote_syslog.conf:
<match **>
@type remote_syslog
host 10.120.120.125
port 514
protocol tcp
</match>
Пример возможной конфигурации плагина fluent-plugin-remote_syslog с секциями
<match foo.bar>
@type remote_syslog
host example.com
port 514
severity debug
program fluentd
hostname ${tag[1]}
<buffer tag>
</buffer>
<format>
@type single_value
message_key message
</format>
</match>
Основные конфигурационные параметры
name |
type |
placeholder support |
description |
|---|---|---|---|
hostname |
string |
support |
departure of log |
host |
string |
support |
syslog target host |
port |
integer (default: |
syslog target port |
|
host_with_port |
string |
support |
parameter for : style |
facility |
string (default: |
support |
syslog facility |
severity |
string (default: |
support |
syslog severity |
program |
string (default: |
support |
syslog program name |
protocol |
enum (udp, tcp) (default: |
transfer protocol |
|
tls |
bool (default: false) |
use TLS (tcp only) |
|
ca_file |
string |
ca_file path (tls mode only) |
|
verify_mode |
integer |
SSL verification mode (tls mode only) |
|
packet_size |
integer (default: |
size limitation for syslog packet |
|
timeout |
integer |
TCP transfer timeout. if value is 0, wait forever |
|
timeout_exception |
bool (default: |
if value is true, raise exception by transfer timeout |
|
keep_alive |
bool (default: |
use TCP keep alive |
|
keep_alive_idle |
integer |
set TCP keep alive idle time |
|
keep_alive_cnt |
integer |
set TCP keep alive probe count |
|
keep_alive_intvl |
integer |
set TCP keep alive probe interval |
Конфигурационные параметры для секции buffer
name |
default |
|---|---|
flush_mode |
interval |
flush_interval |
5 |
flush_thread_interval |
0.5 |
flush_thread_burst_interval |
0.5 |
Конфигурационные параметры для секции format
name |
default |
|---|---|
@type |
ltsv |
License
Copyright (c) 2014-2017 Richard Lee. Copyright (c) 2022 Daijiro Fukuda.
See LICENSE for details.
Подсистема хранения кода и запуска пайплайнов (Gitlab)
Структура репозиториев в gitlab.domain_name https://<gitlab_url>
Все репозитории хранятся в группе project_k.
Kolla ansible — репозиторий, в котором хранятся плэйбуки и роли ansible от текущего релиза. Носит информативный характер и в жизненном цикле участия не принимают.
Kolla — репозиторий с исходным кодом для сборки образов docker для компонентов Openstack. Носит информативный характер и в жизненном цикле участия не принимает.
Keystack — репозиторий, который содержит базовые файлы конфигурации со значениями параметров для сервисов, рекомендуемыми вендором.
Dib — репозиторий для сборки образов операционных систем.
Ci — репозиторий с базовыми скриптами и пайпланами, которые используются для деплойментов окружений.
Deployments — группа, которая содержит набор репозиториев для создания и управления регионами/инсталляциями Openstack, а также общие репозитории для всех площадок — baremetal, bifrost и backup.
Baremetal — репозиторий для установки и базовой настройки операционных систем на физические сервера, которые планируется добавить в инсталляцию.
Bifrost — репозиторий, который содержит код для запуска контейнера bifrost, используемого логикой baremetal.
Деплой компонентов
Для запуска деплоя какого-либо компонента запустите пайплайн из репозитория соответствующего окружения и укажите тег нужного компонента и лимит при необходимости.
Открыть страницу https://gitlab.domain_name/project_k/deployments/<REGION>/-/pipelines → Run Pipeline.
KOLLA_ANSIBLE_DEPLOY_ACTION — выберите “deploy”.
KOLLA_ARGS — укажите тег компонента, который собираемся деплоить. Например, для Cinder укажите -t cinder, а для ограничения набора серверов для обновления — --limit <server/role name>.

Рисунок 30 — Запуск пайплайна из репозитория
Деплой компонентов opensearch/drs/adminui/prometheus/grafana/ha
Для деплоя данных сервисов нужно убедиться в наличии соответствующих переменных в REGION.yml соответствующего региона https://gitlab.domain_name/project_k/deployments/<REGION>/globals.d/REGION.yml.
Если все эти переменные существуют и имеют значение “yes”, то они будут установлены при деплое региона.
enable_grafana: "yes"
enable_prometheus: "yes"
enable_prometheus_alertmanager: "yes"
enable_drs: "yes"
enable_adminui: "yes"
enable_consul: "yes"
enable_opensearch: "no"
Если какие-то переменные отсутствовали, или же у них было выставлено значение “no”, то их можно установить отдельно.
Для этого добавьте переменную со значением “yes”, если переменной не было, либо выставите это значение, если было “no” — например, enable_opensearch: “yes”.
Далее откройте страницу https://gitlab.domain_name/project_k/deployments/<REGION>/-/pipelines → Run Pipeline.
KOLLA_ANSIBLE_DEPLOY_ACTION — выберите “deploy”.
KOLLA_ARGS — укажите тег компонента, который нужно деплоить. Для Opensearch нужно указать -t opensearch.
Список тегов для компонентов opensearch/drs/adminui/prometheus/grafana/ha:
Opensearch — opensearch
Grafana — grafana
Prometheus — prometheus
DRS — drs
HA — consul
Adminui — adminui
Деплой компонентов, связанных с NEUTRON
Neutron — сетевая служба, бесконтрольный деплой которой приведет к нарушению сетевой доступности облака, поэтому выкатка этого компонента выполняется с предварительной подготовкой и нюансами.
Деплой тега neutron на сервера с ролью control — обязательно указывать лимит на 1 узел, затем после выполнения пайплайна можно указать лимит на оставшиеся 2 узла и запустить пайплайн.
Деплой тега neutron на сервера с ролью network:
Получите список L3-агентов и их идентификаторы:
openstack network agent list --agent-type l3
Выключите L3-агент на том узле, на который планируется внести изменения:
openstack network agent set --disable <l3_agent_uuid>
Подождите 5 минут.
Запустите пайлайн с тегом neutron и лимитом на тот сервер, на котором выключен L3-агент:

Рисунок 31 — Параметры запуска пайплайна
openstack network agent set --enable <l3_agent_uuid>
Подождите 30 минут, отслеживая сообщения в логах
/var/log/kolla/neutron/neutron-l3-agent.log(в логах дождаться окончания синков на сотни секунд).Повторите итерацию для каждого L3-агента (для каждого узла с ролью network).
Интеграция с LDAP
Настройка данной интеграции состоит из нескольких частей:
- Создайте домен. Для этого при помощи OpenStack CLI выполните команду создания домена:
openstack domain create ldap, где ldap — это имя добавляемого домена (оно должно быть указано также в globals и участвовать в имени файла конфигурации для Keystone). Добавьте параметры в globals и файлы конфигурации:
globals.yml соответствующего региона (в интерфейсе Horizon в выпадающем списке домены будут отображаться в той последовательности, в которой были указаны. В данном случае первым будет default, затем — ldap):
keystone_ldap_url: "ldap://LDAP_SERVER_NAME:LDAP_PORT"
horizon_keystone_multidomain: "True"
horizon_keystone_domain_choices:
Default: default
Ldap: ldap
keystone.ldap.conf соответствующего региона
https://<gtilab_url>/project_k/deployments/<regionname>/config/keystone/domains/keystone.ldap.conf(значения параметров, начинающихся с YOUR, нужно заполнить своими данными):
[identity]
driver = ldap
[ldap]
group_allow_create = False
group_allow_delete = False
group_allow_update = False
group_desc_attribute = description
group_id_attribute = cn
group_member_attribute = member
group_name_attribute = cn
group_objectclass = group
group_filter = "YOUR FILTER"
password = "{{ ldap_password }}"
query_scope = sub
suffix = "YOUR_DN_SUFFIX"
user_tree_dn = "YOUR_DN_TREE"
url = "{{ keystone_ldap_url }}"
user = YOUR_SERVICE_USER_DN
user_filter = "YOUR FILTER"
user_allow_create = False
user_allow_delete = False
user_allow_update = False
user_enabled_attribute = userAccountControl
user_enabled_default = 512
user_enabled_mask = 2
user_id_attribute = cn
user_mail_attribute = mail
user_name_attribute = sAMAccountName
user_objectclass = person
user_pass_attribute = userPassword
group_tree_dn = "YOUR_GROUP_TREE_DN"
page_size = 0
Выполните деплой тегов keystone и horizon. Подробнее о запуске деплоя см. в разделе Деплой компонентов.
Далее можно добавлять пользователей в проекты через Horizon или OpenStack CLI.
Подсистема резервного копирования
Реализовано резервное копирование данных LCM узла и баз данных для регионов Openstack.
Резервное копирование LCM осуществляется через запуск запланированного задания в gitlab из репозитория:
https://<gtilab_url>/project_k/Deployments/backup.

Рисунок 32 — Резервное копирование LCM
Кроме того, выполнить резервное копирование LCM можно, запустив скрипт backupLCM.sh (находится в директории с инсталлятором).
В результате выполнения скрипта backupLCM.sh в директории /installer/backup создается архив с именем в формате backupLCM-31-08-2022-1661925161.tar.gz. Этот файл требуется скопировать в надежное хранилище данных.
Резервное копирования баз данных регионов Openstack осуществляется через запуск запланированного задания из соответствующего региону репозитория: https://<gitlab.domain_name> project_k/Deployments//-/pipeline_schedules.

Рисунок 33 — Резервное копирование баз данных регионов Openstack
Восстановление LCM из резервной копии
Восстановление осуществляется путем запуска скрипта restoreLCM.sh.
Для запуска скрипта восстановления LCM необходимо положить резервную копию LCM с именем в формате backupLCM-31-08-2022-1661925161.tar.gz в ту же директорию рядом с ним, после чего запустить скрипт.
Восстановление базы данных регионов Openstack из резервной копии
За помощью в восстановлении баз данных регионов Openstack следует обратиться к вендору.
Подсистема хранения данных о физических серверах Netbox
Netbox — компонент в составе инсталлятора, размещенный на LCM-узле. Данный сервис включен в базовую последовательность установку продукта. Netbox предоставляет собой веб-интерфейс для хранения и внесения информации о серверах, сетевых интерфейсах и других данных, которые будут использоваться при автоматизированной установке и настройке операционной системы для серверов.
Пользовательский веб-интерфейс доступен по адресу https://netbox.<domain_name>.
Рисунок 34 — Интерфейс Netbox
Навигация по основным разделам веб-интерфейса осуществляется с помощью меню слева.
В Netbox всегда можно отследить внесенные изменения (время, автора изменений и т.д.) в разделе Change Log (Operations → Logging → Change Log).
Кроме того, можно осуществлять операции с целой группой сущностей, а не с каждой по отдельности. Для этого необходимо выделить выбранные сущности и нажать Edit Selected под таблицей с ними. Другие кнопки позволяют настроить параметры по-другому: например, переименовать или удалить.
Базовая настройка сервиса
Для базовой настройки сервиса достаточно заполнить следующие разделы: Organization, Customization, IPAM, Provisioning и Devices.
В первую очередь нужно настроить параметры в разделах Sites и Tenancy. Последовательность создания сущностей для работы с Netbox такая: сайт-группа → регион → сайт.
Tenants
Чтобы добавить тенанта, откройте разделы в следующем порядке: Organization → Tenancy → Tenant.
Пример:
Name,Group,Description
itkey,,
Site Groups
Чтобы создать сайт-группу в Netbox, откройте разделы в следующем порядке: Organization → Sites → Site Groups.
Пример:
Name,Sites,Description
Group1,1,
Region
Добавьте регион в Netbox. Откройте Organization → Sites → Regions.
Пример:
Name,Sites,Description
BELARUS,1,
Site
Чтобы определеить сайт, откройте Organization → Sites → Sites. Сайты здесь — основная сущность.
Пример:
Name,Status,Facility,Region,Group,Tenant,Description
Site1,Active,,Group1,SK,,
Custom Fields
В разделе Custom Fields можно создавать дополнительные поля и задавать набор предопределенных параметров для каждого из них. Пример таких добавочных полей — два поля: role и state.
Дополнительные поля создаются и конфигурируются в Customization → Customization → Custom Fields.
Custom Fields, необходимые для работы Gitlab.domain_name Pipelines:
Name,Content types,Label,Group name,Type,Required,Description,ID,Default,Search weight,Filter logic,UI visibility,Cloneable,Display weight,Choices,Created,Last updated
role,dcim.device,role,,Multiple selection,False,,2,,100,Loose,Read/Write,False,100,"['controller', 'compute', 'network', 'osd', 'mon', 'baremetal']",2023-06-26 11:21,2023-06-26 11:21
state,dcim.device,state,,Selection,False,,1,,100,Loose,Read/Write,False,100,"['free', 'maintenance', 'production', 'ready', 'setup', 'shred']",2023-06-26 09:43,2023-06-26 09:43
IPAM
Раздел IPAM включает настройки для модулей IPAM и содержит все, что относится к сетям. Префикс для сети создается в разделе IPAM → Prefixes → Prefixes. Затем нужно выбрать сайт и VLAN для префикса.
В этом разделе нужно заполнять все по данным заказчика:
VLAN
Prefix
Manufacturers
Чтобы определить производителей в Netbox, откройте Devices → Device Types → Manufacturers и заполните там данные, т.е. марку сервера. Если марка отсутствует, ее необходимо добавить.
Пример:
ID,Name,Device Types,Inventory Items,Platforms,Description,Slug,Tags
42,Accedian,1,0,0,,accedian,
47,Adam Hall,1,0,0,,adam-hall,
1,APC,19,0,0,,apc,
6,Arista,40,0,0,,arista,
58,Asrock,2,0,0,,asrock,
19,ATEN,2,0,0,,aten,
12,Avocent,8,0,0,,avocent,
33,Backblaze,1,0,0,,backblaze,
15,Brocade,2,0,0,,brocade,
45,Cabeus,2,0,0,,cabeus,
25,Chenbro,1,0,0,,chenbro,
2,Cisco,64,44,0,,cisco,
3,Dell,37,0,0,,dell,
17,Delta,4,0,0,,delta,
14,Dlink,2,0,0,,dlink,
24,EMC,7,0,0,,emc,
35,Extreme,1,0,0,,extreme,
43,Fiberstore,6,0,0,,fiberstore,
59,FlyghtPro,0,0,0,,flyghtpro,
46,Flyht Pro,1,0,0,,flyht-pro,
52,Furukawa,1,0,0,,furukawa,
20,Geist,2,0,0,,geist,
21,Gigabyte,7,0,0,,gigabyte,
60,Graphcore,1,0,0,,graphcore,
28,HGST,4,0,0,,hgst,
4,HP,46,0,0,,hp,
38,Huawei,2,0,0,,huawei,
44,Intel,4,0,0,,intel,
5,Juniper,11,0,0,,juniper,
40,KEMP,1,0,0,,kemp,
41,KINX,1,0,0,,kinx,
56,Lenovo,1,0,0,,lenovo,
53,Lextron,1,0,0,,lextron,
57,Mellanox,1,0,0,,MELLANOX,
49,MikroTik,1,0,0,,mikrotik,
48,NetApp,2,0,0,,netapp,
13,Nokia,1,0,0,,nokia,
29,Noname,27,0,0,,noname,
16,NSFOCUS,1,0,0,,nsfocus,
7,Opengear,2,0,0,,opengear,
22,Oracle,7,0,0,,oracle,
10,Organiser,2,0,0,,organiser,
30,Panduit,2,0,0,,panduit,
32,Patchpanel,1,0,0,,patchpanel,
54,Pure Storage,1,0,0,,pure-storage,
26,QNAP,1,0,0,,qnap,
31,Quicknet,2,0,0,,quicknet,
11,Raritan,5,0,0,,raritan,
36,Rittal,4,0,0,,rittal,
23,Riverbed,2,0,0,,riverbed,
55,SNR,1,0,0,,snr,
9,std_config,0,0,0,,std_config,
37,STS,0,0,0,,sts,
39,Sun,2,0,0,,sun,
8,Supermicro,73,0,0,,supermicro,
34,Synology,1,0,0,,synology,
50,TP-LINK,1,0,0,,tp-link,
27,Tyan,1,0,0,,tyan,
51,Unknown,1,0,0,,unknown,
18,Vertiv,2,0,0,,vertiv,
Device Role
Чтобы определить роли устройств, откройте Device Types → Device Roles и выберите, что именно нужно установить. Обычно это Server.
Пример:
Name,Devices,VMs,Color,VM Role,Description
Access Switch,0,0,#2196f3,False,
Cable management,0,0,#111111,False,
Console Server,0,0,#009688,False,
Core Switch,0,0,#2196f3,False,
Customer equipment,0,0,#e91e63,False,
DCcore,0,0,#4caf50,False,
Disk enclosure,0,0,#3f51b5,False,
Network HW,0,0,#4caf50,False,
PDU,0,0,#607d8b,False,
Patch Panel,0,0,#03a9f4,False,
Planned,0,0,#f44336,False,
Power,0,0,#ff9800,False,
Rack mount boxes,0,0,#795548,False,
Rack mounting kit,0,0,#111111,False,
Router,0,0,#9c27b0,False,
SAN,0,0,#ff9800,False,
Server,5,0,#673ab7,False,
Server enclosure,1,0,#2196f3,False,
Device Type
Нужно определить тип устройств в соответствующем разделе. Это шаблон, с которого создается новый сервер.
Ниже приведен пример для блейд-корзины DELL M1000e. Данный пример будет далее дополняться:
Device Type,Manufacturer,Part number,Height (U),Full Depth,Instances
Dell M1000e,Dell,,10,True,1
M620,Dell,,0,True,4
M830,Dell,,0,True,1
Devices
Здесь все заполняется по данным заказчика:
Device
Порты
Бонды
IP Address (rmi)
IP Address (mgmt)
IP Address (vxlan)
IP Address (strg), если требуется
Аварийные ситуации. Восстановление данных
Порядок проверки сервисов при failover
На узле, где был произведен failover, выполните команду:
docker ps -a | grep -v Up
Вывод команды должен быть либо пустым, либо содержать только пользовательские контейнеры.
Особое внимание обратить в случае присутствия контейнеров со статусом Restarting.
Проверка состояния кластера Rabbitmq
На управляющем узле, где был произведен failover, выполните команду:
docker exec -it rabbitmq rabbitmqctl cluster_status
В выводе команды должно быть три узла кластера. Все узлы должны быть как в списке nodes.disc, так и в списке running_nodes.
Пример:
docker exec -it rabbitmq rabbitmqctl cluster_status
warning: the VM is running with native name encoding of latin1 which may cause Elixir to malfunction as it expects utf8. Please ensure your locale is set to UTF-8 (which can be verified by running "locale" in your shell)
Cluster status of node rabbit@host1 ...
[{nodes,[{disc,['rabbit@host1','rabbit@host2',
'rabbit@host3']}]},
{running_nodes,['rabbit@host13','rabbit@host2',
'rabbit@host3']},
{cluster_name,<<"rabbit@host1">>},
{partitions,[]},
{alarms,[{'host3',[]},
{'rabbit@host2',[]},
{'rabbit@host1',[]}]}]
Проверка состояния кластера MariaDB
Зайдите vault в хранилище секретов соответствующего региона и в passwords_yml найдите “database_password”.
После этого на управляющем узле, пережившем failover, выполните:
mysql -uroot -pPASSWORD -s -s --execute="SHOW GLOBAL STATUS LIKE 'wsrep_local_state_comment';"
где PASSWORD — пароль, прочитанный из Vault.
Пример:
ssh control1
mysql -uroot -pPassW0rd -s -s --execute="SHOW GLOBAL STATUS LIKE 'wsrep_local_state_comment';"
wsrep_local_state_comment Synced
Состояние узла MariaDB должно быть “Synced”.
На этом же узле необходимо проверить количество активных узлов в кластере MariaDB:
Пример:
mysql -uroot -pPassW0rd -s -s --execute="SHOW GLOBAL STATUS LIKE 'wsrep_cluster_size';"
wsrep_cluster_size 3
В кластере Wsrep должно быть 3 активных узла.
Проверка вспомогательных компонентов мониторинга и логирования
На узле, пережившем failover, выполните:
docker ps -a | egrep 'opensearch|prometheus|fulentd|grafana'
Все контейнеры должны быть в запущенном (“Up”) состоянии.
Проверьте журналы сервисов по пути /var/log/kolla/<service.name>/*.log.
Получить список состояний компонентов сервиса nova в OpenStack
openstack compute service list | grep $(HOSTNAME)
где $(HOSTNAME) — имя целевого узла, пережившего failover.
Вывод должен показать состояние всех компонентов nova на узле, пережившем failover как “Up”.
Пример:
openstack compute service list | grep control1
| 3 | nova-conductor | control1 | internal | enabled | up | 2023-08-08T13:38:00.000000 |
| 33 | nova-scheduler | control1 | internal | enabled | up | 2023-08-08T13:38:03.000000 |
| 42 | nova-consoleauth | control1 | internal | enabled | up | 2023-08-08T13:37:57.000000 |
Получите список состояний компонентов сервиса Cinder в OpenStack:
openstack volume service list | grep $(HOSTNAME)
где $(HOSTNAME) — имя целевого узла.
Вывод должен показать состояние всех компонентов Cinder на узле, пережившем failover как “Up”.
Пример:
openstack volume service list | grep control1
| cinder-scheduler | control1 | nova | enabled | up | 2023-08-08T13:38:25.000000 |
| cinder-backup | control1 | nova | enabled | up | 2023-08-08T13:38:27.000000 |
Проверка журналов компонентов neutron на предмет актуальных ошибок
ls -t /var/log/kolla/neutron/ | egrep -v 'log..' | grep neutron | xargs -l1 -I {} tail -n 200 /var/log/kolla/neutron/{} | grep -i error
Вывод данной команды должен быть пустым.
Далее нужно зайти по ssh на любой узел с Openstack клиентом и, используя файл admin-openrc.sh, обратиться к API OpenStack, чтобы получить статус компонентов сервиса neutron.
Пример:
openstack network agent list | grep network1
| 02480c02-1827-4007-b31a-08c4cb599826 | Metadata agent | network1 | None | True | UP | neutron-metadata-agent |
| 67dd92dc-465e-4c28-a52d-9e76b85f66bb | Open vSwitch agent | network1 | None | True | UP | neutron-openvswitch-agent |
| a0411328-04d9-46b3-a0a2-0c4e23b8eb06 | L3 agent | network1 | nova | True | UP | neutron-l3-agent |
| bf2b46eb-74a5-40b6-bc40-e0e6fb035dd4 | DHCP agent | network1 | nova | True | UP | neutron-dhcp-agent |
Failover одного управляющего узла
На сервере, пережившем failover, нужно проверить журналы Keystone и MariaDB:
grep -P -ri '(error|trace|\=5\d{2})' /var/log/kolla/keystone/\*.log
grep -P -ri '(error|trace|\=5\d{2})' /var/log/kolla/mariadb/\*.log
В журналах не должно быть записей 5хх, Traceback, Error.
Если ошибки 5хх, Traceback, Error встречаются только в Keystone — перезапустите контейнеры Keystone:
docker restart keystone
При возникновении проблем в MariaDB требуется понять и устранить причину в логах.
Failover двух управляющих узлов
Если управляющие узлы выключались штатно, то нужно запомнить последовательность выключения серверов и включить их в обратной последовательности с задержкой в 5 минут.
Обычно 5 мминут достаточно, чтобы узлы galera добавились в кластер и синхронизировали свое состояние.
При этом крайне желательно после загрузки сервера (в данном примере — controller1) выполнить проверку статуса MariaDB.
Пример:
ssh controller2
mysql -uroot -pPassW0rd -s -s --execute="SHOW GLOBAL STATUS LIKE 'wsrep_local_state_comment';"
wsrep_local_state_comment Synced
ssh controller3
mysql -uroot -pPassW0rd -s -s --execute="SHOW GLOBAL STATUS LIKE 'wsrep_local_state_comment';"
wsrep_local_state_comment Synced
Failover всех управляющих узлов
Восстановите Galera cluster.
Откройте страницу
https://<LCM_URL>/project_k/deployments/<REGION>/-/pipelines→ Run Pipeline.
KOLLA_ANSIBLE_DEPLOY_ACTION – mariadb_recovery
Дождитесь выполнения пайплайна и убедитесь, что работа сервисов восстановлена.
Перезапустите все контейнеры, кроме MariaDB и Rabbitmq.
Перезапустите контейнеры Openstack на узлах Compute.
Failover вычислительного узла
Проверьте состояние контейнеров nova_compute на вычислительном узле командой:
docker ps -a |grep -i nova_compute
Должно быть состояние “Up”.
Проверьте лог
/var/log/kolla/nova/nova-compute.logна отсутствие событий ERROR или Traceback. При их наличии убедитесь, что на вычислительном узле нет запущенных ВМ. Дл этого необходимо выполнить команду:
nova openstack server list --all --long | grep $(имя вычислительного узла)
Если команда ничего не возвратила, тогда следует удалить ВМ в контейнере nova_libvirt, выполнив команду:
virsh undefine ${vm_uuid}
Включите вычислительный узел с LCM-узла командой:
openstack compute service set —enable ${имя_вычислительного_узла} nova-compute
Успешное выполнение приведенного выше сценария зависит от следующих факторов:
Выход вычислительного узла из строя не связан с выходом из строя SDS (Ceph).
Образы ВМ, работавших на этом вычислительном узле, находятся в консистентном состоянии.
Образы ВМ, работавших на этом вычислительном узле, корректно эвакуировались с вычислительного узла.
Рекомендации по освоению
Openstack CLI: https://docs.openstack.org/python-openstackclient/latest/index.html
Docker: https://docs.docker.com/engine/reference/commandline/docker/.
Интеграция с LDAP: https://docs.openstack.org/keystone/pike/admin/identity-integrate-with-ldap.html
Термины и сокращения
Термины
Термин |
Определение |
|---|---|
Мониторинг платформы |
Программные решения для мониторинга общего состояния Платформы динамической инфраструктуры. |
Мониторинг сервисов |
Программные решения для мониторинга сервисов IaaS, PaaS, SaaS Платформы динамической инфраструктуры. |
Платформа |
Платформа (Платформа динамической инфраструктуры) — это автоматизированная система по предоставлению сервисов IaaS, PaaS, SaaS. |
Платформа автоматизации ИТ процессов |
Платформа автоматизации, основанная на ППО MF Service Manager. |
Платформа виртуализации |
Программное обеспечение, предоставляемое Исполнителем. |
Платформа контейнеризации |
Решение виртуализации, при котором ядро операционной системы поддерживает несколько изолированных экземпляров пространства пользователя вместо одного. Эти экземпляры (обычно называемые контейнерами или зонами) с точки зрения пользователя полностью идентичны отдельному экземпляру операционной системы. |
Сокращения
Сокращение |
Расшифровка |
|---|---|
AD |
Active Directory (Службы каталогов корпорации Microsoft для операционных систем семейства Windows Server) |
API |
Application Programming Interface (Интерфейс программирования приложений) |
CLI |
Command line interface (Интерфейс командной строки) |
FQDN |
Fully Qualified Domain Name (Полностью определенное доменное имя) |
HTTP |
HyperText Transfer Protocol (Протокол передачи гипертекста) |
HTTPS |
HyperText Transfer Protocol Secure (Расширение протокола HTTP для поддержки шифрования в целях повышения безопасности) |
IaaS |
Infrastructure as a Service (Инфраструктура как сервис) |
SaaS |
Software as a service (Программное обеспечение как услуга) |
SLA |
Service Level Agreement (Соглашение об уровне предоставления услуги) |
SDS |
Software-defined storage (Программно-определяемое хранилище) |
TTL |
Time To Live (Время жизни) |
ВМ |
Виртуальная машина |
ВУ |
Вычислительный узел |
ИБ |
Информационная безопасность |
КЕ |
Конфигурационная единица |
КСПД |
Корпоративная сеть передачи данных |
ОС |
Операционная система |
ПВР |
Подсистема вычислительных ресурсов |
ПО |
Программное обеспечение |
ППД |
Подсистема передачи данных |
ППО |
Прикладное программное обеспечение |
СПО |
Системное программное обеспечение |
СУБД |
Система управления базами данных |
СХД |
Система хранения данных |
ЦОД |
Центр обработки данных |
ЧТЗ |
Частное техническое задание |
УЗ |
Учетная запись |